ToB企服应用市场:ToB评测及商务社交产业平台
标题:
Python并行编程2构建多线程程序(下):同步机制
[打印本页]
作者:
来自云龙湖轮廓分明的月亮
时间:
2024-11-17 14:56
标题:
Python并行编程2构建多线程程序(下):同步机制
2.2 同步机制
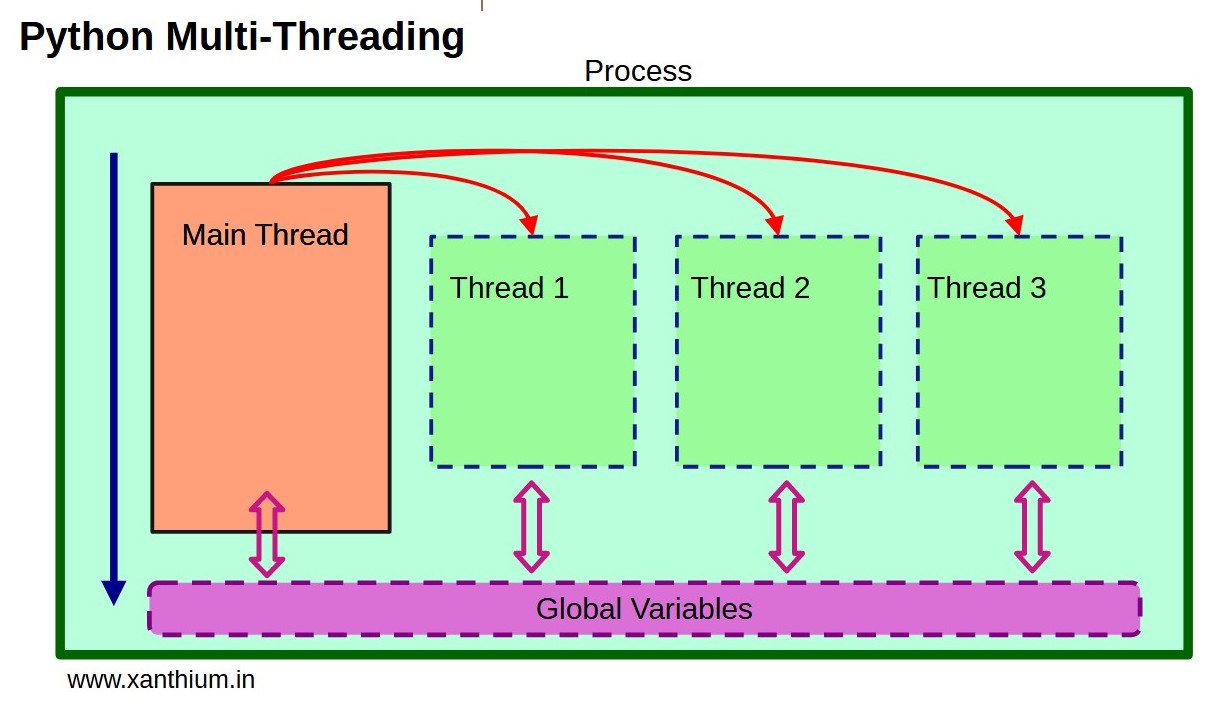
正如我们在上一节中所看到的,线程是并发实行的,因此也是同时运行的(但不是并行的)。这往往会产生不可预测的举动,如果不加以控制,可能会导致竞赛条件问题,尤其是在竞争访问共享资源时。为此,线程模块提供了一系列用于实现线程同步机制的类。这些类种类繁多,各有特点。在本章中,我们将看到所有这些类,每个类都将在一个简单的示例中实现,以便更好地理解它们的工作原理。
线程模块提供的同步对象有
锁
RLock(可重入锁 Reentrant Lock)
信号
条件
变乱
2.2.1 锁
在线程模块提供的所有类中,Lock 是同步级别最低的一个。锁根本上有两种状态:
Locked
Unlocked
并有两个方法:
acquire()
release()
这两个方法的功能是在锁定和解锁之间修改锁的状态。利用 Lock() 构造函数定义锁时,锁处于解锁状态。当一个线程调用 lock.acquire() 方法时,锁就会切换到锁定状态,并制止该线程的实行,该线程将保持搁置状态。当另一个线程调用 lock.release() 方法时,锁将返回解锁状态,等待的线程将恢复实行。
如果没有很好地管理这种同步机制,它可能会导致比不利用同步机制更混乱的同步。究竟上,可能有多个线程调用了 lock.acquire() 方法,它们都在等待至少另一个线程调用 lock.release(),将锁的状态从锁定变为解锁。在这种环境下,哪个等待线程将重新开始实行是不可预知的,在不同的实现中也会有所不同。
为了说明锁是如何工作的,让我们以两个线程分别实行不同的函数为例。我们将调用这两个函数 funcA() 和 funcB()。在第一章中,我们看到竞争线程共享历程内存。因此,在我们的示例中,我们只需利用一个共享变量,其中包含一个可供两个线程访问的整数。毗连到 funcA() 的第一个线程会将该值增加 10,而相反,毗连到 funcB() 的另一个线程会将该值淘汰 10。两个函数都将实行此利用 10 次。
因此,让我们编写下面的代码:
import threading
import time
shared_data = 0
def funcA():
global shared_data
for i in range(10):
local = shared_data
local += 10
time.sleep(1)
shared_data = local
print("Thread A wrote: %s" %shared_data)
def funcB():
global shared_data
for i in range(10):
local = shared_data
local -= 10
time.sleep(1)
shared_data = local
print("Thread B wrote: %s" %shared_data)
t1 = threading.Thread(target = funcA)
t2 = threading.Thread(target = funcB)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
这应该是一个很好的线程间并发示例。我们运行代码,得到如下结果:
Thread A wrote: 10
Thread B wrote: -10
Thread B wrote: -20
Thread A wrote: 0
Thread B wrote: -10
Thread A wrote: 10
Thread A wrote: 20
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 20
Thread B wrote: 10
Thread A wrote: 30
Thread B wrote: 20
Thread A wrote: 40
Thread B wrote: 30
Thread A wrote: 50
Thread B wrote: 20
Thread A wrote: 60
复制代码
首先,两个函数中 for 循环的迭代被分开并分别实行。在这种环境下,线程以原子方式实行每个 for 循环,而每个循环都在两个函数之间竞争。因此,在每个实行步骤中,funcA() 或 funcB() 的 for 循环中的一个会优先于另一个被实行(在 Python 中线程不能并行实行)。然而,这正是我们所盼望的多线程同时运行的举动。到现在为止,统统正常。
问题出在各步骤中共享变量的值上。实行结束时的值应该是 0,而在这次实行中,它是 100(但这是一个完全随机的值,在不同的实行中都不一样)。因此,我们碰到了竞赛环境。此外,从我们读取的数据中可以看出,这种环境并非只发生过一次,而是在短短 10 个周期内频仍发生,而且只有 2 个线程。
因此,很明显,如果我们想让这个程序正常运行,就必须利用同步机制来协调两个线程访问共享变量,以制止出现竞赛条件征象。线程模块提供的 Lock 类是最简单的例子。
然后,我们在程序开头定义一个 Lock 类实例,并在两个线程中插入对 acquire() 和 release() 方法的调用,如下代码所示:
def funcA():
global shared
for i in range(10):
lock.acquire()
shared += 10
print("Thread A wrote: %s" %shared)
lock.release()
time.sleep(1)
def funcB():
global shared
for i in range(10):
lock.acquire()
shared -= 10
print("Thread B wrote: %s" %shared)
lock.release()
time.sleep(1)
t1 = threading.Thread(target = funcA)
t2 = threading.Thread(target = funcB)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
如果这次运行代码,我们会得到大相径庭的结果:
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0
复制代码
正如我们所看到的,不再存在竞赛条件问题。每次只有一个线程以同步方式读取和修改共享变量,从而制止了错误值的产生。
2.2.2 带锁的上下文管理协议
线程模块中所有利用 acquire() 和 release() 方法的对象,如 Lock 对象,都可以通过 with 语句(见下面的注释)用于上下文管理器。
注:在 Python 中,with 语句创建了一个运行时上下文,允许在上下文管理器的控制下实行语句块。
with expression:
#code
复制代码
上下文管理器负责评估与 with (context) 相关代码块的表达式。因此,表达式必须返回一个实现上下文管理协议的对象,该协议主要由两个方法组成:
enter
() 在进入上下文时调用。
退出上下文时调用
exit
() 方法。
除此以外,with 语句的另一个优点是包含了 try ... finally 结构的功能。
如许,你就能得到可读性更强、更易于重用的代码。正是由于这些优点,标准库中的许多类都支持利用 with 语句来更换传统的结构体。
在锁的环境下,进入代码块时将调用 acquire() 方法,退出时将调用 release() 方法。
因此就有了这种形式:
import threading
import time
shared_data = 0
lock = threading.Lock()
def funcA():
global shared_data
for i in range(10):
with lock:
local = shared_data
local += 10
time.sleep(1)
shared_data = local
print("Thread A wrote: %s" %shared_data)
def funcB():
global shared_data
for i in range(10):
with lock:
local = shared_data
local -= 10
time.sleep(1)
shared_data = local
print("Thread B wrote: %s" %shared_data)
t1 = threading.Thread(target = funcA)
t2 = threading.Thread(target = funcB)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
然后,我们利用支持的上下文管理器协议重写之前的代码:
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread B wrote: -20
Thread B wrote: -30
Thread B wrote: -40
Thread B wrote: -50
Thread B wrote: -60
Thread B wrote: -70
Thread B wrote: -80
Thread A wrote: -70
Thread A wrote: -60
Thread A wrote: -50
Thread A wrote: -40
Thread A wrote: -30
Thread A wrote: -20
Thread A wrote: -10
Thread A wrote: 0
复制代码
我们可以看到,代码的可读性大大提高。如果运行这段代码,我们不会发现其举动与之前的代码有任何不同。
本章稍后将先容的线程模块中的其他对象也支持利用 with 语句的上下文管理器协议:
RLock
条件
信号
所有对象都与 Lock 一样,在同步机制中利用 acquire() 和 release() 方法。
2.2.3 另一种可能的锁同步解决方案
让我们继承分析前面的代码。正如我们所看到的,我们添加了一种同步机制,它似乎可以完全(或至少几乎)取消两个线程的并发举动。
我们创建的机制是最直观的,即在每个线程中成对地添加对 acquire() 和 release() 方法的调用,以便划分部门块。利用带语句的上下文管理器,统统都很清楚:我们在两个线程中都有两个对称的代码部门。
但我们并不必须以这种方式运行。你可以实验找到更复杂的同步条件。风险自担。究竟上,可以在代码中彼此不对称的位置,不对称地插入对 acquire() 和 release() 方法的调用,偶然在一个线程中利用 acquire(),而在另一个线程中利用 release()。如许一来,上下文管理器可辨认的代码块就丢失了,而传递的同步控制却复杂得多。在这种环境下,不但会出现竞赛条件问题,甚至还会出现死锁。此外,如果在锁状态解锁时调用 release() 方法,会导致实行错误。不外,不要悲观,做一些测试,也许同步并发解决方案是可行的。
例如,如果我们以下面的方式修改代码:
import threading
import time
shared = 0
lock = threading.Lock()
def funcA():
global shared
for i in range(10):
time.sleep(1)
shared += 10
print("Thread A wrote: %s" %shared)
lock.acquire()
def funcB():
global shared
lock.acquire()
for i in range(10):
time.sleep(1)
shared -= 10
print("Thread B wrote: %s" %shared)
lock.release()
t1 = threading.Thread(target = funcA)
t2 = threading.Thread(target = funcB)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
有很多改动。例如,funcA() 函数不再调用 release() 方法,而在每次迭代结束时调用 acquire() 方法。而在 funcB() 函数中,acquire() 方法则在实行开始时,即 for 循环之外调用。
运行修改后的代码,我们将得到如下结果:
Thread B wrote: -10
Thread A wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread B wrote: -10
Thread A wrote: 0
Thread A wrote: 10
Thread B wrote: 0
Thread B wrote: -10
Thread A wrote: 0
复制代码
我们可以看到,这次统统似乎都很顺遂。我们最终得到了一个 0 的最终共享值,并重新获得了两个线程之间的并发举动。究竟上,两个线程之间 for 循环的迭代顺序恢复了随机和并发。通过多次运行程序,我们留意到举动依然精确,纵然在这些环境下我们永久无法获得绝对的确定性。
如果我们不能确定两个线程是否交替进行,而是其中一个线程实行受阻,而另一个线程继承实行,那么我们可以(在调试阶段)在之前的代码中添加一些打印值,以确认两个线程的实行进度。在本例中,我们可以在报告各线程计数结果的字符串中添加迭代次数。如许,我们就能同时确定两个线程的实行进度:
import threading
import time
shared = 0
lock = threading.Lock()
def funcA():
global shared
for i in range(10):
time.sleep(1)
shared += 10
print("Thread A wrote: %s, %i" %(shared,i))
lock.acquire()
def funcB():
global shared
lock.acquire()
for i in range(10):
time.sleep(1)
shared -= 10
print("Thread B wrote: %s, %i" %(shared,i))
lock.release()
t1 = threading.Thread(target = funcA)
t2 = threading.Thread(target = funcB)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
在修改代码后立即运行代码,我们会发现两个线程都在交替实行:
Thread A wrote: 10, 0
Thread B wrote: 0, 0
Thread B wrote: -10, 1
Thread A wrote: 0, 1
Thread B wrote: -10, 2
Thread A wrote: 0, 2
Thread B wrote: -10, 3
Thread A wrote: 0, 3
Thread B wrote: -10, 4
Thread A wrote: 0, 4
Thread B wrote: -10, 5
Thread A wrote: 0, 5
Thread A wrote: 10, 6
Thread B wrote: 0, 6
Thread A wrote: 10, 7
Thread B wrote: 0, 7
Thread A wrote: 10, 8
Thread B wrote: 0, 8
Thread B wrote: -10, 9
Thread A wrote: 0, 9
复制代码
2.2.4 RLock
另一个用于线程同步的类是 RLock,它是一种重入锁。该类与 Lock 类非常相似,但不同的是,它可以被同一线程多次获取。在它的内部,除了锁定-解锁状态外,还有关于所有者线程和递归级别的信息。
与锁一样,RLock 也可以通过 acquire() 方法从线程中获取。此时,RLock 变成锁定状态,调用线程成为所有者之一。同样,RLock 也可以通过调用 release() 方法来解锁。但这次与 Lock 同步机制不同的是,调用 acquire() 和 release() 方法的线程对是多个,可以嵌套在一起。调用 acquire() 方法的其他线程将被添加到所有者列表中。只有最后的 release() 方法才能解锁 RLock,并确保另一个线程可以重新启动。
举个例子,我们利用一个函数,其中有两个嵌套的 for 循环,在这两个层级中都可以访问共享变量。此外,我们还可以通过改变每个线程的实行时间来区分这三个线程,如允许以更加突出并发举动:
import threading
import time
shared = 0
rlock = threading.RLock()
def func(name, t):
global shared
for i in range(3):
rlock.acquire()
local = shared
time.sleep(t)
for j in range(2):
rlock.acquire()
local += 1
time.sleep(2)
shared = local
print("Thread %s-%s wrote: %s" %(name, j, shared))
rlock.release()
shared = local + 1
print("Thread %s wrote: %s" %(name, shared))
rlock.release()
t1 = threading.Thread(target = func,args=('A',2,))
t2 = threading.Thread(target = func,args=('B',10,))
t3 = threading.Thread(target = func,args=('C',1,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
复制代码
运行前面的代码,我们将得到如下结果:
Thread A-0 wrote: 1
Thread A-1 wrote: 2
Thread A wrote: 3
Thread A-0 wrote: 4
Thread A-1 wrote: 5
Thread A wrote: 6
Thread A-0 wrote: 7
Thread A-1 wrote: 8
Thread A wrote: 9
Thread B-0 wrote: 10
Thread B-1 wrote: 11
Thread B wrote: 12
Thread B-0 wrote: 13
Thread B-1 wrote: 14
Thread B wrote: 15
Thread B-0 wrote: 16
Thread B-1 wrote: 17
Thread B wrote: 18
Thread C-0 wrote: 19
Thread C-1 wrote: 20
Thread C wrote: 21
Thread C-0 wrote: 22
Thread C-1 wrote: 23
Thread C wrote: 24
Thread C-0 wrote: 25
Thread C-1 wrote: 26
Thread C wrote: 27
复制代码
另外,在这种环境下,与锁的环境一样,同步导致了共享变量的完善管理,但却失去了线程的并发举动。
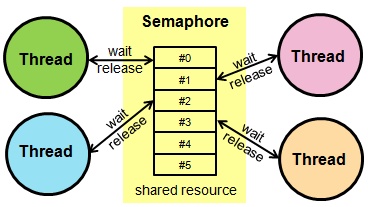
2.2.5 信号(Semaphore)
线程模块中的另一种同步机制是基于信号的同步机制。这种原始机制是盘算机科学汗青上最古老的同步形式,由 Edsger W. Dijkstra 于 1962 年发明。
其目的是同步管理同一历程中多个线程对共享资源的利用。为此,每个信号都与共享资源相关联,允许所有线程访问,直到其内部计数器的值为负为止。
