超详细【入门精讲】数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本
感谢B站UP主 哈喽鹏程!!!
目录
0. B站课程链接 和 搭建数据仓库资源下载
下载UP主 哈喽鹏程 给的资源镜像及脚本包
课程链接:https://www.bilibili.com/video/BV1qv411y7Wv/
下载连接:
数据仓库的课件:
链接:https://pan.baidu.com/s/1_B2FPJYbHR-qq-5Q-Xfamw/?pwd=d3a9
提取码:d3a9
数据仓库的实验数据,资源镜像及脚本包:
链接:https://pan.baidu.com/s/1zSkL1YWa6wGkKrUW-Zl8Yw/?pwd=fwpq
提取码:fwpq
数据仓库的automaticDeploy项目代码:
链接:https://pan.baidu.com/s/1qspiJ8LbrSr58pg84ICRUA/?pwd=7nff
提取码:7nff
备用链接:
数据仓库的实验数据,资源镜像及脚本包:
链接:https://pan.baidu.com/s/1WZsfADEGUlD1U7LcEf2dww/?pwd=ik61
提取码:ik61
数据仓库的资源镜像及脚本包和automaticDeploy项目代码(全):
OneDrive链接
1. 项目介绍及
1.1项目介绍
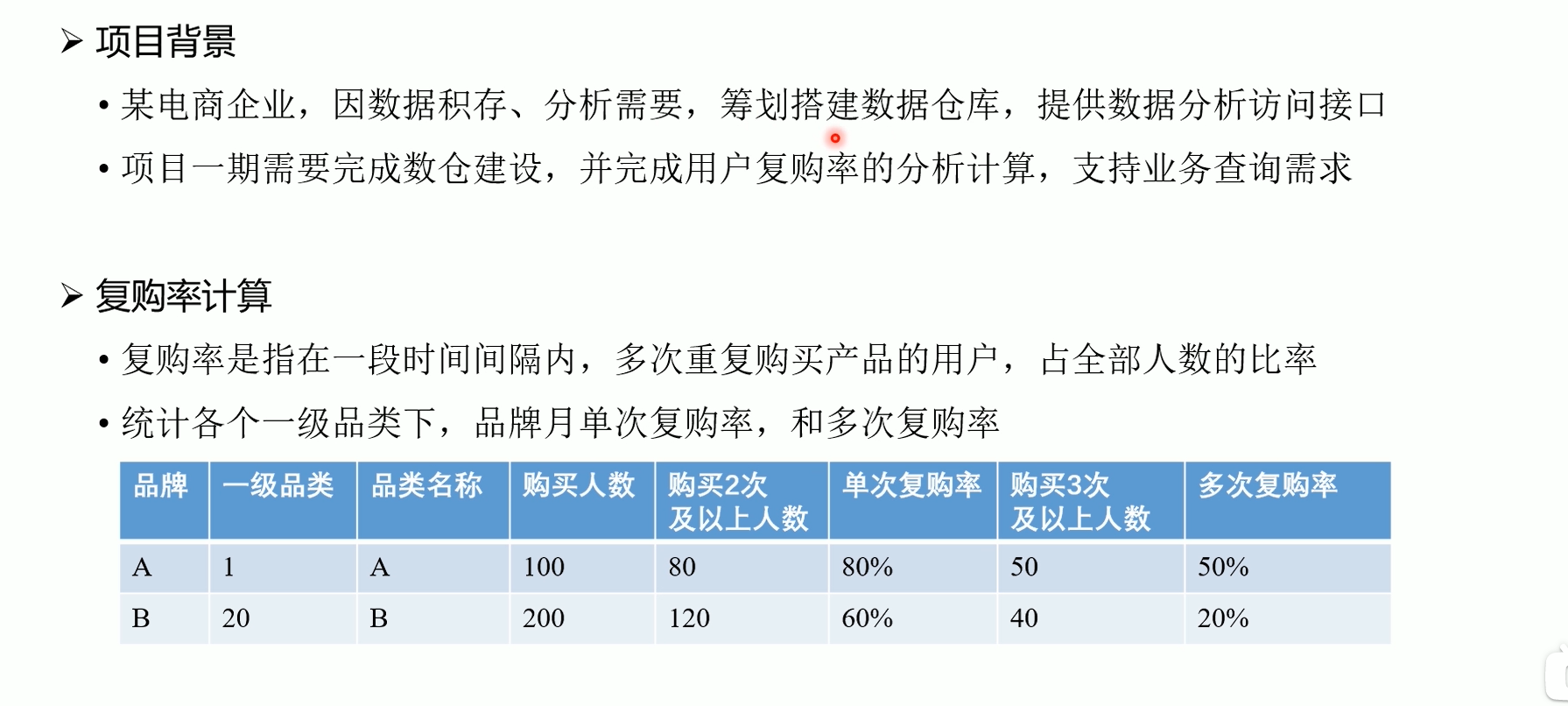
1.2 数据仓库架构
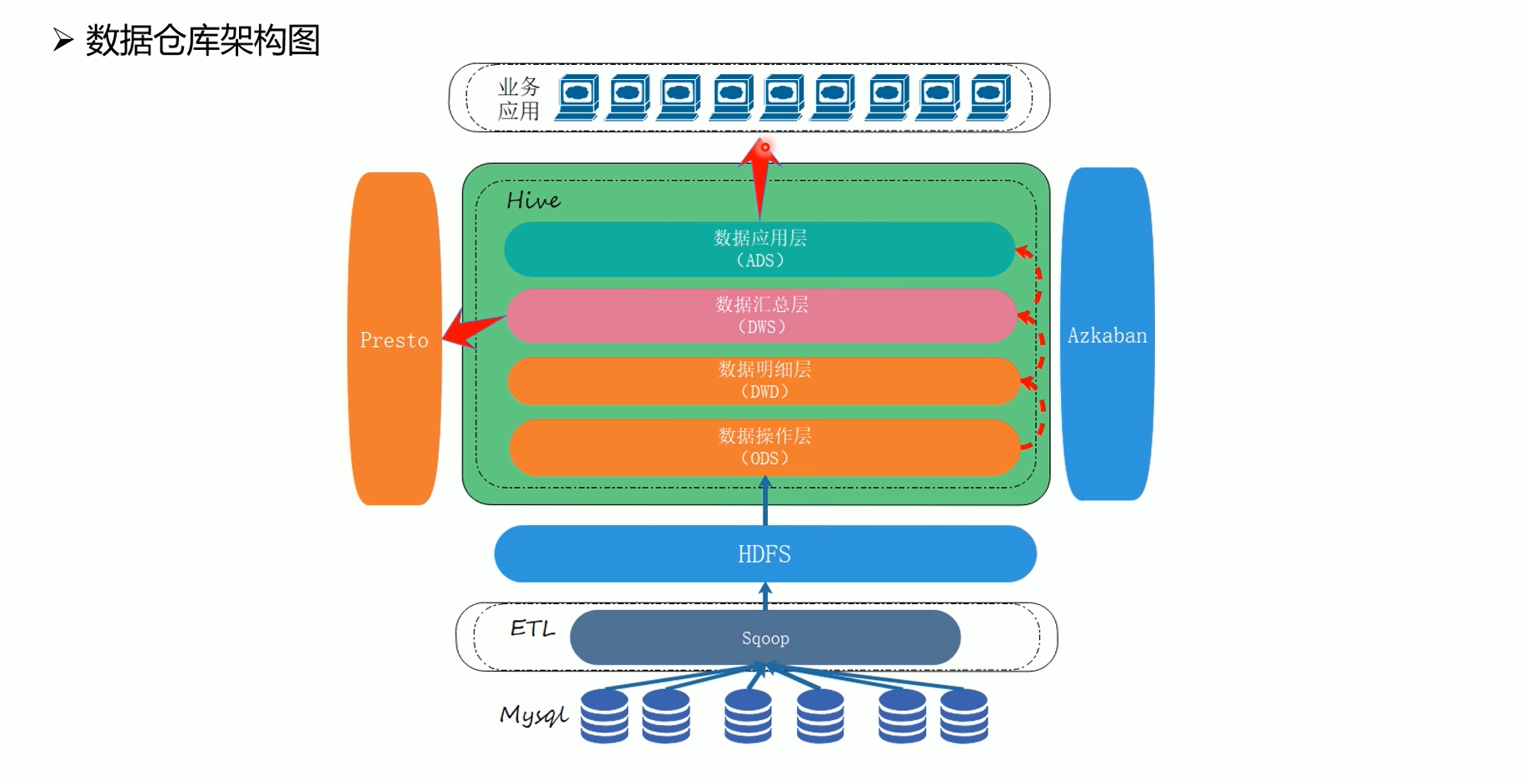
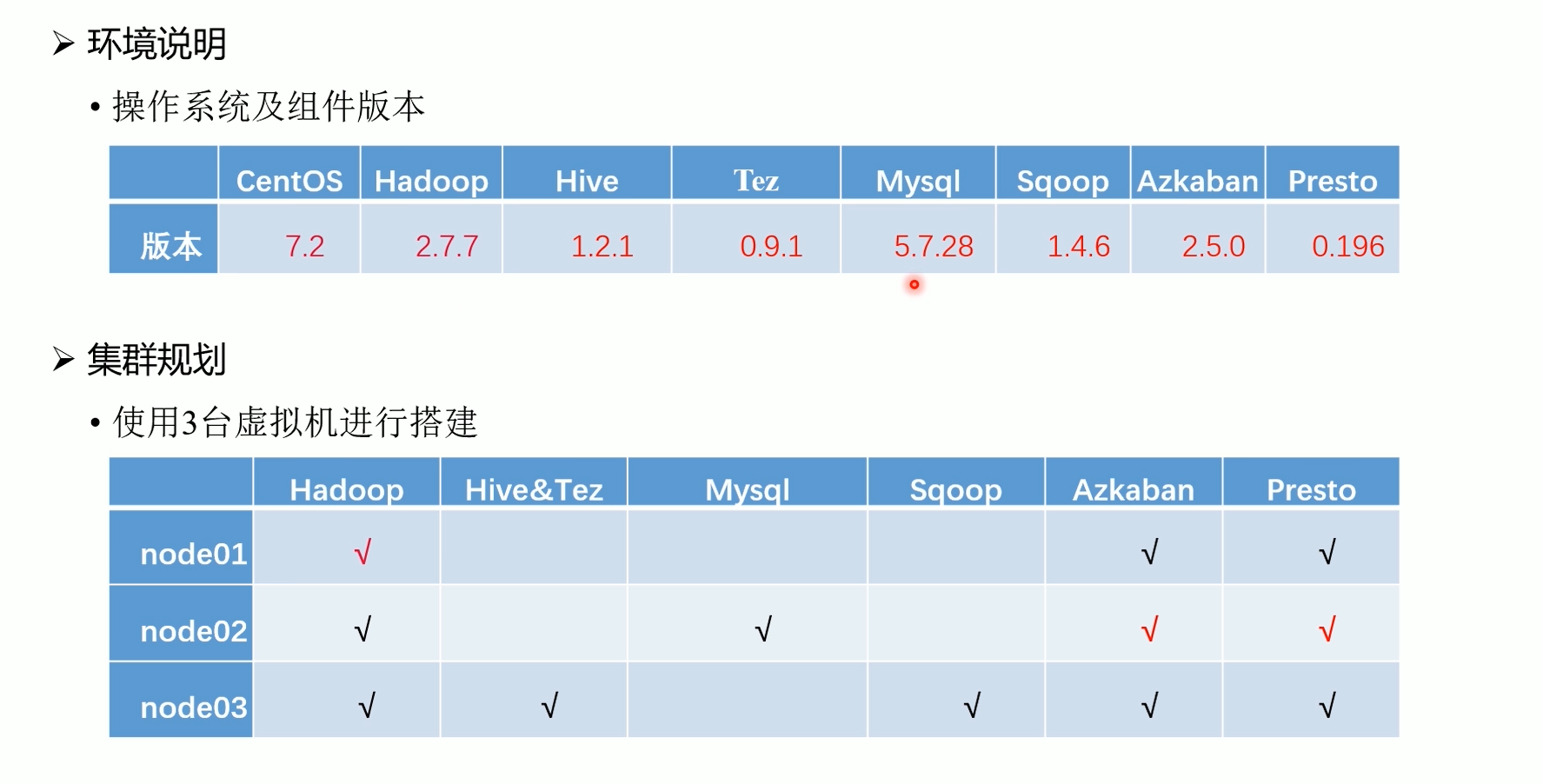
1.3 环境规划
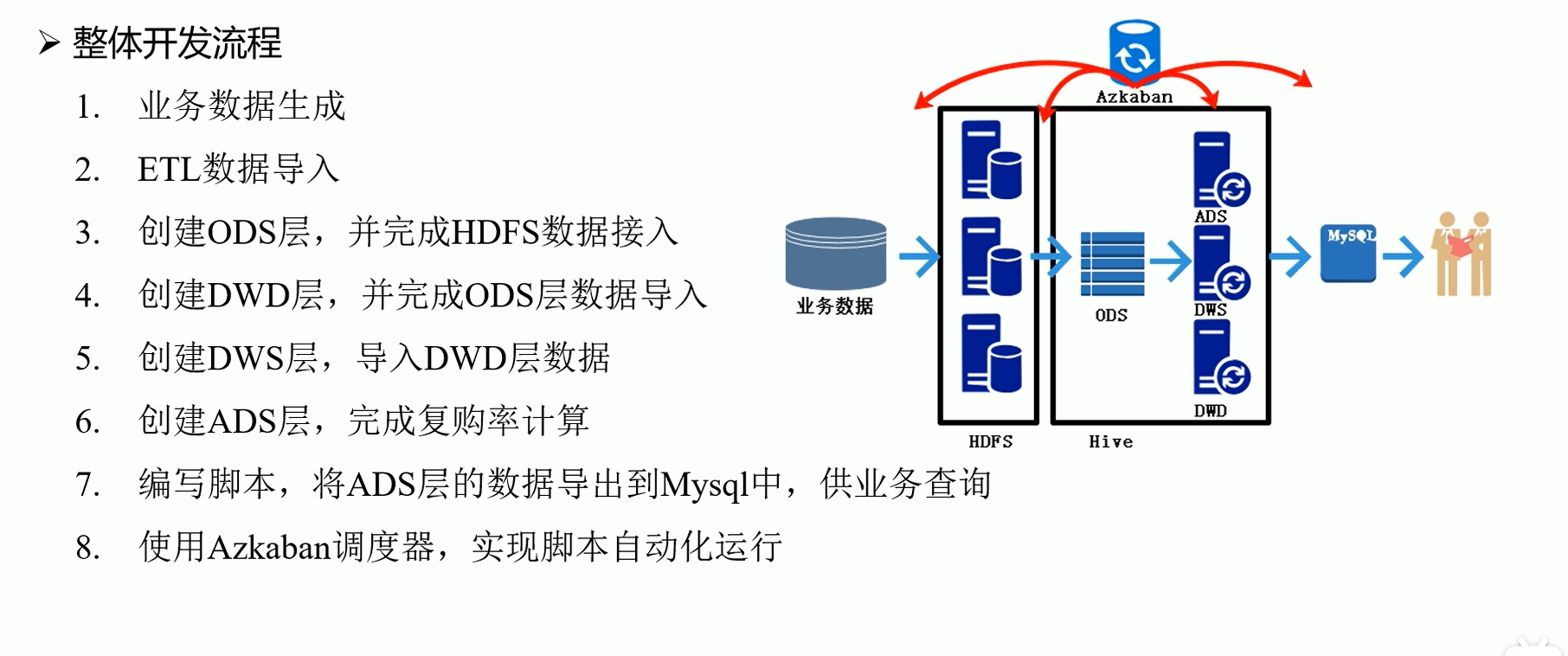
1.4 整体开发流程
2. 环境准备01-02(虚拟机和Xshell)
2.1 软件下载
安装以下软件:
Virtual Box**, **下载链接: https://www.virtualbox.org/
XShell,下载链接:https://www.xshell.com/zh/xshell/
FinalShell, 下载链接:http://www.hostbuf.com/t/988.html
下载UP主 哈喽鹏程 给的资源镜像及脚本包
2.2 安装Virtual Box及导入OVA镜像
官网下载安装包,一路next就行,可以更改安装路径
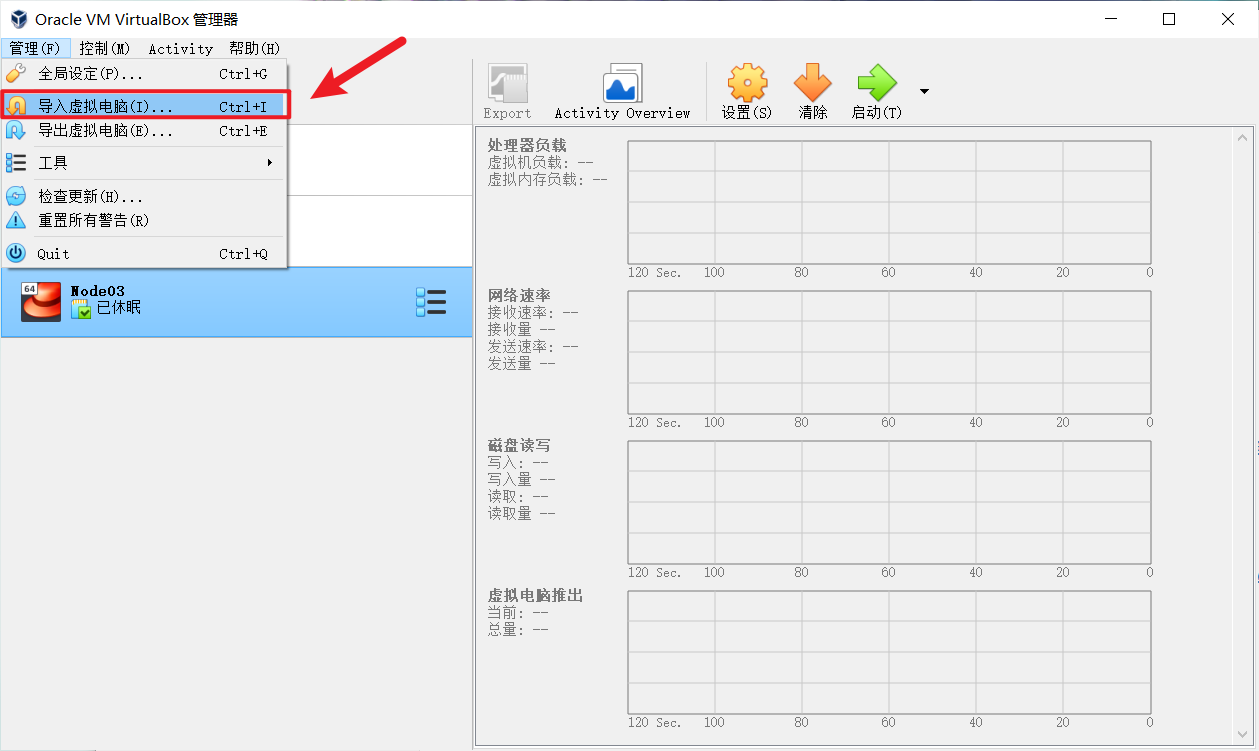 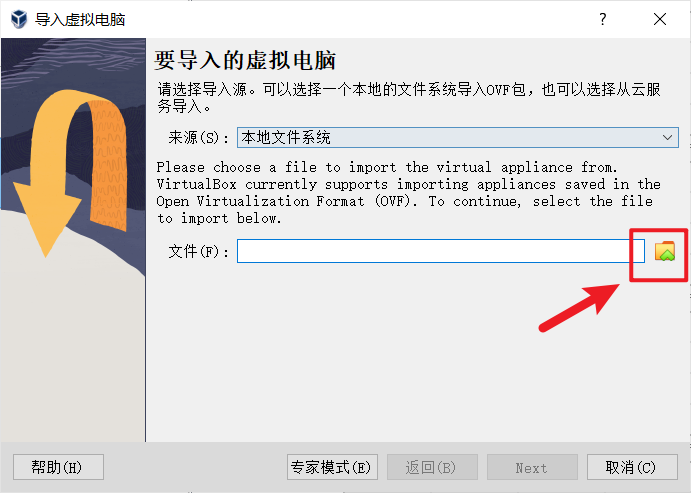
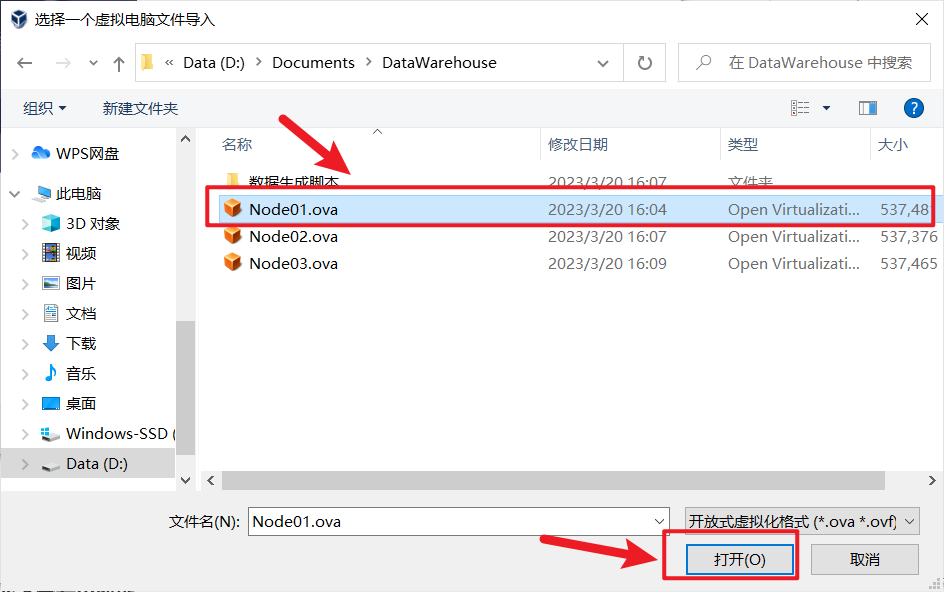 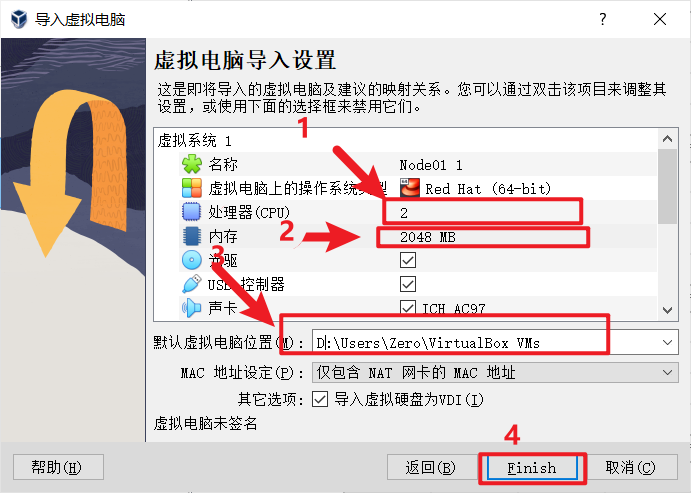
node02,node03同样的操作
虚拟机第一次打开的时候可能会有网络报错,这个时候需要操作一下
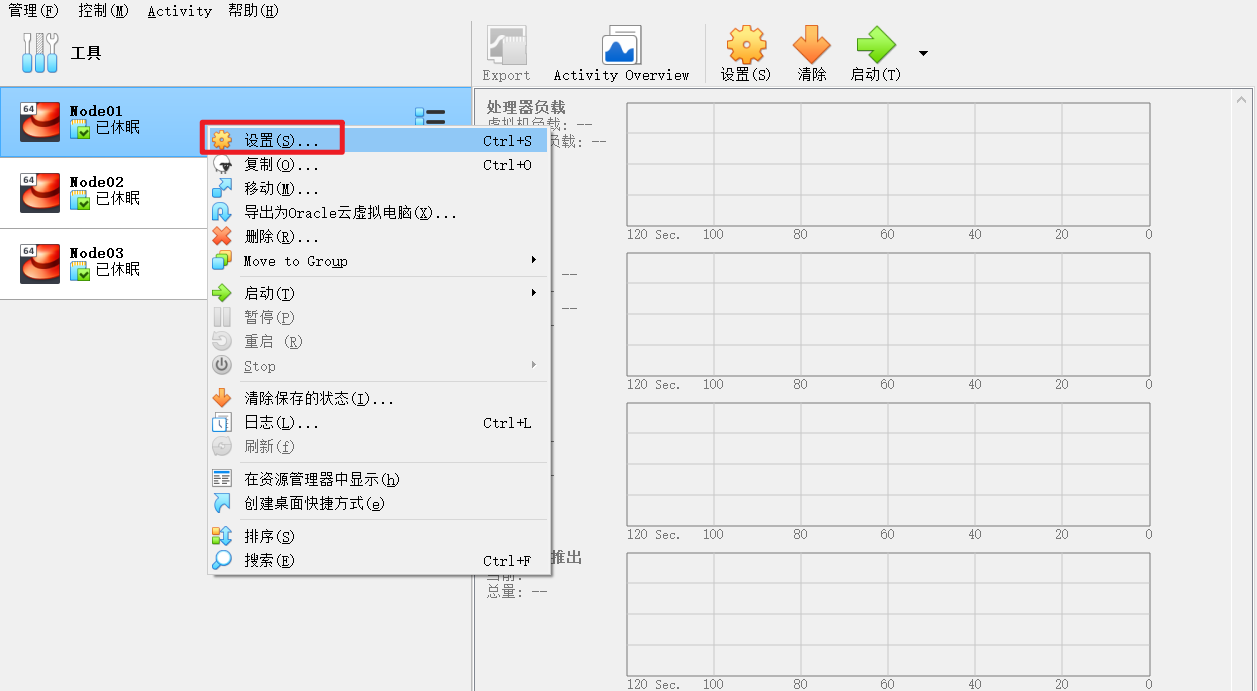
这里需要手动选择一次网卡,注意是一定要再选择一次
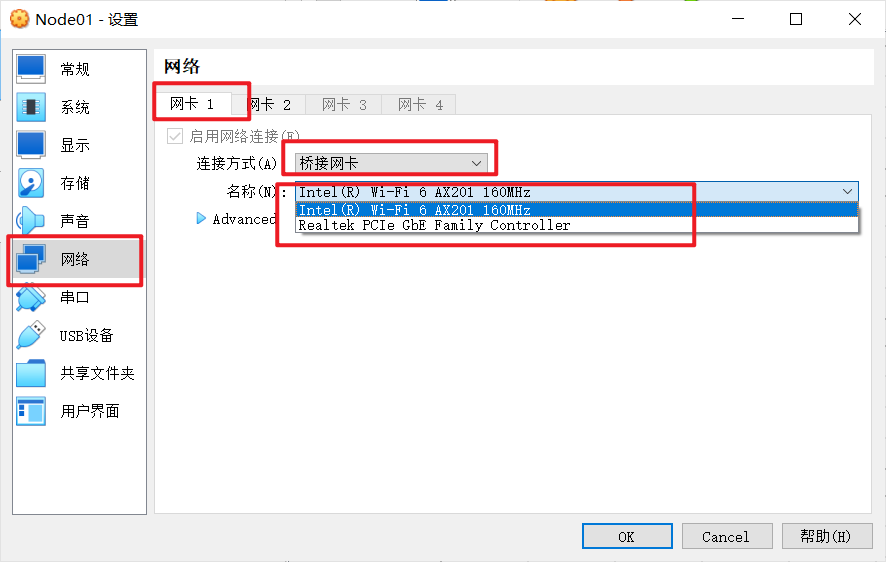
然后可以开启虚拟机了
三台虚拟机用户名及密码, 进入虚拟机
node01 root 123456
node02 root 123456
node03 root 123456
2.3 修改虚拟机静态IP地址
windows下查看IP地址
win+r 然后输入cmd 回车,打开命令行窗口,输入ifconfig查看主机ip地址
例如:
192.168.192.175
本地链接 IPv6 地址. . . . . . . . : fe80::8ecd:4848:96f2:2659%6
IPv4 地址 . . . . . . . . . . . . : 192.168.192.175
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : fe80::40a2:4aff:feb4:7d31%6
192.168.192.165
在得到主机的IP地址后,分别对三台虚拟机node01、node02、node03进行修改
例如我的IP为192.168.192.175,则修改以下内容:
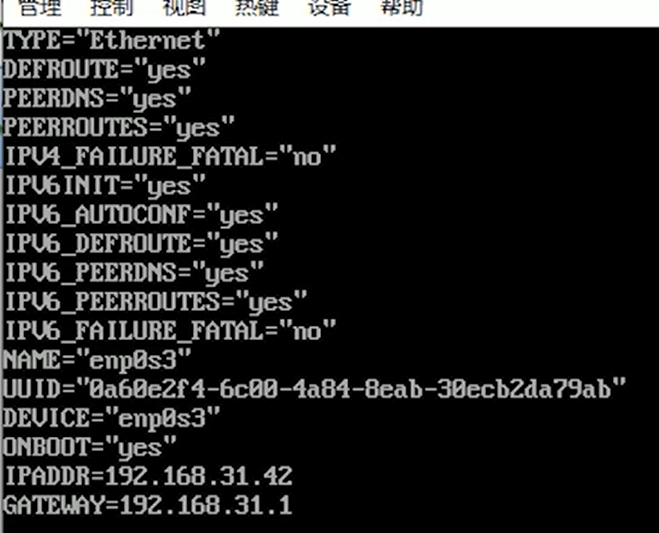
node01中的ifcfg-enp0s3文件中IPADDR=192.168.192.176
node02中的ifcfg-enp0s3文件中IPADDR=192.168.192.177
node03中的ifcfg-enp0s3文件中IPADDR=192.168.192.178
node02和node03中的GATEWAY=192.168.192.1
修改配置文件 ifcfg-enp0s3- [root@node01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
- [root@node01 ~]# systemctl restart network
- [root@node02 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
- [root@node02 ~]# systemctl restart network
- [root@node03 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
- [root@node03 ~]# systemctl restart network
注意node01没有GATEWAY,node02,node03有GATEWAY
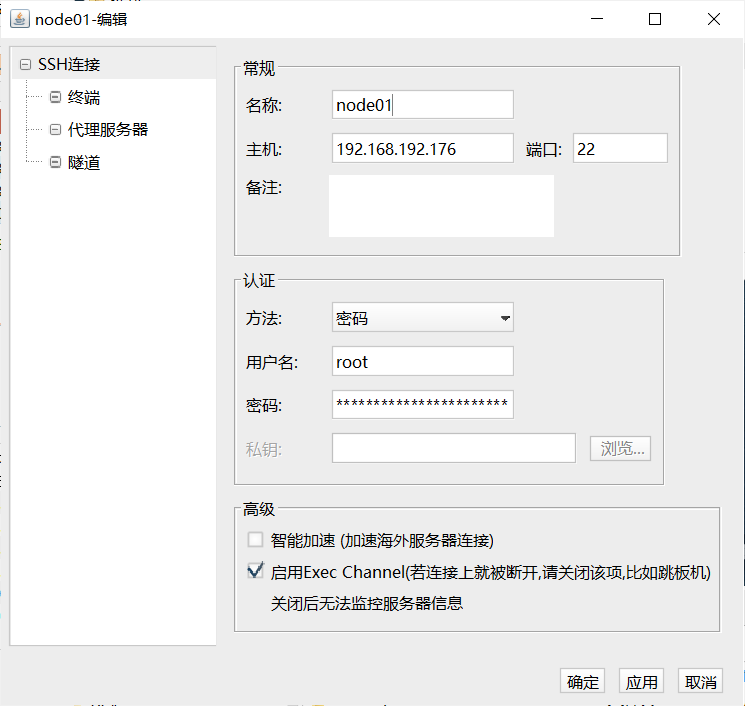
2.4 SSH链接虚拟机
这里使用 FinalShell SSH连接虚拟机
node01配置如下, node02和node03同理
3. 环境搭建03 (脚本准备)
- wget https://github.com/Mtlpc/automaticDeploy/archive/master.zip
将下载好的文件解压到 /home/hadoop 下,并将该文件的文件名改成 automaticDeploy,否则运行会报错
以下是 automaticDeploy 中的文件- [root@node01 ~]# cd /home/hadoop/
- [root@node01 hadoop]# unzip automaticDeploy.zip
- # 给予可执行权限
- [root@node01 hadoop]# chmod +x /home/hadoop/automaticDeploy/hadoop/* [root@node01 hadoop]# /home/hadoop/automaticDeploy/systems/*
- # 文件内容
- [root@node01 hadoop]# ls automaticDeploy/
- configs.txt frames.txt hadoop host_ip.txt logs.sh README.md systems
- # Mysql相关配置
- mysql-root-password DBa2020* END
- mysql-hive-password DBa2020* END
- mysql-drive mysql-connector-java-5.1.26-bin.jar END
- # azkaban相关配置
- azkaban-mysql-user root END
- azkaban-mysql-password DBa2020* END
- azkaban-keystore-password 123456 END
这个需要配置成自己的3个node的ip- 192.168.31.41 node01 root 123456
- 192.168.31.42 node02 root 123456
- 192.168.31.43 node03 root 123456
- # 通用环境
- jdk-8u144-linux-x64.tar.gz true
- azkaban-sql-script-2.5.0.tar.gz true
- # Node01
- hadoop-2.7.7.tar.gz true node01
- # Node02
- mysql-rpm-pack-5.7.28 true node02
- azkaban-executor-server-2.5.0.tar.gz true node02
- azkaban-web-server-2.5.0.tar.gz true node02
- presto-server-0.196.tar.gz true node02
- # Node03
- apache-hive-1.2.1-bin.tar.gz true node03
- apache-tez-0.9.1-bin.tar.gz true node03
- sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz true node03
- yanagishima-18.0.zip true node03
- # Muti
- apache-flume-1.7.0-bin.tar.gz true node01,node02,node03
- zookeeper-3.4.10.tar.gz true node01,node02,node03
- kafka_2.11-0.11.0.2.tgz true node01,node02,node03
当然如果不使用Xshell的话, 使用FinalShell就可以不用安装, FinalShell自带文件上传组件- [root@node01 automaticDeploy]# yum install lrzsz -y
- [root@node01 ~]# cd ~
- [root@node01 ~]# unzip frames.zip -d /home/hadoop/automaticDeploy/
- [root@node01 ~]# ssh root@192.168.133.177 "mkdir /home/hadoop"
- [root@node01 ~]# ssh root@192.168.133.178 "mkdir /home/hadoop"
这个需要配置成自己的3个node的ip- 192.168.192.176 node01 root 123456
- 192.168.192.177 node02 root 123456
