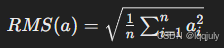qidao123.com技术社区-IT企服评测·应用市场
标题:
LLaMA 的模子布局
[打印本页]
作者:
花瓣小跑
时间:
2024-11-25 10:12
标题:
LLaMA 的模子布局
1. LLaMA 的 Transformer 架构改进
LLaMA 基于经典的 Transformer 架构,但与原始的 Transformer 相比有几点重要改进:
前置层归一化(Pre-Normalization)
:LLaMA 采用的是前置层归一化,意味着层归一化操作在多头自注意力层(self-attention layer)和全连接层之进步行。这种方法有助于稳固梯度,使得模子在深层次网络中可以或许更好地传播梯度,避免练习中的梯度消失或爆炸问题。
RMSNorm 替代了 LayerNorm
:在 LLaMA 中,RMSNorm 被用作归一化函数,区别于 GPT-2 中的 LayerNorm。RMSNorm 的上风在于其通过对输入向量的均方根(Root Mean Square, RMS)举行归一化,进一步增强了练习过程中的稳固性。其计算公式:
该公式计算出输入向量的均方根,再举行归一化,并可引入可学习的缩放因子和偏移参数来增强模子表达本领。
RMSNorm 在 HuggingFace Transformer 库中代码实现:
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
初始化 LlamaRMSNorm 模块。
参数:
- hidden_size: 输入隐藏状态的维度,即需要归一化的特征数。
- eps: 用于数值稳定的非常小的数,防止计算过程中分母为0(通常为1e-6)。
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size)) # 权重参数初始化为1
self.variance_epsilon = eps # 数值稳定项
def forward(self, hidden_states):
"""
前向传播函数,执行归一化操作。
参数:
- hidden_states: 输入的张量,表示网络层的隐藏状态。
返回值:
- 返回归一化并且经过缩放的隐藏状态。
"""
# 保存输入的原始数据类型,以便最后转换回同样的类型
input_dtype = hidden_states.dtype
# 计算方差(或更准确地说是每个样本的特征值的均值平方)
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
# 对 variance 加上 epsilon,防止分母为0,然后取平方根的倒数,进行归一化
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
# weight 是可训练参数,用于缩放归一化后的输出
return (self.weight * hidden_states).to(input_dtype)
复制代码
2. 激活函数 SwiGLU
LLaMA 还在全连接层中使用了
SwiGLU
激活函数。SwiGLU 是一种改进的激活函数,相比经典的 ReLU 或 Swish,它在大规模模子如 PaLM 和 LLaMA 中表现更好,能提供更高的非线性表达本领。其计算公式为:
Swish 函数自己定义为
,此中σ 是 Sigmoid 函数。
SwiGLU 的上风
:相比于简单的 ReLU 激活函数,SwiGLU 可以或许捕捉更复杂的模式,特别是在深度学习模子中,提升了模子的表现和练习效率。
Swish 激活函数在参数差别取值下的形状
3. 旋转位置嵌入(RoPE)
RoPE(Rotary Positional Embedding)
是 LLaMA 中一个重要的创新,旨在替代传统的绝对位置编码,改进位置信息在注意力机制中的作用。其核心思想是通过使用复数的多少操作(旋转)将位置编码引入查询(q)和键(k)中,实现相对位置编码的效果。公式如下:
此中, θ是位置编码的频率参数, m表示位置。
通过这种方式,RoPE 可以或许高效地在恣意偶数维度的情况下实现位置编码,且其矩阵情势具有希奇性,因此计算速度更快。
RoPE 的上风在于它能处置惩罚更长的序列并捕捉相对位置信息,特别适合在大规模自然语言模子中应用。
RoPE 在 HuggingFace Transformer 库中代码实现如下:
class LlamaRotaryEmbedding(torch.nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
# 调用父类的初始化函数,确保模块正确继承 nn.Module 的功能
super().__init__()
# `inv_freq` 是逆频率的计算结果,它根据维度 `dim` 来生成。该逆频率用于生成正弦和余弦嵌入。
# `torch.arange(0, dim, 2)` 生成从 0 到 dim 的偶数序列(步长为 2),然后除以 dim,构造分布式频率。
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))
# 将逆频率 `inv_freq` 注册为模型的缓冲区,这意味着它不是可训练参数,但会被持久保存。
self.register_buffer("inv_freq", inv_freq)
# 初始化时,预先缓存最大序列长度对应的旋转嵌入,避免在每次前向传播时重复计算
self.max_seq_len_cached = max_position_embeddings
# `t` 是时间步(位置索引),从 0 到 `max_seq_len_cached - 1` 的序列,用来生成位置嵌入。
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
# 通过 `einsum` 进行矩阵乘法,将 `t` 和 `inv_freq` 相乘生成频率矩阵 `freqs`,表示每个位置和对应的频率。
# einsum("i,j->ij") 表示进行外积操作,将 `t` 和 `inv_freq` 组合成位置-频率矩阵。
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# 将 `freqs` 进行拼接,扩展为 [seq_len, dim],这样每个位置都有对应的频率嵌入。
emb = torch.cat((freqs, freqs), dim=-1)
# 获取当前默认的 `dtype`,以确保缓存的 `cos` 和 `sin` 的数据类型与输入一致。
dtype = torch.get_default_dtype()
# 缓存 cos 和 sin 嵌入,这里为嵌入增加了额外的维度以适配多头注意力机制的输入格式。
# `persistent=False` 表示这些缓冲区不会被持久保存到模型的状态字典中。
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
def forward(self, x, seq_len=None):
# `x` 是输入张量,通常形状为 [batch_size, num_attention_heads, seq_len, head_size]。
# 这部分代码检查当前序列长度是否超过缓存的最大序列长度 `max_seq_len_cached`。
if seq_len > self.max_seq_len_cached:
# 如果输入的序列长度超过了缓存的最大序列长度,重新计算 sin 和 cos 值。
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype)
# 重新计算位置和频率的外积。
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# 生成新的频率嵌入,并更新缓冲区。
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype), persistent=False)
# 截取缓存的 cos 和 sin 值,使其匹配输入序列的长度 `seq_len`,并确保数据类型与输入一致。
return (
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
)
# `rotate_half` 函数实现对输入张量的一半进行旋转操作,这是 RoPE 的核心机制。
# 它将输入张量的后半部分取负并与前半部分交换,形成旋转效果。
def rotate_half(x):
"""旋转输入张量的一半维度"""
x1 = x[..., : x.shape[-1] // 2] # 获取输入的前半部分。
x2 = x[..., x.shape[-1] // 2 :] # 获取输入的后半部分。
return torch.cat((-x2, x1), dim=-1) # 交换并将后半部分取负,拼接成新的张量。
# `apply_rotary_pos_emb` 函数将旋转位置嵌入应用到查询 `q` 和键 `k` 上。
# 它将 cos 和 sin 值乘以查询和键,然后通过旋转操作进行位置嵌入的应用。
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
# `cos` 和 `sin` 的前两维始终为 1,因此可以去掉这些冗余维度。
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
# 通过 `position_ids` 选择相应的嵌入,并扩展维度以匹配查询和键的形状。
cos = cos[position_ids].unsqueeze(1) # [batch_size, 1, seq_len, dim]
sin = sin[position_ids].unsqueeze(1) # [batch_size, 1, seq_len, dim]
# 对查询 `q` 应用旋转位置嵌入,先乘以 cos,再加上乘以 sin 的旋转结果。
q_embed = (q * cos) + (rotate_half(q) * sin)
# 对键 `k` 应用相同的旋转位置嵌入。
k_embed = (k * cos) + (rotate_half(k) * sin)
# 返回嵌入了位置编码的查询和键。
return q_embed, k_embed
复制代码
4. 模子团体框架
LLaMA 模子团体架构仍然是 Transformer 的自回归解码器。LLaMA 的设计吸收了 GPT 系列模子的优点,同时在以下几个方面做了重要改进:
更深的网络层次和更大的隐藏维度
:差别版本的 LLaMA 模子层数从 32 到 80 不等,嵌入维度则在 4096 到 8192 之间,这使得模子能更好地捕捉语言的复杂布局。
改进的超参数
: 列出差别规模的 LLaMA 模子的详细超参数(如层数、注意力头数、学习率等)。这些设计使得 LLaMA 能处置惩罚上万亿规模的练习 token,在大规模语料库上举行练习。
LLaMA 差别模子规模下的详细超参数细节
HuggingFace Transformer 库中 LLaMA 解码器团体实现代码实现:
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig):
# 初始化时调用父类的构造函数,确保正确继承
super().__init__()
# 从配置 `config` 中获取隐藏层大小,用于层的初始化
self.hidden_size = config.hidden_size
# 自注意力机制层的初始化,使用 LlamaAttention。它会处理输入的自注意力操作。
self.self_attn = LlamaAttention(config=config)
# 多层感知机层(MLP)用于后续的非线性变换。其包含一个隐藏层大小和中间层大小。
# `hidden_act` 是激活函数(如 ReLU),用于非线性变换。
self.mlp = LlamaMLP(
hidden_size=self.hidden_size, # 输入的隐藏层大小
intermediate_size=config.intermediate_size, # 中间层大小,通常是隐藏层大小的 4 倍
hidden_act=config.hidden_act # 激活函数,如 ReLU 或 GELU
)
# 输入层的归一化层,使用 RMSNorm,防止训练中的梯度爆炸或消失
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 注意力后的归一化层,确保经过注意力机制后的输出有稳定的分布
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor, # 输入的隐藏状态张量,形状为 [batch_size, seq_len, hidden_size]
attention_mask: Optional[torch.Tensor] = None, # 注意力掩码,防止模型关注到不需要的序列位置
position_ids: Optional[torch.LongTensor] = None, # 位置编码的ID,用于生成位置信息
past_key_value: Optional[Tuple[torch.Tensor]] = None, # 用于缓存前面层的键值对,加速推理
output_attentions: Optional[bool] = False, # 是否输出注意力权重
use_cache: Optional[bool] = False, # 是否使用缓存,加速推理
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
# 保存输入的隐藏状态到 `residual`,用于残差连接
residual = hidden_states
# 对输入的隐藏状态应用归一化处理,确保输入的数值稳定
hidden_states = self.input_layernorm(hidden_states)
# 自注意力机制,处理输入序列中的各个位置之间的相互依赖关系
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states, # 当前的隐藏状态
attention_mask=attention_mask, # 注意力掩码,防止模型关注到不相关的部分
position_ids=position_ids, # 位置编码,帮助模型知道序列中每个词的位置
past_key_value=past_key_value, # 用于加速推理的缓存
output_attentions=output_attentions, # 是否输出注意力权重
use_cache=use_cache, # 是否缓存键值对,加速下一步计算
)
# 通过残差连接,将输入(residual)与注意力层的输出相加,以避免梯度消失问题
hidden_states = residual + hidden_states
# 经过注意力机制后,保存当前的隐藏状态作为残差
residual = hidden_states
# 对经过注意力后的隐藏状态再次进行归一化处理
hidden_states = self.post_attention_layernorm(hidden_states)
# 进入多层感知机(MLP)模块,进行非线性变换,增加网络的表达能力
hidden_states = self.mlp(hidden_states)
# 再次通过残差连接,将 MLP 的输出与注意力后的隐藏状态相加
hidden_states = residual + hidden_states
# 将隐藏状态作为输出
outputs = (hidden_states,)
# 如果需要输出注意力权重,则将注意力权重也加入输出
if output_attentions:
outputs += (self_attn_weights,)
# 如果使用缓存,则将当前层的键值对缓存下来,便于后续层使用
if use_cache:
outputs += (present_key_value,)
# 返回包含隐藏状态和其他可选输出的元组
return outputs
复制代码
5. LLaMA 在 HuggingFace 中的实现
LlamaRMSNorm
类:实现了基于均方根的归一化函数,防止分母为零,确保数值稳固性。
LlamaRotaryEmbedding
类:实现了旋转位置嵌入,包罗了频率的计算和位置编码的实际操作。
LlamaDecoderLayer
类:展示相识码器层的团体架构,包括自注意力机制、RMSNorm、激活函数及全连接层等的集成,体现了模子的层级设计。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4