信号是一个对象,它与锁类似,通过调用 acquire() 和 release() 方法来工作。其内部有一个计数器,每次调用 acquire() 方法都会递减一个单位,而每次调用 release() 方法都会递增一个单位。
因此,如果一个线程必要访问受 Semaphore 掩护的共享资源,它首先会调用 acquire() 方法。交通灯的内部计数器会淘汰一个单位。如果该值等于或大于零,则线程将访问该资源,否则将被阻塞,并等待其他线程对同一资源调用 release()。只有到那时,线程才能继承实行,访问须要的资源。
因此,非常重要的一点是,每个调用 acquire() 的线程在结束对共享资源的利用后,都要调用 release() 方法,如许其他线程也能访问资源,制止出现死锁:
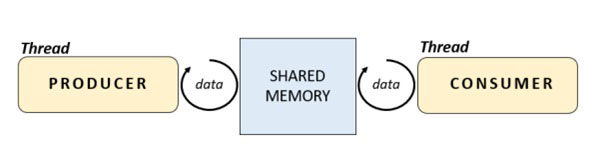
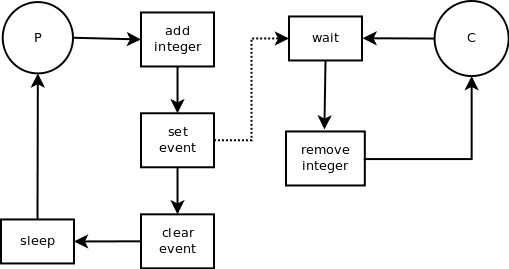
这种编程模型基于两类在数据流中起作用的对象。生产者通常通过从外部资源获取数据来生成数据,而消费者则利用生产者生成的数据。问题是,这两个对象各自独立工作,速率不同且可变。它们的数量也可能不同。例如,可以只有一个生产者和多个消费者,反之亦然。这种模型非常适合线程(也适合历程),因此在这些示例中引入这种模型是个好主意。
作为利用 Semaphore 同步的示例,我们将定义两个线程子类: 消费者(Consumer)和生产者(Producer)。在它们的 run() 方法中,我们将实行它们的代码。在生产者中,我们将实现一个 request() 函数,模仿从外部来源请求数据,并通过 time.sleep() 抽出肯定的时间。
因此,让我们编写以下代码:
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
class Consumer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def run(self):
global shared
semaphore.acquire()
print("consumer has used this: %s" %shared)
shared = 0
semaphore.release()
class Producer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def request(self):
time.sleep(1)
return random.randint(0,100)
def run(self):
global shared
semaphore.acquire()
shared = self.request()
print("producer has loaded this: %s" %shared)
semaphore.release()
t1 = Producer()
t2 = Consumer()
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
实行刚才编写的代码,我们将得到类似下面的结果:
producer has loaded this: 39
consumer has used this: 39
复制代码
由于 semaphores 的同步机制也是通过 acquire() 和 release() 方法实现的,因此 semaphores 也支持上下文管理协议。因此,我们可以将前面的代码编写如下:
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
class Consumer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def run(self):
global shared
with semaphore:
print("consumer has used this: %s" %shared)
shared = 0
class Producer(Thread):
def __init__(self):
Thread.__init__(self)
global semaphore
def request(self):
time.sleep(1)
return random.randint(0,100)
def run(self):
global shared
with semaphore:
shared = self.request()
print("producer has loaded this: %s" %shared)
t1 = Producer()
t2 = Consumer()
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
实行后会得到类似的结果。
producer has loaded this: 4
consumer has used this: 4
复制代码
在这种环境下,我们有两个线程,即生产者和消费者,它们只运行一次;也就是说,它们产生一个值,然后被斲丧掉。但是,如果我们让生产者线程产生更多的数值,让消费者线程斲丧同样多的数值,会发生什么环境呢?
我们重写代码,让每个线程实行上述利用五次:
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
count = 5
class consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global semaphore
self.count = count
def run(self):
global shared
for i in range(self.count):
semaphore.acquire()
print("consumer has used this: %s" %shared)
shared = 0
semaphore.release()
class producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global semaphore
def request(self):
time.sleep(1)
return random.randint(0,100)
def run(self):
global shared
for i in range(self.count):
semaphore.acquire()
shared = self.request()
print("producer has loaded this: %s" %shared)
semaphore.release()
t1 = producer(count)
t2 = consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
运行代码后,我们得到如下结果:
producer has loaded this: 29
producer has loaded this: 70
producer has loaded this: 10
producer has loaded this: 1
producer has loaded this: 32
consumer has used this: 32
consumer has used this: 0
consumer has used this: 0
consumer has used this: 0
consumer has used this: 0
复制代码
这肯定不是我们想要的结果。究竟上,生产者线程继承产生覆盖共享资源的值,但消费者线程被阻塞,直到生产者完成工作(五个周期)后才开始。消费者线程在生产者的五个周期结束后开始工作,只斲丧最后产生的值,而丢失前面的四个值。
此外,在这种环境下,就像锁的例子一样,用信号传递器对线程代码块进行原子管理不再适合我们的必要。我们所说的原子性是指精确性:
因此,让我们分解一下两个线程之间的 acquire() 和 release() 调用机制。首先必须访问共享资源的生产者线程会在覆盖数据前调用 acquire() 方法。而消费者线程在斲丧完共享资源后,将调用 release() 方法,释放资源:
from threading import Thread, Semaphore
import time
import random
semaphore = Semaphore(1)
shared = 1
count = 5
def request():
time.sleep(1)
return random.randint(0,100)
class consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global semaphore
self.count = count
def run(self):
global shared
for i in range(self.count):
semaphore.acquire()
print("consumer has used this: %s" %shared)
shared = 0
class producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global semaphore
def run(self):
global shared
for i in range(self.count):
shared = request()
print("producer has loaded this: %s" %shared)
semaphore.release()
t1 = producer(count)
t2 = consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
实行结果如下:
consumer has used this: 1
producer has loaded this: 33
consumer has used this: 33
producer has loaded this: 40
consumer has used this: 40
producer has loaded this: 99
consumer has used this: 99
producer has loaded this: 25
consumer has used this: 25
producer has loaded this: 20
复制代码
从结果可以看出,同步还不够完善。我们看到消费者线程和生产者线程之间的运动交替进行。但第一个访问共享资源的是消费者,因此第一个斲丧的值是起始默认值 1。而生产者在程序结束时产生的值不会被斲丧。要解决这个问题并精确调整实行顺序,只需将 Semaphore 的初始内部值设置为 0,而不是 1。
参考资料
软件测试精品书籍文档下载连续更新
https://github.com/china-testing/python-testing-examples
请点赞,谢谢!
本文涉及的python测试开辟库
谢谢点赞!
https://github.com/china-testing/python_cn_resouce
python精品书籍下载