- 192.168.192.178 node03 root 123456
- # 将修改后的automaticDeploy复制到node02,node03
- [root@node01 hadoop]# scp -r /home/hadoop/automaticDeploy/ root@192.168.192.177:/home/hadoop/
- [root@node01 hadoop]# scp -r /home/hadoop/automaticDeploy/ root@192.168.192.178:/home/hadoop/
4. 环境搭建04 (集群安装)
恭喜你完成了以上操作, 到这一步正式开始环境搭建- # 分别在node01,node02,node03运行批处理脚本 batchOperate.sh 进行初始化
- # 更新yum源, 免密钥登入,安装JDK,配置HOST
- # node01
- [root@node01 ~]# cd automaticDeploy
- [root@node01 automaticDeploy]# cd systems/
- [root@node01 systems]# ./batchOperate.sh
- # node02
- [root@node02 ~]# cd automaticDeploy/systems/
- [root@node02 systems]# ./batchOperate.sh
- # node03
- [root@node03 ~]# cd automaticDeploy/systems/
- [root@node03 systems]# ./batchOperate.sh
注意: 每连完一台虚拟机后都要退出, 然后再连接另一台- # 分别SSH另外两台虚拟机, exit 退出SSH
- # 示例: [root@node02 ~]# exit
- # node01
- [root@node01 systems]# ssh node02
- [root@node01 systems]# ssh node03
- # node02
- [root@node02 systems]# ssh node01
- [root@node02 systems]# ssh node03
- # node03
- [root@node03 systems]# ssh node01
- [root@node03 systems]# ssh node02
- # 脚本免密登录失败的话,可以手动进行免密登录操作
- # 以下为示例
- [root@node01 ~]# ssh-copy-id node02
分别在三台虚拟机上依次执行- [root@node01 hadoop]# ./installHadoop.sh
- [root@node02 hadoop]# ./installHadoop.sh
- [root@node03 hadoop]# ./installHadoop.sh
- [root@node01 hadoop]# source /etc/profile
- [root@node02 hadoop]# source /etc/profile
- [root@node03 hadoop]# source /etc/profile
- [root@node01 hadoop]# hadoop namenode -format
- [root@node01 ~]# start-all.sh
- [root@node01 ~]# jps
- 6193 NameNode
- 6628 SecondaryNameNode
- 7412 Jps
- 6373 DataNode
- 6901 ResourceManager
- 7066 NodeManager
- [root@node02 ~]# jps
- 5952 NodeManager
- 6565 Jps
- 5644 DataNode
- [root@node03 ~]# jps
- 6596 Jps
- 5594 DataNode
- 5902 NodeManager
可以打开浏览器,访问 node01 的 50070 端口, 进入hadoop的web界面
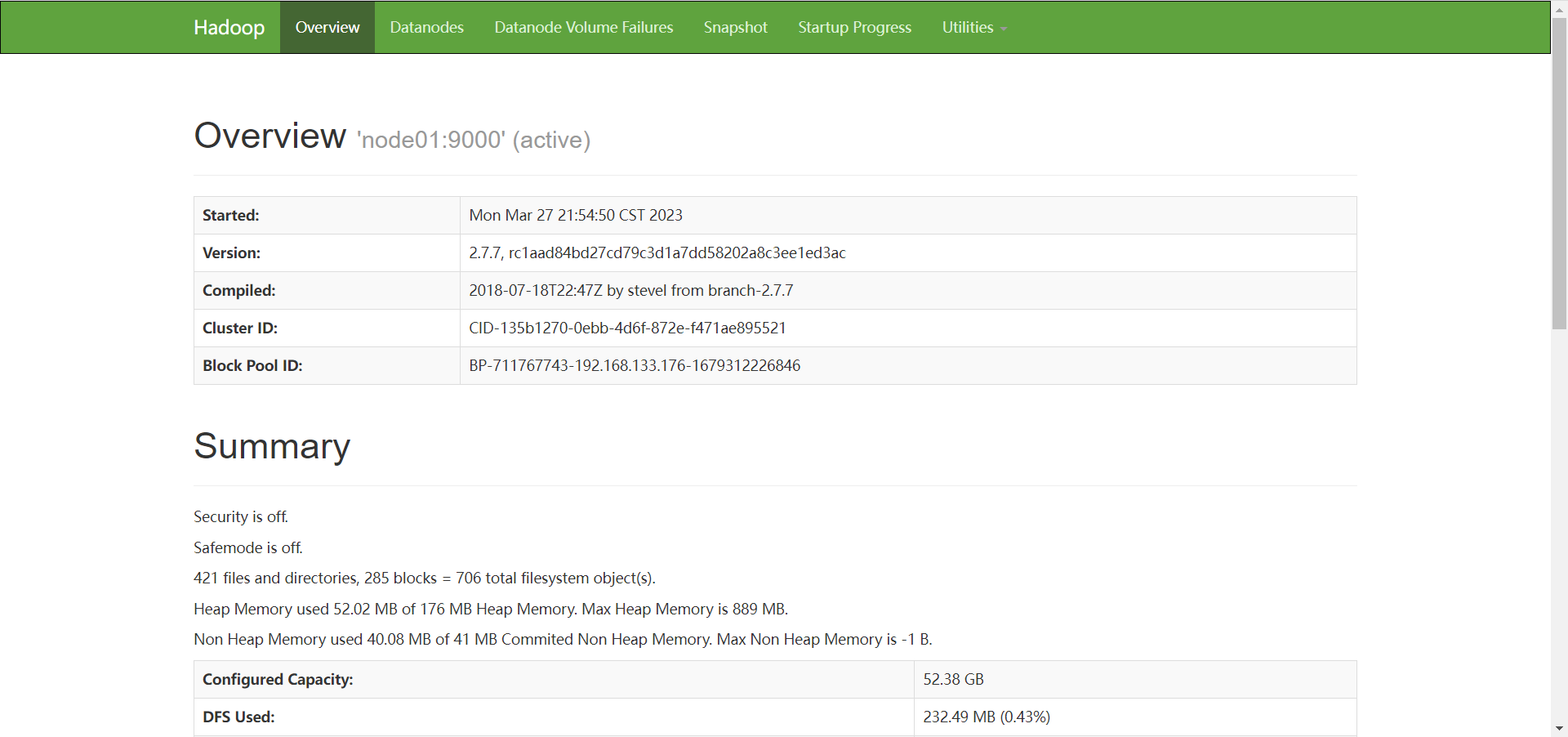  4.2 安装MYSQL 4.2 安装MYSQL
在 node02 上安装 MYSQL- [root@node02 hadoop]# ./installMysql.sh
- [root@node02 hadoop]# mysql -uroot -pDBa2020*
- mysql> show databases;
- mysql> show databases;
- +--------------------+
- | Database |
- +--------------------+
- | information_schema |
- | azkaban |
- | hive |
- | mysql |
- | performance_schema |
- | sys |
- +--------------------+
- 6 rows in set (0.01 sec)
在 node03 上安装 Hive, 安装过程会自动安装 Tez- [root@node03 hadoop]# ./installHive.sh
4.4 安装Sqoop
接着在 node03 上安装 Sqoop- [root@node03 hadoop]# ./installSqoop.sh
- [root@node03 hadoop]# source /etc/profile
分别在node01,node02, node03 上安装 Presto
Presto服务端口为8080- # Presto服务端口为8080
- [root@node01 hadoop]# ./installPresto.sh
- [root@node02 hadoop]# ./installPresto.sh
- [root@node03 hadoop]# ./installPresto.sh
- [root@node01 hadoop]# ./installAzkaban.sh
- [root@node02 hadoop]# ./installAzkaban.sh
- [root@node03 hadoop]# ./installAzkaban.sh
Yanagishima服务端口为7080- # Yanagishima服务端口为7080
- [root@node03 hadoop]# ./installYanagishima.sh
- # 分别在node01,node02,node03运行更新环境变量[root@node01 hadoop]# source /etc/profile
- [root@node02 hadoop]# source /etc/profile
- [root@node03 hadoop]# source /etc/profile

