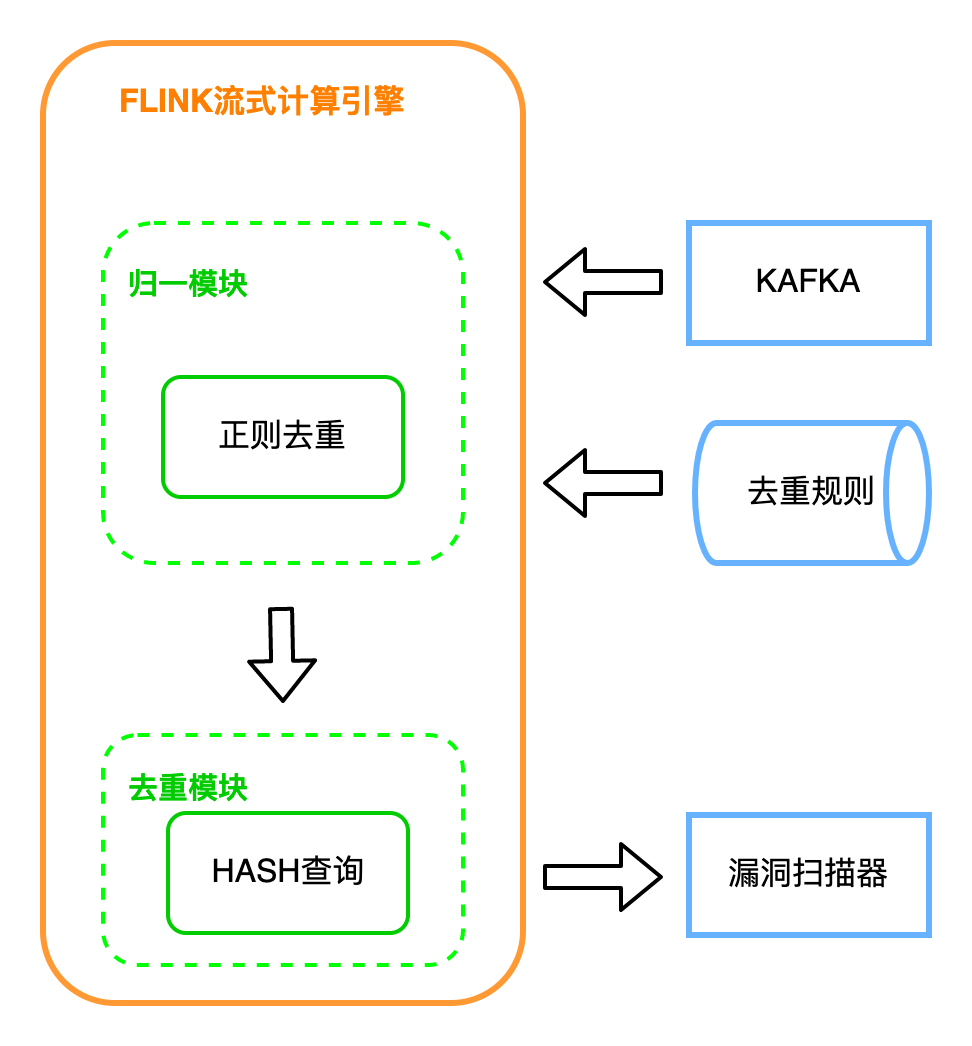
SimHash算法是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling》中提到的一种指纹生成算法,被应用在Google搜索引擎网页去重的工作之中。其实去重说起来也有些类似于搜索引擎的去重,而目前搜索引擎的去重算法都已经比较成熟了,可以搜索各种论文,找找这些去重算法。
也有很多其他优秀且性能更好的页面相似度算法
往往有很多无效访问,因为导向返回码200的40x/50x页面,导致这一部分的流量漏去重。如果页面相似度去重已经上了,这一步也可以略过,用作召回去重程序的case。(2) 排除找不到业务的流量: 镜像流量有时候会有奇怪的流量,比如对着nginx构造host等情况,需要排除掉找不到业务的流量。这部分流量即使有漏洞,漏洞找人也比较麻烦,后续无法实现全流程自动化。所以nginx无法解析的、domain没有记录的,过滤掉。再将这一部分流量定期汇总,做召回,看是否是nginx问题、或者是domain记录缺失。
IP端口往往无法及时更新,一小时扫一次全内网IP和端口已经是比较迅速了,但仍会有失效的端口,像JDWP这种,业务调试时开放、下班了关掉。0X03 减少规则冗余请求
如果可以实时监控端口开放与关闭状态,开放了再进行指纹扫描,不必定时全量扫描,端口存活检测可只作为召回召回。但端口状态监控比较麻烦,比如http连接时客户端开放的端口,请求完就关闭,这种消息是无效的,拿去作端口指纹识别,海量的数据会浪费很多不必要的性能。
在实践过程中,遇到的情况是端口指纹不明确,所以运营人员也不敢随便选二级指纹,很多情况都是规则没有选择具体框架/服务指纹,也就不管端口有没有指纹都扫描了,因为规则无具体指纹产出的漏洞占比较大,直接一刀切、产出骤降。所以只有遇到规则有指纹、端口也有指纹的时候,才进行匹配过滤。有很长一段时间,web的无效任务集中在qps超限后的操作,也就是第三篇 2.1.4的内容。qps控制不能单单的控制到任务、或者是域名层面,而是为了满足大流量情况,尽可能控制到接口层面,尽可能用可以用的、业务用剩下的qps,这就需要控制的单位往扫描引擎流程后移,尽可能的控制力度更细。
规则指纹匹配,往往难点在于端口指纹打标的准确性。
端口打标流程有了之后,打标的召回、持续运营还是漫漫长路。
celery的超时中断有软超时和硬超时两种;软超时即是超时的时候,在当前运行代码报错,但在规则运行时报错可能会被catch;硬超时直接中断任务,但没有日志,就相当于流量丢了,溯源/召回起来很不方便
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |