在zero-shot场景中有五花八门的Prompt模版,这里展示现有文献中四个最具代表性的。别的,再展示一个在 Alpaca中使用的Prompt模板,因为它在监视式微调中非常受欢迎。下表总结了这五种方法:
问题表示INSRIFKLLMsEM B S P BS_P BSPxx--- T R P TR_P TRP✓xxCode-Davinci-00269.0 O D P OD_P ODP✓✓xGPT-3.5-Turbo, GPT-470.1 C R P CR_P CRP✓x✓Code-Davinci-002, GPT-3.5-Turbo75.6 A S P AS_P ASP✓xx-- EX:SQL实验正确率、INS:指令(任务描述)、RI:规则信息(引导性语句,比如“仅输出SQL语句,无需表明”)、FK:外键(数据库的外键信息)
根本提示
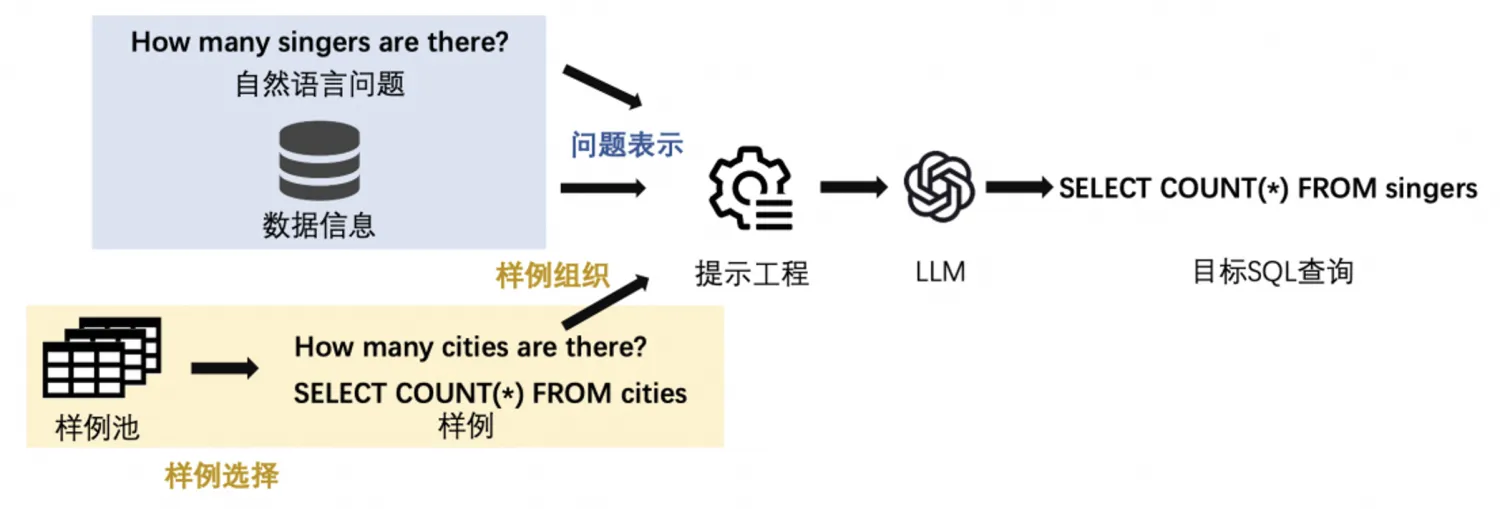
随机选择(Random):此策略随机采样 k k k个可用候选的示例 Q Q Q,现有的工作已经将其作为示例选择的基准方案。
问题相似性选择(Question Similarity Selection):此方案选择与目标问题 q q q最相似的 k k k个示例。具体来说,使用预训练的语言模型(比如BERT等)将示例问题 Q Q Q和目标问题 q q q嵌入到同一个向量空间。然后,盘算每个<示例问题, 目标问题>对应用预界说的距离度量,如欧氏距离或负余弦相似度。末了,使用 k k k近邻(KNN)算法从 Q Q Q中选择 k k k个与目标问题 q q q相近的示例。