创建数据库mall- # 导入临时环境变量
- [root@node01 hadoop]# export MYSQL_PWD=DBa2020*
- [root@node01 hadoop]# mysql -uroot -e "create database mall;"
- [root@node02 hadoop]# cd /home/

将数据生成脚本上传到数据库中- [root@node02 home]# mysql -uroot mall < /root/1建表脚本.sql
- [root@node02 home]# mysql -uroot mall < /root/2商品分类数据插入脚本.sql
- [root@node02 home]# mysql -uroot mall < /root/3函数脚本.sql
- [root@node02 home]# mysql -uroot mall < /root/3函数脚本.sql
- [root@node02 home]# mysql
- mysql>use mall;
- mysql>CALL init_data('2020-08-29',300,200,300,False);
- mysql>select count(1) from user_info;
- mysql>show tables;
6. ETL数据导入
- [root@node03 ~]# mkdir -p /home/warehouse/shell
- [root@node03 shell]# cd /home/warehouse/shell/
- [root@node03 shell]# vim sqoop_import.sh
- [root@node03 shell]# chmod +x sqoop_import.sh
- [root@node03 shell]# ./sqoop_import.sh all 2020-08-29
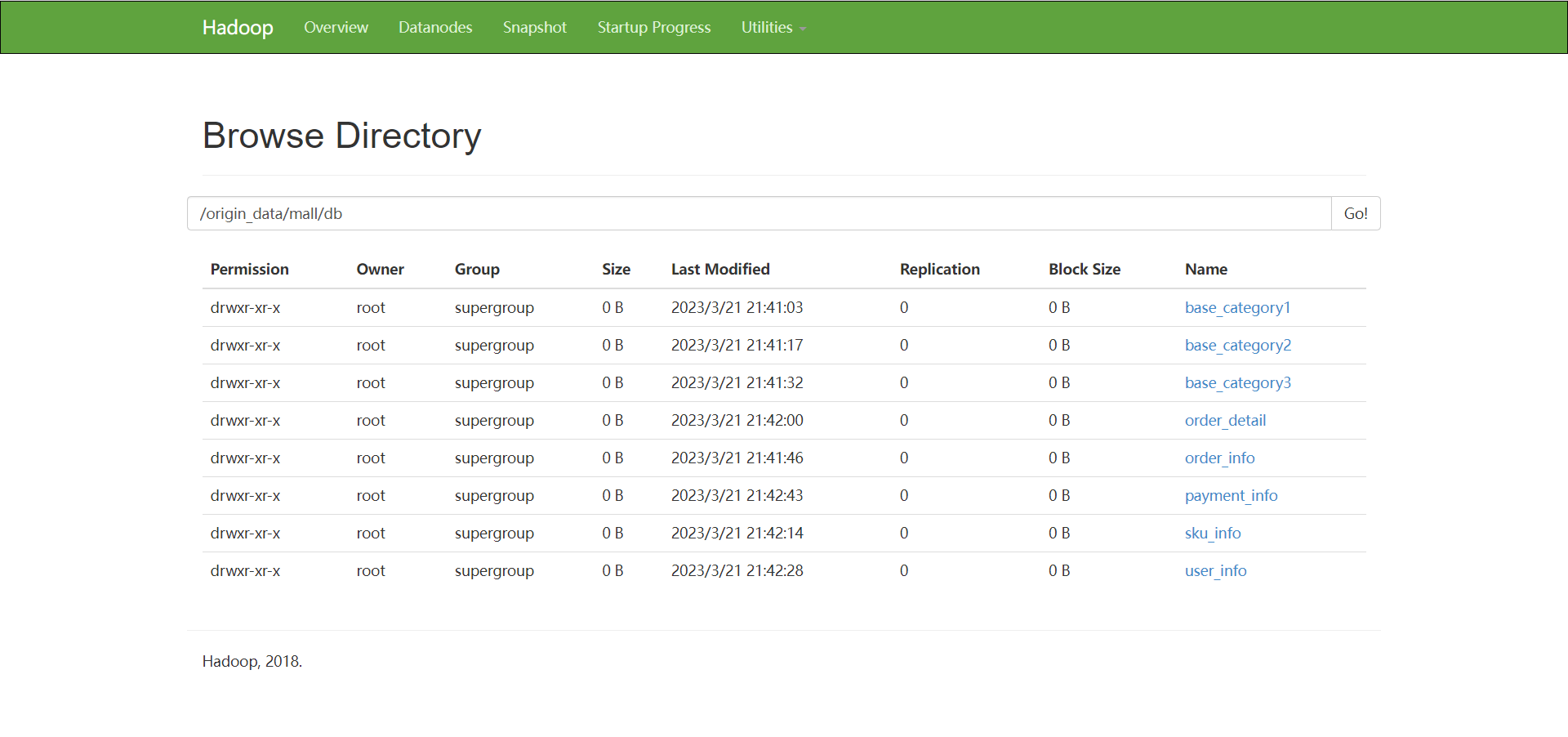
一共是8张表, 如果没有8张表的话, 建议多运行 ./sqoop_import.sh all 2020-08-29 命令几次
到这里,表示我们ETL任务已经成功了
7. ODS层创建&数据接入
启动Hive- # 启动Hive
- [root@node03 shell]# hive --service hiveserver2 &
- # 启动Hive的metastore
- [root@node03 shell]# hive --service metastore &
- [root@node02 ~]# systemctl restart network
- # ODS层创建&数据导入
- [root@node03 ~]# cd /home/warehouse
- [root@node03 warehouse]# mkdir sql/
- [root@node03 warehouse]# cd sql/
- [root@node03 sql]# vim ods_ddl.sql
- [root@node03 sql]# hive -f /home/warehouse/sql/ods_ddl.sql
查看刚刚Hive进行的两个服务- [root@node03 sql]# jps
- 2378 NodeManager
- 2133 DataNode
- 7288 RunJar
- 7210 RunJar
- 7646 Jps
- [root@node03 sql]# jps -m
- .