https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
Linux精品书籍下载
https://www.cnblogs.com/testing-/p/17438558.html
https://realpython.com/python-with-statement/
https://peps.python.org/pep-0343/
https://en.wikipedia.org/wiki/Semaphore_(programming)
https://www.meccanismocomplesso.org/i-thread-in-python-threading-parte-1/
https://www.meccanismocomplesso.org/thread-in-python-lock-e-deadlock-parte-4/
https://www.meccanismocomplesso.org/thread-in-python-il-modello-producer-consumer-parte-5/
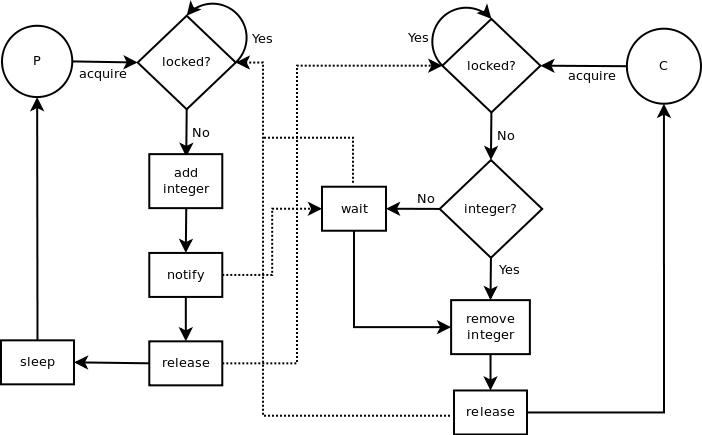
2.2.6 条件(Condition)
除了 Semaphores 之外,Condition 类也可用于线程同步。Condition 类有一个内部锁,通过 acquire() 和 release() 可以实现锁定和解锁状态。除此之外,它还有其他相关方法。wait() 方法会释放锁,但会阻塞线程,直到另一个线程调用 notify() 和 notify_all() 方法。
如果有条件变量,notify()方法只会叫醒其中一个等待条件变量的线程。而 notify_all() 方法会叫醒所有等待的线程。
让我们回到之前利用 Semaphore 的代码,这次利用 Condition 作为线程同步系统。然后,我们修改之前编写的代码,最后得到如下代码:
from threading import Thread, Condition
import time
import random
condition = Condition()
shared = 1
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global condition
self.count = count
def run(self):
global shared
for i in range(self.count):
condition.acquire()
if shared == 0:
condition.wait()
print("consumer has used this: %s" %shared)
shared = 0
condition.notify()
condition.release()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global condition
def request(self):
time.sleep(1)
return random.randint(0,100)
def run(self):
global shared
for i in range(self.count):
condition.acquire()
shared = self.request()
print("producer has loaded this: %s" %shared)
condition.wait()
if shared == 0:
condition.notify()
condition.release()
t1 = Producer(count)
t2 = Consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
如果我们运行这段代码,就会得到类似下面的结果:
producer has loaded this: 59
consumer has used this: 59
producer has loaded this: 76
consumer has used this: 76
producer has loaded this: 29
consumer has used this: 29
producer has loaded this: 15
consumer has used this: 15
producer has loaded this: 76
consumer has used this: 76
复制代码
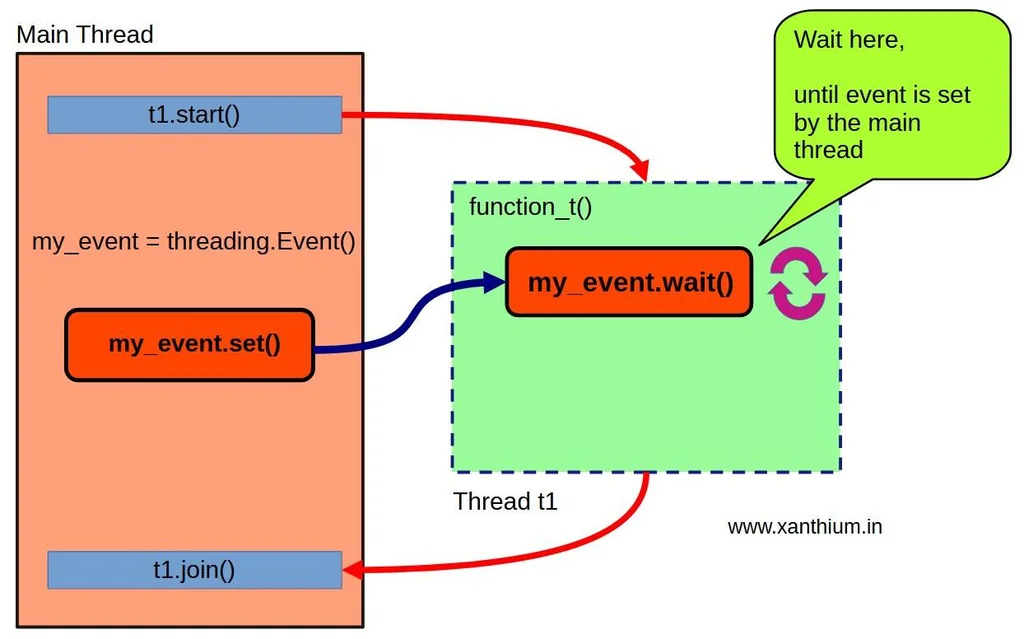
2.2.7 变乱(Event)
除了 Semaphore 和 Condition 之外,还有另一种同步机制。变乱(Event)的利用在概念上是最简单的。所有这些都可以理解为线程之间的根本通讯机制,其中一个线程向另一个等待变乱发生的线程发出信号。
变乱对象管理一个内部布尔标志。还有两个方法可以确定其值。set() 方法将标志值设置为 True,而 clear() 方法则将标志值设置为 False。False 是变乱对象创建时的默认值。还有第三个 wait() 方法会阻塞线程,直到标志变为 True。
换句话说,一个线程在实行过程中,通过调用 wait() 方法冻结,等待变乱发生后才能继承实行。在另一个线程中,当该变乱发生时,会调用 set() 方法解锁前一个线程,该线程实行其利用,然后调用 clear() 重置统统。
在生产者(Producer)和消费者(Consumer)两个线程的示例中,我们可以用基于变乱的同步机制取代之前的机制。
让我们对前面示例的代码作如下修改:
from threading import Thread, Event
import time
import random
event = Event()
shared = 1
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
global event
self.count = count
def run(self):
global shared
for i in range(self.count):
event.wait()
print("consumer has used this: %s" %shared)
shared = 0
event.clear()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
global event
def request(self):
time.sleep(1)
return random.randint(0,100)
def run(self):
global shared
for i in range(self.count):
shared = self.request()
print("producer has loaded this: %s" %shared)
event.set()
t1 = Producer(count)
t2 = Consumer(count)
t1.start()
t2.start()
t1.join()
t2.join()
复制代码
运行代码后,我们会得到类似下面的结果:
producer has loaded this: 11
consumer has used this: 11
producer has loaded this: 84
consumer has used this: 84
producer has loaded this: 78
consumer has used this: 78
producer has loaded this: 27
consumer has used this: 27
producer has loaded this: 16
consumer has used this: 16
复制代码
我们还可以看到,在这种环境下,两个线程之间的同步是完善的。
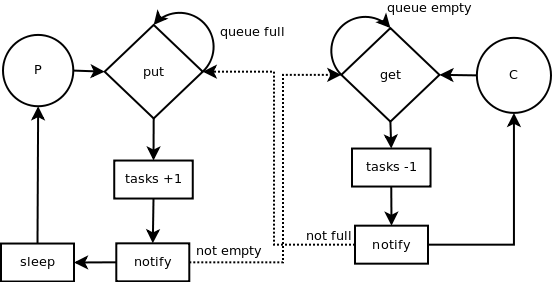
2.2.8 队列(Queue)
我们继承开辟前面的示例。到现在为止,我们只利用了一个生产者线程和一个消费者线程。但如果增加数量会怎样呢?
在这种环境下,队列(Queue)可以帮助我们。
from threading import Thread
from queue import Queue
import time
import random
queue = Queue()
shared = 1
count = 5
class Consumer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
def run(self):
global queue
for i in range(self.count):
local = queue.get()
print("consumer has used this: %s" %local)
queue.task_done()
class Producer(Thread):
def __init__(self, count):
Thread.__init__(self)
self.count = count
def request(self):
time.sleep(1)
return random.randint(0,100)
def run(self):
global queue
for i in range(self.count):
local = self.request()
queue.put(local)
print("producer has loaded this: %s" %local)
t1 = Producer(count)
t2 = Producer(count)
t3 = Consumer(count)
t4 = Consumer(count)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
复制代码
运行代码将得到以下结果:
producer has loaded this: 45
consumer has used this: 45
producer has loaded this: 6
consumer has used this: 6
producer has loaded this: 90
consumer has used this: 90
producer has loaded this: 49
consumer has used this: 49
producer has loaded this: 38
consumer has used this: 38
producer has loaded this: 40
consumer has used this: 40
producer has loaded this: 60
consumer has used this: 60
producer has loaded this: 75
consumer has used this: 75
producer has loaded this: 72
consumer has used this: 72
consumer has used this: 18
producer has loaded this: 18
复制代码
2.3 结论
在本章中,我们全面先容了线程模块提供的所有工具。我们看到了如何通过调用函数、利用子类或将线程插入 ThreadPoolExecutor 等不同方式在程序中定义一组线程。我们还研究了各种可能的线程同步机制,以及它们之间的区别。无论如何,我们已经看到了线程举动的不可预测性,以及碰到竞赛条件问题有多么轻易。在下一章中,我们将转向真正的并行编程,在 Python 中,并行编程完全用历程来表达。我们将讨论标准 Python 库提供的多历程模块。
必要记住的要点
同步方法: 当您想利用多个线程共享的内存时,这些方法是必不可少的。
过分同步: 这会抑制线程的并发举动,使它们串行实行。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4