- .
- .
- 7288 RunJar .... /... /... / ....... / hadoop.hive.metastore.HiveMetaStore
- .
- .
- .
- # kill metastore服务
- [root@node03 sql]# kill -9 7288
- # 然后再重启 metastore, metasore服务需要连接mysql服务, 所以需要与node02网络通畅
- [root@node03 sql]# hive --service metastore &
- # 没有报错,重新执行 hive -f /home/warehouse/sql/ods_ddl.sql
- [root@node03 sql]# hive -f /home/warehouse/sql/ods_ddl.sql
- ## 进入hive
- [root@node03 shell]# hive
- hive>use mall;
- OK
- Time taken: 0.55 seconds
- hive>show tables;
- hive>exit;
- [root@node03 shell]# cd ..
- [root@node03 shell]# cd shell/
- # 创建或上传 obs_db.sh
- [root@node03 shell]# vim obs_db.sh
- [root@node03 shell]# chmod +x obs_db.sh
- [root@node03 shell]# ./ods_db.sh 2020-08-29
- ## 进入hive
- [root@node03 shell]# hive
- hive> use mall;
- OK
- Time taken: 0.55 seconds
- hive> show tables;
- hive> select count(1) from ods_user_info;
- Query ID = root_20230327220623_2ce7b554-c007-4d37-b282-87a3227c2f16
- Total jobs = 1
- Launching Job 1 out of 1
- Status: Running (Executing on YARN cluster with App id application_1679925264749_0002)
- --------------------------------------------------------------------------------
- VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
- --------------------------------------------------------------------------------
- Map 1 .......... SUCCEEDED 2 2 0 0 0 0
- Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
- --------------------------------------------------------------------------------
- VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.56 s
- --------------------------------------------------------------------------------
- OK
- 200
- Time taken: 9.383 seconds, Fetched: 1 row(s)
- # 200条数据
- hive> exit;
创建并执行dws_ddl.sql- [root@node03 shell]# cd /home/warehouse/sql/
- [root@node03 sql]# vim dws_ddl.sql
- 创建或上传 dwd_ddl.sql
- [root@node03 warehouse]# hive -f /home/warehouse/sql/dwd_ddl.sql
- [root@node03 shell]# cd /home/warehouse/shell/
- # 创建或上传 dwd_db.sh
- [root@node03 shell]# vim dwd_db.sh
- [root@node03 shell]# chmod +x dwd_db.sh
- [root@node03 shell]# ./dwd_db.sh 2020-08-29
- ## 进入hive
- [root@node03 shell]# hive
- hive>use mall;
- hive>show tables;
- hive>select * from dwd_sku_info where df='2020-08-29' limit 2;
- hive> exit;
创建并执行dws_ddl.sql- # DWS层创建&数据接入 node03
- [root@node03 shell]# cd /home/warehouse/sql/
- [root@node03 shell]# vim dws_ddl.sql
- [root@node03 sql]# hive -f /home/warehouse/sql/dws_ddl.sql
- [root@node03 sql]# cd ../shell/
- [root@node03 shell]# vim dws_db.sh
- [root@node03 shell]# chmod +x dws_db.sh
- [root@node03 shell]# ./dws_db.sh 2020-08-29
- [root@node03 shell]# hive
- hive> use mall;
- hive> show databases;
- hive> select * from dws_user_action where dt="2020-08-29" limit 2;
- OK
- SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
- SLF4J: Defaulting to no-operation (NOP) logger implementation
- SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
- 1 3 1593 2 665 2020-08-29
- 10 1 434 1 434 2020-08-29
- Time taken: 0.35 seconds, Fetched: 2 row(s)
- # !!! 注意这里的SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder不用管
- hive> exit;
创建并执行ads_sale_ddl.sql- # ADS层复购率统计 node03
- [root@node03 shell]# cd /home/warehouse/sql/
- [root@node03 shell]# vim ads_sale_ddl.sql
- [root@node03 sql]# hive -f /home/warehouse/sql/ads_sale_ddl.sql
- [root@node03 sql]# cd /home/warehouse/shell/
- [root@node03 shell]# vim ads_db.sh
- [root@node03 shell]# chmod +x ads_sale.sh
- [root@node03 shell]# ./ads_sale.sh 2020-08-29
- [root@node03 shell]# hive
- hive> use mall;
- hive> exit;
创建并执行mysql_sale.sql- # ADS层数据导入
- # node02
- [root@node02 ~]# mkdir -p /home/warehouse/sql
- [root@node02 sql]# vim mysql_sale.sql
- [root@node02 sql]# export MYSQL_PWD=DBa2020*
- [root@node02 sql]# mysql -uroot mall < /home/warehouse/sql/mysql_sale.sql
- [root@node02 sql]# mysql
- mysql> use mall;
- mysql> show tables;
- +-------------------------------+
- | Tables_in_mall |
- +-------------------------------+
- | ads_sale_tm_category1_stat_mn |
- | base_category1 |
- | base_category2 |
- | base_category3 |
- | order_detail |
- | order_info |
- | payment_info |
- | sku_info |
- | user_info |
- +-------------------------------+
- 9 rows in set (0.00 sec)
- mysql> exit;
- # node03
- [root@node03 ~]# cd /home/warehouse/shell/
- [root@node03 shell]# vim sqoop_export.sh
- [root@node03 shell]# chmod +x sqoop_export.sh
- [root@node03 shell]# ./sqoop_export.sh all
- # node02
- [root@node02 sql]# systemctl restart network
- [root@node02 sql]# mysql -uroot -pDBa2020*
- mysql> use mall;
- mysql> select * from ads_sale_tm_category1_stat_mn;
- +-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
- | tm_id | category1_id | category1_name | buycount | buy_twice_last | buy_twice_last_ratio | buy_3times_last | buy_3times_last_ratio | stat_mn | stat_date |
- +-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
- | NULL | NULL | NULL | 158 | 141 | 0.89 | 107 | 0.79 | 2020-08 | 2020-08-29 |
- | NULL | NULL | NULL | 158 | 141 | 0.89 | 107 | 0.79 | 2020-08 | 2020-08-29 |
- | NULL | NULL | NULL | 284 | 256 | 0.9 | 207 | 0.81 | 2020-08 | 2020-08-30 |
- +-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
- 3 rows in set (0.00 sec)
- mysql> exit;
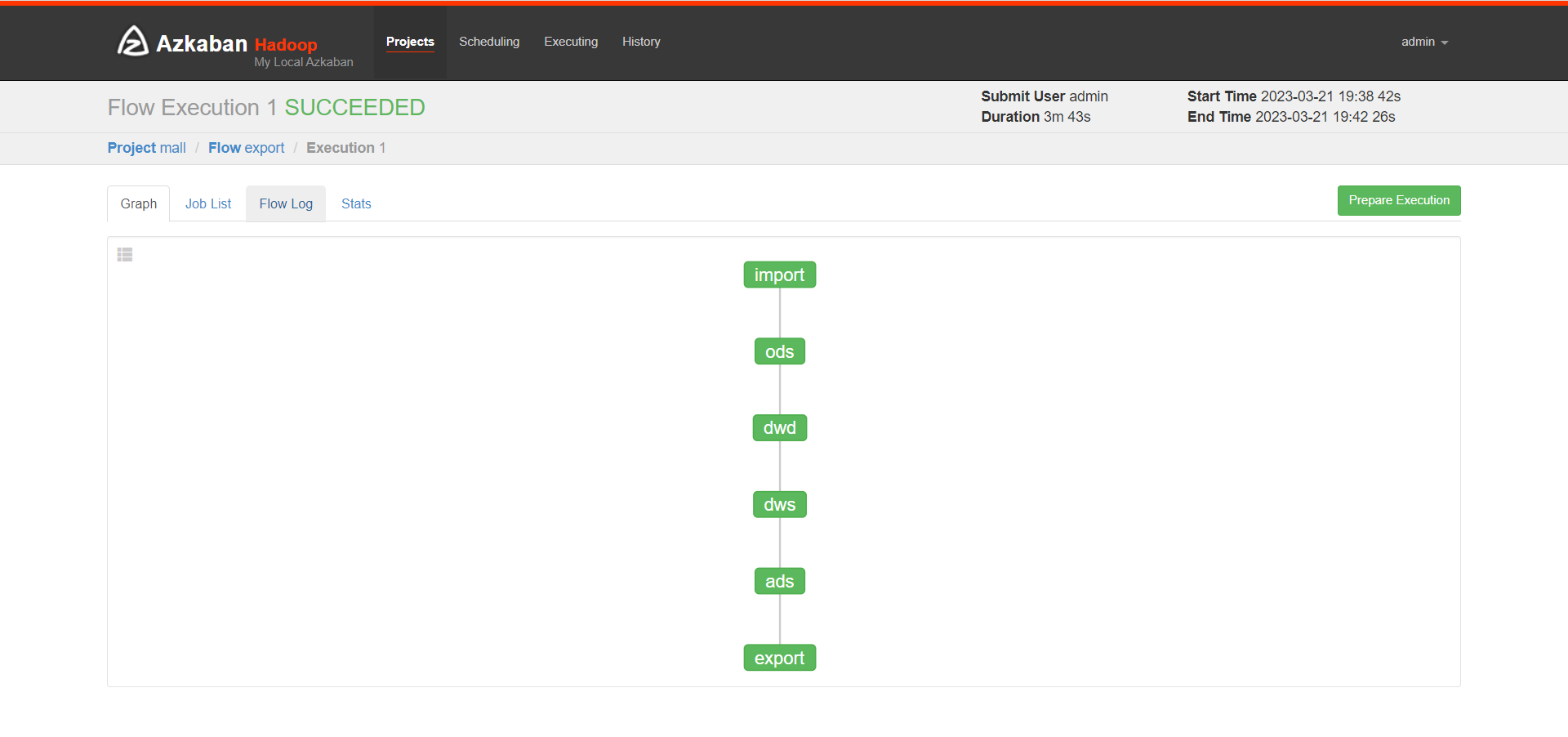
Azkaban自动化调度, 生成数据- # Azkaban自动化调度
- # 生成数据
- [root@node02 sql]# mysql -uroot -pDBa2020*
- mysql> use mall;
- mysql> CALL init_data('2020-08-30',300,200,300,FALSE);
- Query OK, 0 rows affected (0.70 sec)
三个节点启动Azkaban- # 准备mall_job.zip
- # 三个节点启动Azkaban
- [root@node01 ~]# azkaban-executor-start.sh
- [root@node02 ~]# azkaban-executor-start.sh
- [root@node03 ~]# azkaban-executor-start.sh
- [AzkabanExecutorServer] [Azkaban] Azkaban Executor Server started on port 12321
- # azkaban出问题时,可以重启, 关闭命令如下
- # 重启命令 azkaban-executor-shutdown.sh
- #node03 启动Azkaban的web网页
- [root@node03 shell]# cd /opt/app/azkaban/server/
- [root@node03 server]# azkaban-web-start.sh
- # https://192.168.192.178:8443/ # node03 注意这里是https
- # Azkaban:
- # 账号:admin
- # 密码:admin
- # 创建project mall
- # 设置参数 dt 2020-08-30
- # 设置参数 useExecutor node03
- # 等自动化调度任务执行完后
- # 到node02查看执行情况,新建一个node02连接终端
- [root@node02 ~]# mysql -uroot -pDBa2020*
- mysql> use mall;
- mysql> select * from ads_sale_tm_category1_stat_mn;
  14. 课后作业 14. 课后作业

15. 更换IP后所需要做的操作
- # http://192.168.192.176:50070/ # node01
- # https://192.168.192.178:8443/ # node03 注意这里是https
- # Azkaban:
- # 账号:admin
- # 密码:admin
- # 更改虚拟机静态IP地址
- # 更改host_ip.txt
- cd /home/hadoop/automaticDeploy/
- vim host_ip.txt
- systemctl restart network
- source /etc/profile
- 右键左下角windows
- 点击网络连接 --> 网络和共享中心
 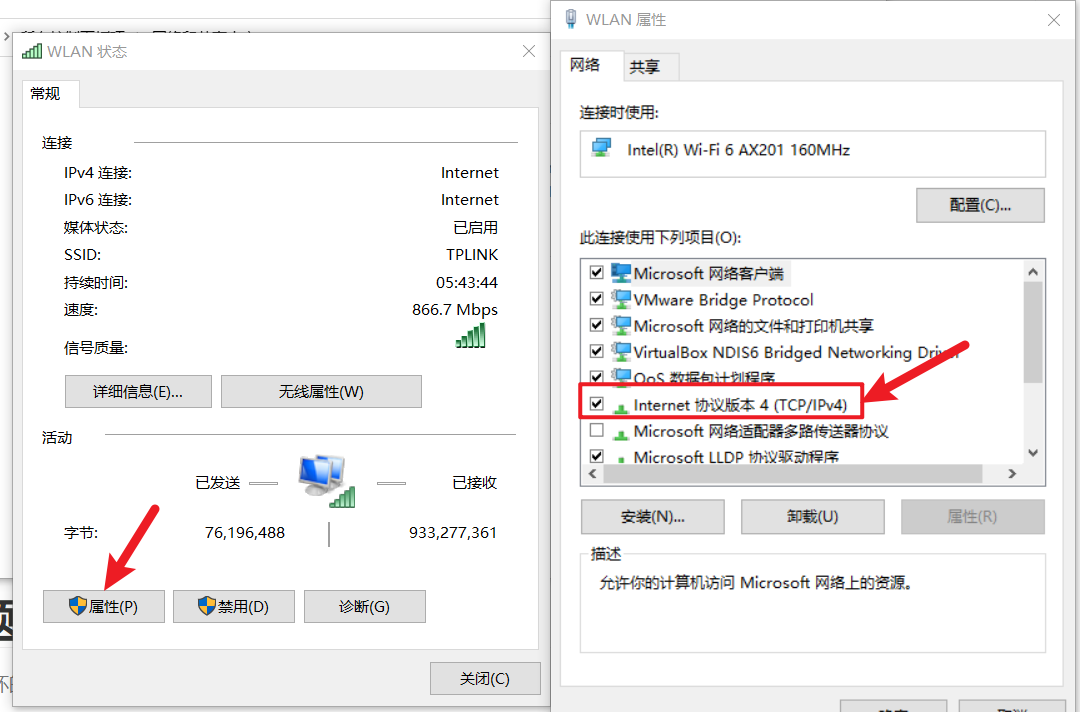
- 接下来按照自己电脑的ip改,我这里这是参考,具体得看每个人自己得电脑
 查看自己电脑的ip信息 查看自己电脑的ip信息
win+r打开运行cmd,然后输入ipconfig查看
  17. 常见问题(未完持续更新中,欢迎补充!) 17. 常见问题(未完持续更新中,欢迎补充!)
欢迎大家在搭建数据仓库的遇到的问题在评论区下方提出,也可以补充在下面
相应问题及解决方法:
/bin/bash^M: 坏的解释器: 没有那个文件或目录 : https://blog.csdn.net/qq_56870570/article/details/120182874
拒接连接:重启网络 systemctl restart network
VMware 运行 systemctl restart network失败:软件问题,请使用virtual box
作者:Oraer
都看到最后了,不点个赞+收藏吗?
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |










