好久不见!
个人库的地点:(GitHub - JJJJJJJustin/Nut: The game_engine which learned from Cherno),可以看到我实时更新的结果。
-------------------------------Saving & Loading scene------------------------------------
》》》》更改 Premake 文件构架
这一会合 Cherno 对 premake 文件举行了操纵,不外此时 Premake 文件的构架发生了改变(如今每个项目标 premake 被放置在项目标文件夹下,而不是会合放置在 Nut 根目次下的 Premake 文件中),这是由于之前的一次 pull request。
原来预备先美满引擎 UI ,背面会合对引擎举行维护,如今看来就先提交一下这个更改吧。
具体可以参考:( https://github.com/TheCherno/Hazel/pull/320 )
》》》》一个标题:关于 premake 文件中的定名
当我将 yaml-cpp 作为键(Key) ,并以此来索引存储的值 (Value),此时会出现一个错误:
Error: [string "return IncludeDir.yaml-cpp"]:1: attempt to perform arithmetic on a nil value (field 'yaml') in token: IncludeDir.yaml-cpp
| ( 错误:[string“return IncludeDir.yaml-cpp”]:1:实验对令牌中的零值(字段“yaml”)实验算术运算:IncludeDir.yaml-cpp )
|
编译器似乎将 '-' 辨以为算术运算符,而不是文本符号,这导致他实验举行算术运算操纵。
但是当我将 '-' 更改为 '_' 时,如许的标题便消散了。
》》》》关于最新的 YAML 导致链接错误的办理方案
编译器疑似在以动态库的方式实验运行 yaml-cpp 库,并发出了很多告诫
开端办理方案:
》》 AND..
起首我已经在 yaml-cpp 的 premake 文件中声明白 "YAML_CPP_STATIC_DEFINE" ,而且打开了 staticruntime,但我发现没有作用。
接着办理:
标题是,你还必要在你所使用项目标 premake 文件中再次声明 "YAML_CPP_STATIC_DEFINE"
总结:
》》》》什么是 .editorconfig 文件?有什么作用?
标题引入:在深入研究这次提交时,一个以 .editorconfig 署名的文件映入眼帘,这是什么文件?
文件先容:
EditorConfig helps maintain consistent coding styles for multiple developers working on the same project across various editors and IDEs. The EditorConfig project consists of a file format for defining coding styles and a collection of text editor plugins that enable editors to read the file format and adhere to defined styles. EditorConfig files are easily readable and they work nicely with version control systems.
来自 <EditorConfig>
| 翻译:
EditorConfig 可资助多个开发职员在差异的编辑器或 IDE 上维护同一个项目标编码风格,使其保持同等。EditorConfig 项目包罗一个用于界说编码风格的文件格式和一组文本编辑器插件,这些插件可让编辑器读取文件格式并遵照界说的风格。EditorConfig 文件易于阅读,而且可与版本控制体系美满共同。
|
作用:
通过使用 EditorConfig 文件,团队中的每个成员可以确保他们的代码遵照类似的格式,低落因代码风格差异等而引起的标题。很多今世代码编辑器和 IDE(如 Visual Studio Code、Atom、JetBrains 系列等)都支持 EditorConfig,可以自动读取这些规则并应用到打开的文件中。
使用规范:
文件名:
| 文件名为 .editorconfig,通常放在项目根目次。
|
键值对格式:
| 使用 key = value 的情势界说规则,每条规则占一行。
空行和以 # 开始的行会被视为表明。
| 范围选择器:
| 使用
表现应用于全部文件,也可以使用其他模式如 *.js 或 *.py 来指定特定文件范例。
| 支持的属性:(支持的键值对)
| 常用属性包罗:
root:指示是否为顶层文件。
end_of_line:指定行竣事符(如 lf, crlf, cr)。
insert_final_newline:是否在文件末了插入换行符。
indent_style:设置缩进样式(如 tab 或 space)。
indent_size:指定缩进的巨细,可以是数字或 tab。
charset:文件字符集(如 utf-8, latin1 等)。
trim_trailing_whitespace:是否修剪行尾空缺。
|
详情参考文档:( EditorConfig Specification — EditorConfig Specification 0.17.2 documentation )
代码明白:
root = true:
| 指示这是一个顶层的 EditorConfig 文件,编辑器在找到此文件后不会再向上查找其他 EditorConfig 文件。
|
:
| 表现应用于全部文件范例的规则。
| end_of_line = lf:
| 指定行竣事符为 Unix 风格的换行符(LF,Line Feed)。这通常在类 Unix 体系(如 Linux 和 macOS)中使用。
| insert_final_newline = true:
| 指定在每个文件的末了插入一个换行符。这是一种精良的编码风俗,很多项目尺度要求如许做。
| indent_style = tab:
| 指定缩进样式为制表符(tab),而不是空格。这会影响代码的缩进方式。
|
《《《《拓展:什么是 Hard tabs?什么是 Soft tabs?
Hard Tabs
| 是使用制表符举行缩进,具有机动性但大概导致跨环境的差异等。
| Soft Tabs
| 是使用空格举行缩进,包管了同等性但文件体积大概更大。
|
选择使用哪种方式通常取决于团队的编码尺度或个人偏好。
》》》》 Y A M L U know what I'm saying
》》》》YAML YAML YAML
》》》》关于这次 premake 构架的维护,我只上传了一部门,剩下的留到之后维护时再做。如今我去相识一下 YAML。
》》》》YAML, What is yaml ? What we can do by yaml ?
先容:
YAML is a human-readable data serialization language that is often used for writing configuration files. Depending on whom you ask, YAML stands for yet another markup language or YAML ain't markup language (a recursive acronym), which emphasizes that YAML is for data, not documents.
来自 <What is YAML?>
| YAML 是一种人类可读的数据序列化语言,通常用于编写设置文件。根据使用的对象,YAML 可以代表另一种标志语言大概说 YAML 根本不是标志语言(递归缩写),这夸大了 YAML 用于数据,而不是文档。
|
明白:
在步调中,我们可以使用 yaml 对文件举行两种操纵:序列化和反序列化(Serialize & Deserialize)。
序列化意味着我们可以将复杂的数据变化为字节流,进而可以将其轻易生存到文件或数据库中。
反序列化则意味着我们可以对已经序列化的数据举行逆处置惩罚,进而将数据转换回原始的数据结构或对象状态。
根本:
根本结构
映射(Map):键值对的聚集。
|
key: value
| 序列(Sequence):有序的元素列表。
|
- item1
- item2
- item3
|
2. 嵌套结构
YAML 支持嵌套映射和序列,可以组合使用:
| person:
name: John Doe
age: 30
hobbies:
- reading
- cycling
|
3. 数据范例
YAML 支持多种数据范例,
包罗:字符串,数字,布尔值,Null 值。
| 比方:
string: "Hello, World!"
number: 42
boolean: true
null_value: null
|
》》》》yaml-cpp 的使用(详情请阅览: https://github.com/jbeder/yaml-cpp/blob/master/docs/Tutorial.md )
在 C++ 中使用 yaml-cpp 库,可以方便地处置惩罚 YAML 数据的读取和写入。(以下是读取 Yaml 文件和写入 Yaml 文件的示例)
读取 YAML
| #include <iostream>
#include <yaml-cpp/yaml.h>
int main() {
YAML::Node config = YAML: oadFile("config.yaml"); oadFile("config.yaml");
std::string name = config["person"]["name"].as<std::string>();
std::cout << "Name: " << name << std::endl;
return 0;
}
| 写入 YAML:
使用 YAML::Emitter 可以天生 YAML 文件
| #include <iostream>
#include <yaml-cpp/yaml.h>
int main() {
YAML::Emitter out;
out << YAML::BeginMap;
out << YAML::Key << "name" << YAML::Value << "John Doe";
out << YAML::Key << "age" << YAML::Value << 30;
out << YAML::EndMap;
std::cout << out.str() << std::endl; // 输出天生的 YAML
return 0;
}
|
YAML::Node
界说:YAML::Node 是 YAML-CPP 中的一个核心类,表现 YAML 文档中的一个节点。一个节点可以是标量(单个值)、序列(列表)或映射(键值对)。通过 YAML::Node,你可以以编程方式访问和操纵 YAML 数据结构。
| 创建和使用 YAML::Node:
Eg.
#include <yaml-cpp/yaml.h>
YAML::Node node = YAML:oad("key: value");
std::string value = node["key"].as<std::string>();
|
Sequences 和 Maps
Sequences(序列) 是一个有序列表,表现一组无定名的值。它们在 YAML 中用短横线表现:
| fruits:
- Apple
- Banana
- Cherry
| 在 YAML-CPP 中,你可以如许处置惩罚序列:
| Eg.
YAML::Node sequence = YAML:oad("[Apple, Banana, Cherry]");
for (const auto& item : sequence) {
std::cout << item.as<std::string>() << std::endl;
}
|
Maps(映射) 是一组键值对,表现定名的值。它们在 YAML 中用冒号分隔表现:
| person:
name: John Doe
age: 30
| 在 YAML-CPP 中,你可以如许处置惩罚映射:
| Eg.
YAML::Node map = YAML:oad("name: John Doe\nage: 30");
std::string name = map["name"].as<std::string>();
int age = map["age"].as<int>();
|
Sequences 和 Maps 的差异之处
序列和映射都是 YAML::Node 的一种。你可以在一个映射中嵌套序列,反之亦然。
差异之处:
序列:
| 没有键,每个项都有次序。
| 映射:
| 每个项都有唯一的键,次序不紧张。
|
Converting To/From Native Data Types
YAML-CPP 提供了方便的方法来将 YAML::Node 转换为 C++ 的原生数据范例。你可以使用 as<T>() 方法举行转换。
示例:从 YAML::Node 转换到原生数据范例
| YAML::Node node = YAML:oad("name: John Doe\nage: 30");
std::string name = node["name"].as<std::string>();
int age = node["age"].as<int>();
| 示例:从原生数据范例转换到 YAML::Node
| YAML::Node newNode;
newNode["name"] = "Jane Doe";
newNode["age"] = 28;
// 序列
YAML::Node fruits;
fruits.push_back("Apple");
fruits.push_back("Banana");
newNode["fruits"] = fruits;
// 输出为 YAML 格式
std::cout << newNode << std::endl;
|
》》由此引出两个疑惑:
标题一:
查阅文档时,我发现当插入的索引超出当前序列的范围时,YAML-CPP 会将节点视为映射,而不是继续保持序列
结论:动态范例:YAML::Node 的范例是动态的,可以在运行时根据操纵的差异而变革。当你使用整数索引时,它保持序列。当你使用非一连的索引或字符串键时,它会变化为映射。
标题二:怎样为Node添加一个映射?
在 YAML::Node node = YAML:oad("[1, 2, 3]"); 的环境下,使用 node[1] = 5 是不符合的.
如果你想让 node[1] 表现一个映射,node[1] = 5 会将序列中索引为 1 的元素(即第二个元素)设置为整数 5,而不是将其更改为一个映射。
如果你想在该位置设置一个映射,你可以如许做:
| YAML::Node node = YAML:oad("[1, 2, 3]");
node[1] = YAML::Node(YAML::NodeType::Map); // 创建一个新的映射
node[1]["key"] = "value"; // 向映射中添加键值对
| 结构:
|
- 1
- key: value
- 3
| 大概:
| YAML::Node node = YAML:oad("[1, 2, 3]"); // 将 node[1] 设置为一个新的映射
node[1] = YAML::Node(YAML::NodeType::Map); // 设置键为原来的值 2,并赋值为 5
node[1][2] = 5; // 这里的 2 是之前 index 1 的值
| 结构:
|
- 1
- 2: 5
- 3
|
注意:
如果你使用了 node["1"] = 5,由于 "1" 是一个字符串键,而不是数字索引,这将使步调实验在 node 中以 "1" 为键插入值 5。
node 本来是一个序列,但它会因此变化为一个映射。
| 最闭幕果会是 {
0: 1,
1: 2,
2: 3,
"1": 5},此中 "1" 是一个新的字符串键。
|
》》》》ifstream 和 ofstream 之间的关系
二者界说在 <fstream> 头文件中,管理文件流。
std::ifstream:
| 用于从文件中读取数据(输入文件流)。
| Std: fstream: fstream:
| 用于向文件中写入数据(输出文件流)。
|
易肴杂:<iostream>和文件流没有关系,<iostream> 是提供输入或输出流的尺度库,紧张包罗 std::cin, std::cout, std::cerr 等。
》》 ofstream 的使用:std:fstream 用于创建和写入文件
》》ifstream 的使用:std::ifstream 用于读入文件,进而对读入的文件举行一些处置惩罚。
(图例:逐行读取文件内容到字符串中)
大概(比上述方法更加高效,迅捷)
《《《《 什么是 rdbuf();
在 C++ 中,rd 通常是 "read" 的简写,意味着与读取操纵相干的函数。
rdbuf()
释义:
| rdbuf() 是 C++ 中的一个成员函数,可以直接访问流的底层缓冲区。它通常用于与输入输出流(如 std::ifstream, std:fstream, std::iostream 等)交互。
| 返回范例:
| std::streambuf* 返回指向与流关联的 std::streambuf 对象的指针。该指针可以用于直接举行低级别的输入输出操纵。
| 优点:直接访问缓冲区
| rdbuf() 返回一个指向当前流缓冲区的指针(即 std::streambuf 对象),答应你直接从流中读取或写入数据。
这意味着,你可以将整个文件的内容一次性读入,而不必要逐行或逐字符地读取,从而进步了服从。
当处置惩罚大型文件时,逐行读取会涉及多次 I/O 操纵,这大概导致性能瓶颈。而使用 rdbuf() 可以镌汰这些 I/O 操纵,由于它一次性读取整个缓冲区的数据。
|
类似的 rd 开头的函数尚有 rdstate()
| 寄义:rdstate() 是一个成员函数,用于获取流的状态标志。它返回一个整数,表现流的当前状态,包罗是否已到达文件竣事、是否发生了错误等。
|
》》》》FIEL STRUCTURE U know what I'm saying
》》》》YAML YAML YAML
》》》》YAML 文件构架,YAML 文件设置思绪
因此我们也可表明 Deserialize() 函数中做出的操纵:从 data(map) 中取出序列 entities(seq) ,然后通过 For 循环对序列中的 entity(map)举行读取,随后根据读取的数据去复现场景。
必要提示的是: Map 中的元素不能重复, Seq 中的元素可以重复。
》》》》 YAML::Emitter out << YAML::Flow;
概念:out << YAML::Flow 是 C++ 中使用 YAML 库(如 yaml-cpp)时的一种语法,它用来设置 YAML 输出的格式为“流式”(flow style)。
详解:YAML::Flow 是一个常量,指示输出的 YAML 数据应接纳流式表现情势。
流式表现情势将聚集(如数组和映射)以更紧凑的方式表现,比方使用方括号 [] 表现数组,使用花括号 {} 表现映射。
使用场景:
当你想要以更紧凑的格式输出数据时,可以使用流式表现情势。相比于块状表现(block style),流式表现在视觉上更轻便,实用于小型数据结构或在单行内表现数据。
假设你有一个简朴的 YAML 数据结构,如果不使用 YAML::Flow,输出大概是如许的(块状表现):
| items:
- item1
- item2
| 而如果使用 YAML::Flow,此时,输出将是:
| items: [item1, item2]
|
示例代码:
#include <yaml-cpp/yaml.h>
#include <iostream>
int main() {
YAML::Emitter out;
out << YAML::Flow; // 设置为流式格式
out << YAML::BeginMap
<< YAML::Key << "items" << YAML::Value
<< YAML::BeginSeq
<< "item1" << "item2"
<< YAML::EndSeq
<< YAML::EndMap;
std::cout << out.str() << std::endl;
}
》》》》计划上的明白
1.Serialize
2.Yaml data
3.Deserialize
》》 There are few issues you need to know:
1.字符匹配:查找value所用的key必要正确无误,好比你想查找yaml文件中的 Fixed Aspect Ratio,你就必须用 Fixed Aspect Ratio 作为索引,而不是 FixedAspectRatio.
2.Map访问:如果你在map中查找此中存储的元素,你只能访问顶层的元素,而不能访问靠底层的元素。好比 CameraComponent
图例此时处于 cameraComponent,你通过这两个 key 访问此中的 value:Camera 和 Primary(好比调用 cameraComponent["Camera"] )。但是如果你想通过 CameraComponent 访问 projectionType,就不能使用 cameraComponent[" rojectionType"] 如许的语句,而必须使用 cameraComponent["Camera"]["rojectionType"],否则会报错。 rojectionType"] 如许的语句,而必须使用 cameraComponent["Camera"]["rojectionType"],否则会报错。
》》》》Cherno 将文件生存在 .hazel 后缀的文件中,这可以吗?为什么?只有Hazel 才气处置惩罚这种文件吗??
这取决于你的打开方式,如今 Hazel (大概 Nut) 有本事担当这种文件,通过我们界说的函数,Hazel(大概 Nut)通过文件流公道读入文件,然后辨认文件内容而且做出了相应操纵。如果你使用 word 打开这种文件,应用步调就会通过文本格式打开这个文件,如许也是被答应的,由于我们就是以文本的情势去设置了 yaml 文件。不外使用其他打开方式大概就会堕落。
》》》》注意事项/可改进事项
AND
------------------------------------------ Save/Open file dialog ----------------------------------------------
》》》》什么是 commdlg 库?
概念: commdlg.h 是 Windows API 中的一个头文件,它用于实现尺度对话框功能,如文件打开和文件生存对话框。这个头文件界说了与这些对话框相干的结构、常量和函数,使开发者可以大概方便地在应用步调中集成文件选择功能。
在使用 commdlg.h 时,通常会涉及到以下几个函数:
GetOpenFileName:
| 用于体现“打开文件”对话框。
| GetSaveFileName:
| 用于体现“生存文件”对话框。
|
》》》》 glfw3.h 和 glfw3native.h 这两个库之间的差异
差异:glfw3.h 和 glfw3native.h 之间的区别在于:glfw3.h 用于创建 glfw 范例的窗口, glfw3native.h 用于获取原生操纵体系中的窗口的句柄,以此来举行更底层的操纵。
1. <GLFW/glfw3.h>
目标:这是 GLFW 的紧张头文件,提供了创建窗口、处置惩罚输入、管理 OpenGL 上下文、以及其他与窗口和输入相干的功能。
内容:包罗了 GLFW 的全部核心功能,好比:创建和管理窗口和上下文、处置惩罚键盘、鼠标等输入变乱、管理 OpenGL 扩展、定时器等功能
| 2. <GLFW/glfw3native.h>
目标:这个头文件提供了平台特定的功能,通常用于访问底层原生窗口句柄或其他体系级别的功能。
内容:包罗了一些函数,这些函数答应你获取与操纵体系相干的窗口句柄。比方,在 Windows 体系上,你可以通过它得到 HWND 句柄;在 X11 上,你可以得到相应的 X11 窗口 ID。
使用场景:如果你必要与操纵体系的原生 API 举行交互(比方,在窗口中嵌入第三方控件,或与其他库集成),则大概必要使用这个头文件。
|
》》》》关于 glfw3native.h 和 #define GLFW_EXPOSE_NATIVE_WIN32
起首:glfwGetWin32Window() 是 glfw3native.h 中的函数(以下是其界说)。不外该函数在使用之前,必要通过界说 GLFW_EXPOSE_NATIVE_WIN32 将其暴袒露来。
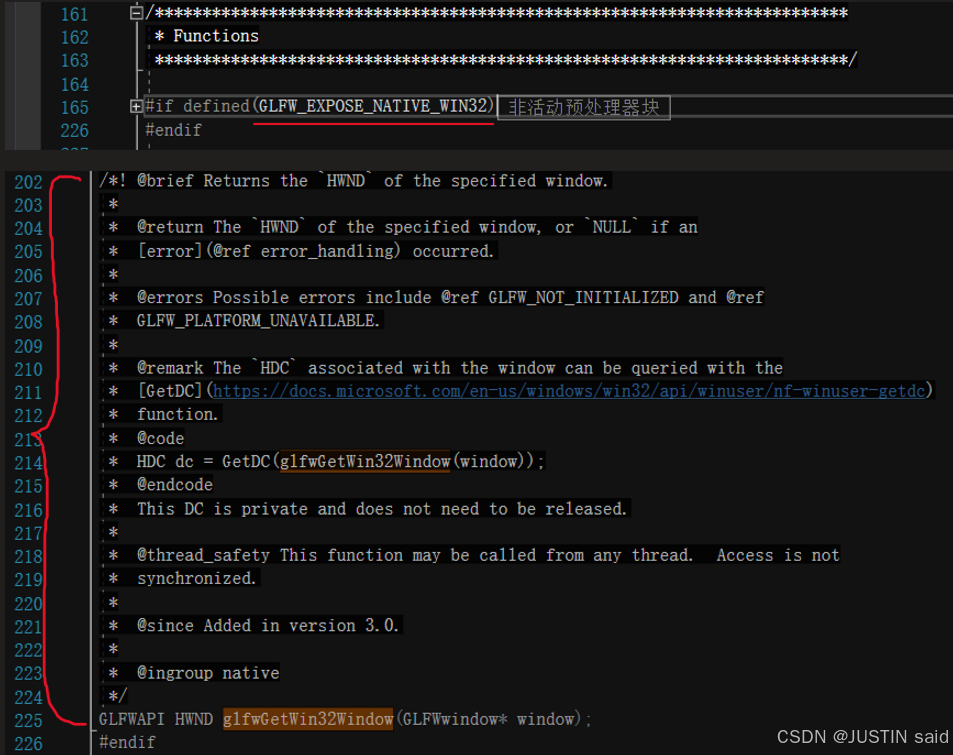
》》》》对话框函数计划思绪:
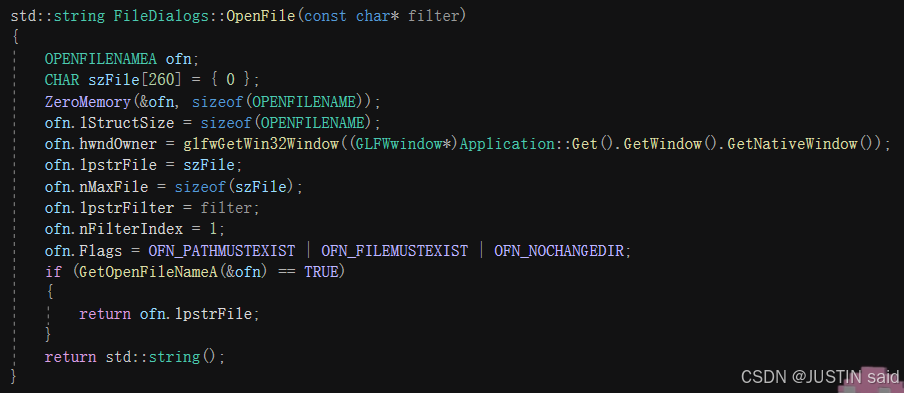
这个函数 FileDialogs::OpenFile 的作用是打开一个文件对话框,让用户选择一个文件,并返回所选文件的路径。
下面逐句表明代码的功能:(标蓝的函数/范例名/变量有额外条记)
std::string FileDialogs::OpenFile(const char* filter)
| 界说一个名为 OpenFile 的静态成员函数,担当一个字符串参数 filter,该参数用于指定文件范例过滤器(比方仅体现文本文件或图像文件 / 大概 Cherno 填入的:"Hazel Scene (*.hazel)\0*.hazel\0" )
| {
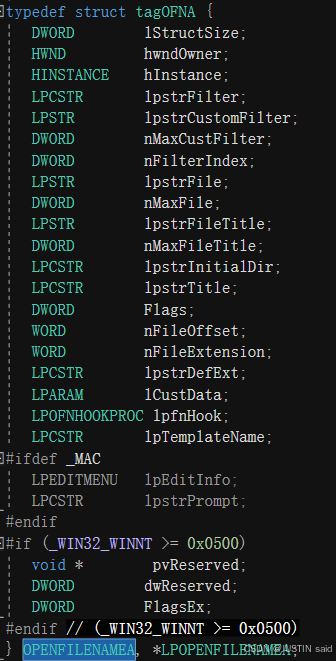
OPENFILENAMEA ofn;
| 创建一个 OPENFILENAMEA 结构体实例 ofn,该结构体用于存储文件对话框的各种信息。
| CHAR szFile[260] = { 0 };
| 声明一个字符数组 szFile,用于存储用户选择的文件路径,巨细为 260 字节(这是 Windows 体系中路径的最大长度限定)。
| ZeroMemory(&ofn, sizeof(OPENFILENAME));
| 将 ofn 结构体的内存清零,以确保它的全部字段都被初始化为零。
| ofn.lStructSize = sizeof(OPENFILENAME);
| 设置 ofn 结构体的巨细,以便 Windows 知道使用哪个版本的结构体
| ofn.hwndOwner = glfwGetWin32Window((GLFWwindow*)Application::Get().GetWindow().GetNativeWindow());
| 获取当前窗口的句柄并赋值给 ofn.hwndOwner,如许文件对话框会相对于这个窗口体现。
| ofn.lpstrFile = szFile;
| 将 szFile 的地点赋值给 ofn.lpstrFile,以便在用户选择文件后可以将文件路径写入这个数组中。
| ofn.nMaxFile = sizeof(szFile);
| 设置 ofn.nMaxFile 为 szFile 的巨细,以告诉对话框可以存储的最大路径长度。
| ofn.lpstrFilter = filter;
| 设置 ofn.lpstrFilter 为传入的 filter 参数,以界说可见的文件范例(比方 ".txt;.cpp")。
| ofn.nFilterIndex = 1;
| 设定过滤器的索引,通常设为 1 表现使用第一个过滤器。
| ofn.Flags = OFN_PATHMUSTEXIST | OFN_FILEMUSTEXIST | OFN_NOCHANGEDIR;
| 设置对话框的标志:
- OFN_PATHMUSTEXIST:用户选择的路径必须存在。
- OFN_FILEMUSTEXIST:用户选择的文件必须存在。
- OFN_NOCHANGEDIR:打开对话框时,不更改当前工作目次。
| if (GetOpenFileNameA(&ofn) == TRUE)
| 调用 Windows API 函数 GetOpenFileNameA 体现文件对话框。如果用户选择了一个文件,返回值为 TRUE。
| {
return ofn.lpstrFile;
}
| 如果文件选择乐成,返回 ofn.lpstrFile 中存储的文件路径。
| return std::string();
}
| 如果用户取消了操纵或发生错误,返回一个空的字符串。
|
《《 关于 OPENFILENAMEA 的界说
《《 关于 ZeroMemory 函数的界说
在 minwinbase.h 函数中:


《《 ofn.lpstrFilter = filter; 之中,filter 为什么是 const char* ? 填入的时间有什么规范?
lpstrFilter 格式
示例:
const char *filter = "Hazel Files (*.hazel)\0*.hazel\0All Files (*.*)\0*.*\0\0";
格式:
每一组文件范例形貌由两部门构成 -> 形貌字符串和扩展名字符串:
形貌字符串是用户在对话框中看到的文件范例名称,扩展名字符串指定了可以被选择的文件扩展名。各组之间用 \0 分隔,末了以两个 \0 竣事。
对话框怎样辨认和表现:
Hazel Files (*.hazel)\0*.hazel\0 -> 在文件对话框中,用户会看到“Hazel Files (*.hazel)”作为文件范例的选项。当选择这个选项后,对话框会过滤出全部以 .hazel 末了的文件。
All Files (*.*)\0*.*\0 -> 如果用户选择“全部文件 (.)”,则会体现全部文件,包罗 .hazel 文件。
比方:
Nut Scene(*.yaml) 为体现的文本提示,通常设置为你可以选择的过滤器,通过文本提示,代码会索引到符合的过滤器
.hazel 则会根据你选择的文本索引到你设置的过滤器,然后对全部文件举行过滤,如果符合.hazel 后缀,便体现在对话窗口中。
《《 GetOpenFileNameA 函数的作用:
GetOpenFileNameA 是 Windows API 中的一个函数,用于体现一个尺度的“打开文件”对话框,让用户选择一个文件。
函数原型
| BOOL GetOpenFileNameA(LPOPENFILENAMEA lpofn);
| 参数
| lpofn: 指向 OPENFILENAMEA 结构体的指针,该结构体包罗了对话框的设置信息和用户选择的文件路径。
| 返回值
| 如果用户乐成选择了一个文件并点击“确定”,函数返回非零值(通常是 TRUE)。
如果用户取消对话框或发生错误,返回值为零(FALSE)。可以通过调用 GetLastError 来获取更多错误信息。
|
《《 Flags 具体表明:
在 OPENFILENAME 结构体中,可以设置多个标志(Flags)来控制对话框的举动。
OFN_PATHMUSTEXIST:
| 寄义:用户输入的路径必须存在。如果用户在对话框中输入了一个路径(而不是从欣赏器中选择),这个路径必须是有效的。
触发环境:当用户输入一个不存在的路径并实验打开文件时,会出现错误提示,阐明路径无效。
| OFN_FILEMUSTEXIST:
| 寄义:用户选择的文件必须存在。纵然用户在对话框中选择了文件,如果该文件不存在,就会克制选择。
触发环境:当用户选择的文件实际上在磁盘上不存在时,体系会体现错误提示,阐明所选文件不存在。
| OFN_NOCHANGEDIR:
| 寄义:打开对话框时不改变当前工作目次。默认环境下,打开文件对话框大概会改变步调的当前工作目次以便于访问文件。
触发环境:这个标志的作用是确保选择文件后,步调的当前工作目次保持稳固,纵然用户选择了差异的文件路径。
|
《 关于 OFN_NOCHANGEDIR 的具体阐明
配景:在 Windows 应用步调中,当前工作目次是指步调在文件体系中默认访问的位置。当应用步调启动时,它会有一个初始的工作目次,通常是可实验文件地点的位置。
使用场景:
当用户打开文件对话框并选择一个文件时,默认环境下,Windows 会将当前工作目次更改为用户选择的文件地点的路径。这意味着如果用户选择了一个差异位置的文件,之后步调的全部文件访问操纵都会基于这个新的工作目次。
然而,在某些环境下,这种举动大概会导致标题。比方:
- 依赖于相对路径:如果步调中的文件操纵使用相对路径,工作目次的变革大概会导致文件访问失败。
- 多次调用:如果你的应用步调必要频仍打开文件,改变工作目次大概会使管理变得复杂,特别是在必要回到原始路径时。
假设你有一个文本编辑器应用步调,用户可以打开和编辑多个文件。在这个步调中,用户最开始大概在 C:\Documents 中打开一个文件。
OPENFILENAME ofn; // common dialog box structure
char szFile[260]; // buffer for file name
// Initialize OPENFILENAME
ZeroMemory(&ofn, sizeof(ofn));
ofn.lStructSize = sizeof(ofn);
ofn.hwndOwner = hwnd;
ofn.lpstrFile = szFile;
ofn.lpstrFile[0] = '\0';
ofn.nMaxFile = sizeof(szFile);
ofn.lpstrFilter = "Text Files\0*.TXT\0All Files\0*.*\0";
ofn.nFilterIndex = 1;
ofn.lpstrFileTitle = NULL;
ofn.nMaxFileTitle = 0;
ofn.lpstrInitialDir = NULL;
ofn.lpstrTitle = "Open File";
ofn.Flags = OFN_PATHMUSTEXIST | OFN_FILEMUSTEXIST | OFN_NOCHANGEDIR;
// Display the Open dialog box
if (GetOpenFileName(&ofn)) {
// 用户选择了文件
// 这里可以举行文件读取等操纵
}
在此示例中:
如果没有设置 OFN_NOCHANGEDIR,选择一个位于 D:\OtherFiles 的文件大概会把当前工作目次从 C:\Documents 改为 D:\OtherFiles。
这意味着接下来如果步调实验以相对路径访问文件(比方,读取 data.txt),它会在 D:\OtherFiles 查找,而不是在用户本来的路径 C:\Documents。
参加 OFN_NOCHANGEDIR 后的结果:
通过参加 OFN_NOCHANGEDIR,纵然用户选择了位于差异文件夹的文件,步调的当前工作目次仍旧保持在 C:\Documents。如许,任何依赖于该目次的文件操纵都不会受到影响。
》》》》标题:触发断点 -> 为什么将 CreateRef 改为 Ref 时会触发断点非常?
由于 Ref(std::shared_ptr<T>() ) 创建了一个智能指针,但未分配内存;
而 CreateRef(std::make_shared<T>() )创建并初始化一个智能指针,同时分配内存并构造对象。
》》》》关于快捷键触发这个变乱函数的计划:
1.GetRepeat() 在这里的作用:防止处置惩罚重复按键变乱。
e.GetRepeatCount() 函数用于获取按键的重复次数。当一个按键被按下并保持时(好比长按),操纵体系会不绝天生按键按下变乱,如许会导致该变乱被多次触发。
以是当检测到重复按键时,函数直接返回 false,意味着后续的代码(如处置惩罚快捷键的逻辑)将不会被实验。这可以防止同一个快捷键被多次触发,从而制止造成不测的重复操纵。
2.这个函数为什么只在变乱重复时返回一个布尔量,其他条件下不返回值呢。为什么 GetRepeat() 必要设置在函数最前面?
在变乱触发之后,我们运行实际逻辑代码(OpenScene/NewScene),但是我们不能返回 true,由于 true 不会克制变乱运行,这将会导致变乱会被一连触发。
其次,如果在逻辑代码之后返回 false,而不是在函数开头返回 false,都会导致变乱被触发第二次,由于在判定是否重复触发时仍旧会先运行逻辑代码,随后判定出来结果是 false(应该壅闭),不外此时已经没有效了。
3.GetKeyCode 和 GetRepeatCount 中返回的 keycode 和 count 是在那里自动获取的,以是我们才气使用其返回值来举行判定
在之前设置的回调函数中:WindowsWindow.cpp 中
4.为什么只有在鼠标单击了视口这个地区时(聚焦在 Viewport 窗口时),快捷键才气使用?
由于是在 EditorLayer::OnEvent() 函数中设置的变乱分发。
--------------------------------------- ImGuizmo ---------------------------------------------
》》》》这段 premake 代码什么意义?
》》》》为什么Nut-editor 中没有包罗 ImGui 库目次却可以使用 ImGui,但是没有包罗 yaml-cpp 库目次的时间却不能使用 yaml-cpp?
由于实际上 ImGui 在 "%{wks.location}/Nut/vendor" 中已经被包罗了。
》》》》代码计划:gizmo库中对于 ImGuizmo.cpp 的更改:( https://github.com/TheCherno/ImGuizmo/commit/218d60bde7d22061ac525d0d71e05360b4dcf978)
我意料Cherno做的是一些对于 ImGuizmo 样式的更改,而且由于时间缘故因由,最新的 ImGuizmo.cpp 结构发生了很多改变,这让我不轻易同步这个更改。
以是我决定先保持默认值,后续再查察是否必要同步此更改。
》》》》什么是万向锁,什么环境下会触发万向锁?什么是四元数,为什么四元数可以办理万向锁? glm/gtx/quaternion.hpp 中处置惩罚四元数的函数怎么使用?
万向锁(Gimbal Lock)
万向锁是一种在三维空间中旋转时碰到的征象,通常发生在使用欧拉角表现旋转的环境下。它指的是在某些特定的旋转设置下,体系的自由度镌汰,使得无法举行预期的旋转。
万向锁通常在以下环境下发生:
旋转轴对齐:
| 当一个旋转轴与另一个旋转轴对齐时,比方在俯仰角为 ±90° 时,两个旋转轴重合,这会导致体系失去一个自由度。
| 极限位置:
| 当物体到达某个极限位置(如竖立或程度),就大概会导致无法实现某些方向的旋转。
|
万向锁的影响:
当发生万向锁时,物体大概会无法按预期方向旋转,大概某些旋转会变得不可用。这在动画、飞行控制和呆板人活动等应用中会造成标题。
参考文档:( https://medium.com/@lalesena/euler-angles-rotations-and-gimbal-lock-brief-explanation-de1d4764170 )
参考图片:
https://miro.medium.com/v2/resize:fit:498/format:webp/1*7JT7g5dLeZ-Q5uOYnX8hCw.gif
https://miro.medium.com/v2/resize:fit:400/format:webp/1*OCkqKWmTtmDtzrukAX4hSA.gif
四元数(Quaternion)是一种扩展了复数的数学结构,通常用于表现三维空间中的旋转。它由一个实数部门和三个虚数部门构成,情势为:
q=w+xi+yj+zkq=w+xi+yj+zk
此中:w 是实数部门,x,y,z 是虚数部门(向量部门),i,j,k 是虚单元。
四元数通过以下方式办理万向锁标题:
四维表现:
| 四元数使用四个参数(一个实数和三个虚数)来表现旋转,而不是依赖于三个独立的角度(如俯仰、偏航和滚转)。这种表现方法制止了两条旋转轴重合的环境。
| 组合旋转:
| 四元数之间的乘法可以直接组合多个旋转,而不受单一旋转轴限定。这使得在任何方向上举行旋转都不会遭遇自由度的丧失。
| 插值平滑:
| 四元数支持球形线性插值(Slerp),这使得在动画中可以大概平滑地过渡旋转,从而制止因插值引起的万向锁标题。
|
参考文档---涉及到数理知识:( 3D数学:欧拉角、万向锁、四元数 - HighDefinition - 博客园 )
》》》》代码计划: TransformComponent 中的更改:
这可以防止通过 imGuizmo 调解物体旋转时图像极速发生变革的标题(通过 ImGuizmo 可视化工具轻轻更改欧拉角,角度却会极速增长,这会导致图像敏捷旋转并闪耀)
而且防止大概出现的万向锁标题(可以查察上述的: 万向锁(Gimbal Lock) )。
》》》》一些 ImGuizmo 函数:
》》》》 ImGuizmo::SetRect()
释义:ImGuizmo::SetRect() 是 ImGuizmo 库中的一个函数,用于设置 ImGuizmo 操纵地区的矩形。
在使用 ImGuizmo 举行变动操纵时,你必要界说一个矩形地区来限定 ImGuizmo 的界面和交互地区。这通常是你在应用步调中想要体现和使用的 GUI 地区。
函数原型: void SetRect(float x, float y, float width, float height);
参数分析:
x:
| 矩形地区的左上角的 X 坐标(屏幕坐标)。
| y:
| 矩形地区的左上角的 Y 坐标(屏幕坐标)。
| width:
| 矩形地区的宽度。
| height:
| 矩形地区的高度。
|
》》》》ImGuizmo::SetDrawList();
ImGui 的绘制列表
界说: 在 ImGui 中,绘制列表(ImDrawList)是一个存储了绘制下令的对象,包罗了要渲染的全部图形的信息(如线条、矩形、文本等)。
功能: 每个 ImDrawList 都包罗了多种画图下令和状态信息,比方:
顶点数据
颜色
纹理….
ImGuizmo::SetDrawList()
释义:
作用于 Gizmo:
| 这个函数的紧张作用是让 ImGuizmo 知道在哪个 ImDrawList 上举行绘制。这意味着,全部由 ImGuizmo 创建的图形(比方,表现变动的箭头、框和其他外形)都将被绘制到指定的绘制列表上。
| 控制绘制次序:
| 通过选择差异的绘制列表,开发者可以控制 gizmo 的绘制次序。比方,你可以将 gizmo 绘制在某个特定 UI 元素的上方或下方,如许可以实现更好的视觉结果和用户体验。
|
原型:static void SetDrawList(ImDrawList* draw_list);
参数:
draw_list: 指向 ImDrawList 的指针,这是一个 ImGui 的绘制列表,用于管理和记载图形的绘制下令。
示例:
ImDrawList* backgroundDrawList = ImGui::GetBackgroundDrawList();
ImDrawList* foregroundDrawList = ImGui::GetForegroundDrawList();
// 在配景绘制列表中绘制某个配景元素
backgroundDrawList->AddRectFilled(ImVec2(0, 0), ImVec2(100, 100), IM_COL32(50, 50, 50, 255));
// 在远景绘制列表中设置 gizmo 绘制
ImGuizmo::SetDrawList(foregroundDrawList);
ImGuizmo::SetRect(0, 0, ImGui::GetWindowWidth(), ImGui::GetWindowHeight());
ImGuizmo::Manipulate(viewMatrix, projectionMatrix, ImGuizmo::OPERATION::TRANSLATE, ImGuizmo::MODE:OCAL, &modelMatrix[0][0]);
》》》》 ImGuizmo::Manipulate()
释义:ImGuizmo::Manipulate 是 ImGuizmo 库中用于处置惩罚物体变动的函数。这个函数可以在用户界面中答应用户通过拖动来对物体举行平移、旋转和缩放操纵。
函数原型:
bool Manipulate(const float* view, const float* projection,
OPERATION operation, MODE mode,
float* matrix, float* deltaMatrix,
const float* snap = nullptr, const float* pivot = nullptr);
参数分析:
view:
| 相机的视图矩阵(cameraView),表现相机的位置和方向。
| projection:
| 相机的投影矩阵(cameraProjection),用于确定场景中物体的透视结果。
| operation:
| 变动操纵范例(平移、旋转或缩放),通过 (ImGuizmo::OPERATION)m_GizmoType 指定。
| mode:
| 变动模式,通常是 ImGuizmo:OCAL(局部变动)或 ImGuizmo::GLOBAL(全局变动)。
| matrix:
| 物体的变动矩阵(transform),表现物体在场景中的位置、旋转和缩放。
| deltaMatrix:
| 可选参数,表现变革的矩阵。
| snap:
| 可选参数,指定对变动举行捕获的值(比方,步长)。如果为 nullptr,则不举行捕获。
| pivot:
| 可选参数,指定旋转的中心点。
|
》》》》ImGuizmo::OPERATION 的界说
》》》》代码计划:窗口相应
更改前:只要不满足 聚焦于窗口上/悬停在窗口上 的任逐一个条件,便会壅闭当前窗口中的变乱(不再捕获鼠标或键盘的活动)
更改后:只有 窗口没有被聚焦且鼠标没有悬停在窗口上的时间,才会壅闭变乱。
这让我们在结构面板中选中实体之后,只必要将鼠标悬停在 viewport 窗口上,便可以通过键盘调解/相应 Gizmo,这在实际使用中很舒服( 本人亲测 :>
》》》》为什么这里必要使用 Const 标识?
大概是由于不必要对 cameraComponent 举行更改吧。
》》》》这个函数的意义?
》》》》这段代码的意义?
------------------------------------ Editor camera ------------------------------------------
》》》》 关于引擎的操纵界面和简朴使用,我们已经完成了很多,Cherno 在接下来将开始实现鼠标选择实体,不外我大概会将之前遗漏的维护增补一下。
》》》》总之先让我们开始这一集吧。
》》》》这一会合,紧张围绕 编辑时摄像机 和 运行时摄像机 两个概念来计划。
我现在是如许明白的:
- 编辑时摄像机:用于在引擎中编辑物体,此摄像机为默认存在。只要你必要对物体举行编辑,那么直接创建一个 sprite 实体,在编辑器中便应该可以大概直接查察和编辑该实体,而不必要额外添加摄像机(运行时摄像机),这符合游戏引擎的使用逻辑。
- 运行时摄像机:用于在实际游戏步调运行时添加,此摄像机必要手动添加。游戏中不必要“天主视角”的编辑时摄像机,而只必要用来观察物体的运行时摄像机,该摄像机不像编辑时摄像机一样默认存在,由于编辑器和游戏步调的逻辑是差异的。
这两个摄像机不是同时存在的:在编辑器中,底层默认存在一个编辑时摄像机,该相机只在编辑器运行时存在并更新;同样的,游戏步调中不使用编辑时摄像机,而是用运行时摄像机,该相机只在游戏步调运行时存在并更新。
由于我们如今在编辑器中计划步调,以是只必要对全部实体使用编辑时摄像机即可。对于游戏,我想我们应该必要在编辑器中添加一个游戏运行时摄像机,然后打开游戏步调,举行嬉戏。
---------------------------- Multiple Render Targets and Framebuffer refactor----------------------------------
》》》》好久没 commit 了,之前预备先做维护,怎样 Cherno 背面实现的内容太过诱人,好奇心驱策我又观看了五六集,维护的事变背面再说吧 X-D
》》》》接下来我将积极实现 Mouse Picking,然后根据个人时间思量内容欣赏面板的制作,大概是提交一波维护,由于维护已经落下好久了。
》》》》前言:
》》》》gl_VertexID 在 GLSL 中关于顶点ID的一些细节:
》》》》这一节的概述:
Cherno 为了实现类似顶点ID的结果,于是开始更改帧缓冲的操纵模式。如许一来就可以更方便的实现鼠标选中,在这一节中,Cherno 只是对帧缓冲的实现过程举行了美满,使代码可以通过初始化列表标识帧缓冲,并自动的辨认这些标识用来创建帧缓冲。固然是顶点ID的前瞻操纵,但实际上只是一些铺垫,不必担心看不明白。
》》》》代码的明白:
反复观看代码之后,我将全部代码分为两部门:设置结构体 和 重构帧缓冲的创建,第一部门的作用是:通过声明一些结构体来简化帧缓冲的使用方式/简化帧缓冲的计划,第二部门的作用是:通过已有的条件,动态的构建帧缓冲。
这引出了我的一些标题:
In FrameBuffer.h
》》这三个结构体有什么作用?之间有什么关系?
FramebufferTextureFormat:
| 这个罗列类界说了可用的帧缓冲纹理格式
| FramebufferTextureSpecification:
| 一个使用罗列范例对象举行初始化的类,用于界说单个帧缓冲纹理的具体规格
| FramebufferAttachmentSpecification:
| 用于界说一组帧缓冲的附件
(我以为这个结构体紧张是用来服务于初始化的:好比 Cherno 的代码中的使用方式)
(再好比:)
由于这个 FramebufferAttachmentSpecification 的构造函数中使用的是初始化列表,以是我们可以通过上述方式对 framebufferSpecification 中的 Attachments 举行方便快捷的初始化操纵。
填入的初始化列表将被储存在 FramebufferSpecification 结构体中的 Attachments 中:
并在 OpenGLFramebuffer 的构造函数中被使用:(第一个 Attachments 就是 FramebufferSpecification 结构体中的成员,第二个 Attachments 则是 FramebufferAttachmentSpecification 结构体中的成员->查察最开始的那张代码表)
|
In OpenGLFrameBuffer.h
》》m_ColorAttachmentSpecification 和 m_ColorAttachments 的区别在那里?分别起到什么作用?
前言:帧缓冲中的纹理与纹理附件的关系?帧缓中是否可以包罗多个纹理?一个纹理中是否可以附加多个纹理附件?这些附件有什么作用?
一个帧缓冲绘制的场景中可以绘制一些物体,也可以绘制多个纹理,而纹理附件则是存储这些渲染结果的地方。此时如果你使用帧缓冲中的颜色附件作为纹理举行后续渲染,那这个颜色附件就可以被称为纹理附件。
在帧缓冲中每一个纹理的创建都宁静凡纹理的创建过程差不多,不外我们必要对这些纹理额外的附加 Attach 一些附件。一个纹理可以附加多个附件(颜色附件可以同时附加多个,但深度附件一样平常只能附加一个),如果你在帧缓冲对象(FBO)中使用多个颜色附件,那并不意味着你能绘制更多的物体,而是指在一次渲染过程中,你可以同时输出多个数据流。
m_ColorAttachmentSpecification 用于存储全部的纹理附件,而 m_ColorAttachments 存储的是帧缓冲中全部纹理附件的 ID 。
》》那么这个ID是怎么分配的呢?
在举行附件的附加操纵时,先有如许一句代码:m_ColorAttachments.resize(m_ColorAttachmentSpecifications.size());
| 此中 m_ColorAttachmentSpecifications.size() 返回的是 vector 中的元素数量(即纹理附件的数量),云云一来 m_ColorAttachments 的巨细就被初始化为 m_ColorAttachmentSpecifications 中的元素数,数据全部为 0.
| 在随后的代码:
Utils::CreateTextures(multisample, m_ColorAttachments.data(), m_ColorAttachments.size()); 中
| CreateTextures 调用了glCreateTextures(TextureTarget(multisampled), count, outID); 这会在函数被调用的过程中自动为纹理分配 ID,这个 ID 正是我们填入的 m_ColorAttachments.data()
( 从一开始的全部为0到创建完纹理之后 gl 函数自动分配的 ID)
|
》》这个 ID 是怎样和片断着色器中的输出变量 Color 关联起来的?也就是说纹理附件的 ID 是怎样和片断着色器中的输出变量关联起来的?
好比 Cherno 是怎样明白纹理附件的 ID:0 就指的是片断着色器中的第1个颜色(输出变量),ID:1就指的是片断着色器中的第2个颜色(输出变量)。
Eg.
通过纹理 ID 索引到纹理附件
1 Utils::CreateTextures
(multisample, m_ColorAttachments.data(), m_ColorAttachments.size());
| 起首将一组纹理创造出来,为其分配对应的ID
| 2 Utils::BindTexture(multisample, m_ColorAttachments);
| 在 BindTexture 函数中,填入对应的纹理 ID 作为参数,在明白绑定了某一个纹理的环境下,将为该纹理分配附加附件(在此根本上使用 AttachColorTexture 函数,将输出变量 Color 映射到颜色附件 0(GL_COLOR_ATTACHMENT0))
| 3 Utils::AttachColorTexture
(m_ColorAttachments, m_Specification.Samples, GL_RGBA8, m_Specification.Width, m_Specification.Height, i);
| 在该函数的具体实现中,通过:glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0 + index, TextureTarget(multisampled), id, 0); 我们明白表现了在某一纹理的条件下,为其绑定的附件。
GL_COLOR_ATTACHMENT0 便是帧缓冲对象的第一个颜色附件。我们将该附件按次序的附加到对应的纹理ID下。
|
通过纹理附件(颜色附件)索引到输出变量
如今我们已经可以通过纹理 ID 索引到想要访问的纹理附件了,可怎样将 ID 与片断着色器中的颜色输出变量接洽起来?
渲染目标的设置:在使用多重渲染目标(MRT)时,可以将片断着色器的输出变量映射到差异的颜色附件。
GLenum drawBuffers[2] = { GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1 };
glDrawBuffers(2, drawBuffers);
| 这将把 Color0 的输出写入到 GL_COLOR_ATTACHMENT0,而 Color1 的输出写入到 GL_COLOR_ATTACHMENT1。
|
Eg.
》》》》代码上的疑问:为什么必要在附加附件之前创建纹理
为什么每附加一个附件就必要创建一次纹理?
条件:
| Utils::CreateTextures 函数的作用是创建纹理对象,具体来说就是为帧缓冲区的颜色附件和深度附件分配和初始化须要的纹理资源。一个纹理可以包罗多种差异的附件。
| 缘故因由:
| 由于创建纹理是渲染管线中的关键步调,为了确保在绘制时渲染结果可以储存在符合的纹理中,我们必要创建纹理。
|
固然一个纹理对象可以附加多个颜色附件,且只能附加一个深度附件,那为什么必要在附加深度缓冲附件之前再次新建一个纹理?
这些纹理都代表什么,为什么可以创建这么多?
颜色附件和深度附件的规范
颜色附件:
| 数量:颜色附件用于存储渲染输出的颜色信息。可以有多个颜色附件,由于在很多渲染管线中,大概必要输出多个颜色通道(比方,颜色缓冲、法线缓冲、光照缓冲等)。
附件和纹理的关系:每个颜色附件可以使用差异格式的纹理,如许可以根据需求选择最符合的格式和精度。
| 深度附件:
| 数量:深度附件用于存储每个像素的深度信息,用于举行深度测试以判定哪些物体在前面、哪些在背面。在一个帧缓冲对象中只能有一个深度附件,这通常是由于深度测试只必要一个深度值来举行比力。
|
创建多个纹理的缘故因由
性能和机动性:
| 使用差异的纹理对象答应开发者根据必要选择差异的格式、分辨率和精度。比方,大概会盼望使用高精度深度纹理,但对于颜色输出,可以选择较低精度的纹理。
| 资源管理:
| 创建多个纹理可以更好地管理内存和资源。根据差异的渲染需求,可以动态创建和烧毁纹理,而不是固定使用一个纹理。
| 多重渲染目标(MRT):
| 当使用多重渲染目标(MRT)时,可以同时将多个颜色输出渲染到差异的纹理。这种机动性可以优化渲染流程,镌汰多次绘制的需求。
|
在深度附件之前创建纹理的缘故因由
指定深度格式:
| 每个深度附件大概使用差异的格式(如深度16、深度24等),必要根据必要新建得当的纹理。
| 资源隔离:
| 将颜色和深度缓冲分开,可以更轻易地管理和调试渲染过程。
|
》》》》附件的附加代码:附加时使用差异函数的意义是什么?
两种附件中使用的函数 : glTexImage2D 和 glTexStroage2D 区别在那里?
1. 创建纹理存储的方式
AttachColorTexture 中使用 glTexImage2D:
| glTexImage2D(GL_TEXTURE_2D, 0, format, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, nullptr);
这里调用 glTexImage2D 为纹理分配存储,而且在创建时可以上传像素数据(固然这里通报的是 nullptr)。
它得当必要动态更新纹理内容的环境,由于你可以在后续的调用中修改纹理数据,但是调用时大概会重新分配内存。
| AttachBufferTexture 中使用 glTexStorage2D:
| glTexStorage2D(GL_TEXTURE_2D, 1, format, width, height);
这里使用 glTexStorage2D 创建了一个不可变的纹理存储。调用这个函数时,你只指定了格式和尺寸,之后不答应改变存储结构。
它更得当静态纹理,由于它只必要在创建时分配一次内存,而且不必要再举行二次的内存分配和管理。
|
实用场景:
glTexImage2D
| 得当于动态纹理,比方实时渲染时必要频仍更新的纹理颜色或样式…. 。
| 优劣:
| 可以大概机动地上传和更新纹理数据,但大概导致性能降落。
| glTexStorage2D
| 更得当静态纹理,如用于环境映射、天空盒或其他不必要在运行时修改的纹理。
| 优劣:
| 可以大概提供更好的性能和内存管理,但必要在创建时就确定纹理的格式和尺寸,之后不再改变。
|
》》关于纹理创建和附加操纵的一点明白:
1 由于颜色附件(纹理附件)必要附加多个,以是必要创建多个纹理,并逐一对其举行 Attach 操纵。
2 但是深度附件只必要添加一个,以是只创建一个纹理,并对其举行一次 Attach 操纵。
》》》》以下两段代码的区别
和
的区别:
答:Size > 1 是数量从 2 开始的环境,!empty() 是数量只要不为0,也就是数量从 1 开始的环境。
》》》》glDrawBuffers 函数的作用是什么?
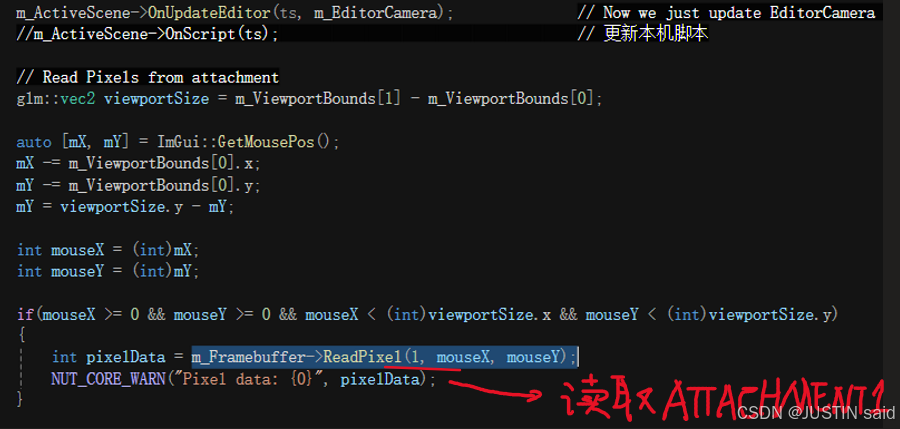
--------------- Preparing mouse picking (Get mouse pos and Read pixel) ---------------------------------
》》》》关于这一集,可以分为三部门:1.调解帧缓冲的使用方法 2.读取当前帧缓冲区(或指定帧缓冲区)中的像素数据 3.获取正确的窗口巨细界限,并获取鼠标相对于窗口中的位置
》》》》关于读取当前帧缓冲区(或指定帧缓冲区)中的像素数据
glReadBuffer
原型:
| void glReadBuffer(GLenum src);
| 参数:
| 这些选项指定了你盼望读取的帧缓冲对象(FBO)中的缓冲区。
src(范例:GLenum):指定你盼望读取的源缓冲区。这个参数的有效值有:
- GL_FRONT_LEFT:从前面左侧的颜色缓冲区读取(传统的前台缓冲区,OpenGL 默认的缓冲区之一)。
- GL_FRONT_RIGHT:从前面右侧的颜色缓冲区读取(如果双缓冲渲染)。
- GL_BACK_LEFT:从背面左侧的颜色缓冲区读取(通常用于双缓冲模式)。
- GL_BACK_RIGHT:从背面右侧的颜色缓冲区读取(如果双缓冲渲染)。
- GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1, ... GL_COLOR_ATTACHMENTn:从多个渲染目标中的颜色附件中读取,这个是今世 OpenGL(FBO)中常用的选择。
- GL_DEPTH_ATTACHMENT:从深度缓冲区读取。
- GL_STENCIL_ATTACHMENT:从模板缓冲区读取。
| 释义:
| glReadBuffer 的紧张作用是指定从哪个缓冲区读取数据。
这在多渲染目标(MRT, Multiple Render Targets)或使用帧缓冲对象(FBO)时非常有效,由于在这些环境下,你大概渲染到多个差异的缓冲区,而且必要从特定的缓冲区获取像素数据。
|
glReadPixels
原型:
| void glReadPixels(GLint x, GLint y, GLsizei width, GLsizei height, GLenum format, GLenum type, void *pixels);
| 参数阐明:
| x:读取地区左下角的 X 坐标,单元是像素。指定从帧缓冲中开始读取的位置。
y:读取地区左下角的 Y 坐标,单元是像素。指定从帧缓冲中开始读取的位置。注意,在 OpenGL 中,Y 轴的坐标是从底部到顶部增长的,以是 y 的值越大,读取的地区就越靠上。
width:指定要读取的地区的宽度(以像素为单元)。
height:指定要读取的地区的高度(以像素为单元)。
举例(width, height)
读取地区巨细:指定从 (x, y) 开始的地区为 1 像素宽,1 像素高,即仅读取一个像素的数据。
实际结果:这意味着你会读取帧缓冲区中 x, y 位置处的单个像素的颜色信息。
读取地区巨细:指定从 (x, y) 开始的地区为 100 像素宽,100 像素高,即读取一个 100x100 像素的矩形地区内全部像素的数据。
实际结果:这意味着你会读取从 (x, y) 开始,横向 100 个像素,纵向 100 个像素的地区内全部像素的颜色信息。
format:指定返回像素数据的格式,常见的有:
- GL_RGB:以 RGB 格式返回数据。
- GL_RGBA:以 RGBA 格式返回数据。
- GL_DEPTH_COMPONENT:返回深度值(通常是一个浮点数值)。
- GL_STENCIL_INDEX:返回模板缓冲区的值。
type:指定返回数据的范例。常见的范例包罗:
- GL_UNSIGNED_BYTE:每个像素的每个分量用一个无符号字节(0~255)表现。
- GL_FLOAT:每个像素分量用浮点数表现(0~1 范围)。
- GL_UNSIGNED_SHORT:每个像素分量用无符号短整数表现(通常是 16 位)。
- GL_UNSIGNED_INT:每个像素分量用无符号整数表现(通常是 32 位)。
pixels:指向存储读取像素数据的内存地区的指针。读取到的像素数据将被存储在这个内存空间中。该内存的巨细应该充足容纳全部读取的像素数据。
| 释义:
| glReadPixels 是 OpenGL 中用于读取当前帧缓冲区(或指定帧缓冲区)中的像素数据的函数。
它通常用于从渲染到屏幕或帧缓冲的内容中提取像素信息,可以用于后处置惩罚、截图、或用于其他必要读取像素数据的操纵。
|
》》》》关于窗口和鼠标交互部门代码的明白
// 确定窗口界限(思量标签栏)
auto viewportOffset = ImGui::GetCursorPos(); // Includes tab bar
auto windowSize = ImGui::GetWindowSize();
ImVec2 minBound = ImGui::GetWindowPos();
minBound.x += viewportOffset.x;
minBound.y += viewportOffset.y;
ImVec2 maxBound = { minBound.x + windowSize.x, minBound.y + windowSize.y };
m_ViewportBounds[0] = { minBound.x, minBound.y };
m_ViewportBounds[1] = { maxBound.x, maxBound.y };
// 确定鼠标在视口中的相对位置,并做出对应的操纵
auto[mx, my] = ImGui::GetMousePos();
mx -= m_ViewportBounds[0].x;
my -= m_ViewportBounds[0].y;
glm::vec2 viewportSize = m_ViewportBounds[1] - m_ViewportBounds[0];
my = viewportSize.y - my;
int mouseX = (int)mx;
int mouseY = (int)my;
if (mouseX >= 0 && mouseY >= 0 && mouseX < (int)viewportSize.x && mouseY < (int)viewportSize.y)
{
int pixelData = m_Framebuffer->ReadPixel(1, mouseX, mouseY);
HZ_CORE_WARN("ixel data = {0}", pixelData);
}
----- ImGui::GetCursorPos()
ImGui::GetCursorPos()
| 作用: 获取光标位置:返回当前光标在窗口中的位置,通常在结构过程中用于对齐和分列控件。
返回值:返回 ImVec2 范例变量,表现光标的 x 和 y 坐标。返回值的 x 和 y 是相对于当前窗口的左上角的坐标,单元为像素。
|
注意
ImGui::GetCursorPos() 返回的是 ImGui 光标的位置,而不是鼠标光标的位置。这里的“ImGui 光标”是一个特定的概念,与 GUI 元素的结构和绘制有关。
ImGui 光标
概念:在 ImGui 中,光标是用于管理和控制 UI 元素(如按钮、文本框、滑动条等)分列和绘制的一个指示器。它并不是真正的鼠标光标,而是指示下一个元素应该放置在那边的捏造光标。
特性:
结构控制:
| ImGui 使用即时模式的绘制方式,光标资助管理 UI 元素的分列。每当你在 ImGui 中绘制一个元素时,光标的位置会自动更新,指向下一个可放置元素的位置。
比方,当你调用 ImGui::Button("Button") 时,按钮会被绘制在当前光标的位置。
| 位置更新/使用方式:
| 每当添加一个新的 UI 元素时,光标会自动向下移动,预备好放置下一个元素。
比方,你可以通过 ImGui::GetCursorPos() 获取当前光标的位置。
| 光标的偏移:
| 光标位置可以通过多种方式调解。
比方,可以使用 ImGui::SetCursorPos() 函数手动设置光标位置,大概通过调用 ImGui::NewLine() 来逼迫光标换行。
| 相对坐标:
| GetCursorPos() 返回的是相对于当前窗口的光标位置,这意味着它会思量到窗口的结构(如标签条、边距等),并返回一个相对位置。
|
实际应用:
当你在 ImGui 中创建界面时,通常不会直接处置惩罚鼠标光标的位置,而是依赖于 ImGui 光标自动控制 UI 元素的结构。
Eg.
ImGui::Text("Hello, World!");
ImGui::Button("Click Me!");
在这个例子中,Text 和 Button 会根据 ImGui 光标的位置自动分列。当第一个元素被绘制后,光标会向下移动,按钮会出如今文本的下方。
ImGui光标的格式
坐标格式:
| ImGui 光标的位置是一个具体的坐标,表现相对于当前窗口的左上角((0, 0) 点)的位置。
这个坐标通常是以像素为单元的,并以 ImVec2 范例返回,此中包罗两个浮点值:x 和 y,分别表现程度方向和垂直方向的坐标。
|
----- ImGui::GetWindowSize()
ImGui::GetWindowSize()
| 返回当前窗口的宽度和高度(ImVec2),便于在绘制控件时举行相应的结构。
|
----- ImGui::GetWindowPos()
ImGui::GetWindowPos();
| 作用:获取当前 ImGui 窗口的位置信息,通常用于确定窗口在屏幕上的位置。
坐标位置:返回当前窗口左上角相对于屏幕的坐标位置,便于举行结构和处置惩罚鼠标变乱等。
|
----- ImGui::GetMousePos()
ImGui::GetMousePos()
| 返回当前鼠标光标在屏幕上的坐标(全局坐标)
|
《《代码明白:为何以下代码可以动态的盘算出视口(窗口)的可用地区?(动态:指的是可以根据标签栏是否存在,盘算出此时的窗口可用地区)
auto viewportOffset = ImGui::GetCursorPos(); // Includes tab bar
ImVec2 minBound = ImGui::GetWindowPos();
minBound.x += viewportOffset.x;
minBound.y += viewportOffset.y;
根据上述 GetWindowSize() 函数的明白,我们得知这个函数返回的是 ImGui 光标的位置。这个光标纪录了 ImGui 控件的位置,当便签栏存在时,这个函数返回的值会发生变革(无标签栏时返回可用地区的左上角坐标;有标题栏的时间,会由于窗口中多绘制的标题栏控件,而返回已经发生变革的坐标)
(全局坐标 + 相对坐标 -> 符合需求的全局坐标)
由于 ImVec2 minBound = ImGui::GetWindowPos() 这里得到的是窗口在屏幕中的全局坐标,而 ImGui::GetCursorPos() 得到的是控件在窗口中的相对坐标,以是对于这个全局坐标,我们加上相对坐标,便可以盘算出控件存在时的可用范围。
无标签栏时:
有标签栏时:
《《 代码明白:怎样盘算的相对坐标(相对坐标->指的是将鼠标的全局位置修改为相对于视口窗口的坐标,正确位置相对于视口窗口的左上角。由于对于鼠标坐标,我们都对其减去了minBound)
auto[mx, my] = ImGui::GetMousePos();
mx -= m_ViewportBounds[0].x;
my -= m_ViewportBounds[0].y;
(全局坐标 - 全局坐标 = 对于窗口的相对坐标)
盘算全局鼠标坐标相对于窗口的位置,好比:假设全局鼠标坐标是 (500, 300),窗口左上角的坐标是 (450, 250)。通过盘算:
mx = 500 - 450 = 50
my = 300 - 250 = 50
这表明,鼠标在窗口中的位置是 (50, 50),即间隔窗口左上角50像素的位置。
》》》》一个小Bug:(白色小光标表现鼠标位置)
正确的操纵:
错误的操纵:当鼠标在视口中,但是鼠标位于视口靠上方时,会出现无效值。
发生这个错误的缘故因由是:ImGui::GetWindowSize() 获取的是整个窗口的尺寸,包罗边框和标题栏等。而我们必要的窗口的客户端地区尺寸不包罗能边框,否则在盘算鼠标相对与窗口左上角的位置坐标时,我们获取的坐标 mouseX , mouseY 会发生偏移,想要办理这个标题,就应该使用 ImGui::GetAvailableRegion() 来获取窗口尺寸。
而 m_ViewportSize 恰恰是如许获取的。
》》》》疑问:
疑问1.0:为什么必要特别盘算一个 viewportSize ,以此作为判定依据呢?为什么不可以按照 maxBound 来判定呢?
好比如许:
答:由于 m_ViewportBounds[1] 中存储的 maxBound 是屏幕全局中的坐标,而这里我们获取的鼠标坐标是颠末处置惩罚的视口相对坐标,以是如果必要举行条件判定,则必须按照 minBound 和maxBound 盘算出从[0,0] 开始的整个视口的相对坐标,并将其作为判定依据。
疑问1.1:但是ReadPixel中也填写了mouseX,MouseY这两个相对坐标,这是否正确?
正确,由于这个函数是使用在 Framebuffer 之下的,我们使用 mouseX 和 mouseY 来读取视口中的数据。固然 mouseX,MouseY 并不是整个屏幕上的绝对坐标,但他们是窗口上的相对坐标。由于窗口完全被视口添补,且这个坐标的巨细也被限定在视口的尺寸之内,以是这两个坐标可以表现视口("Viewport"这个窗口)中的位置,因此这个函数参数的使用是正常的。
疑问2:这里对于坐标举行整形转化的用意是什么?不做会怎样?
int mouseX = (int)mX;
和
int mouseY = (int)mY;
| mX 和 mY 在前面是通过 ImGui::GetMousePos() 获取的鼠标位置,它们是浮动值(通常是 float 范例),表现鼠标在视口中的相对坐标。
由于图像或像素通常以整数坐标来举行处置惩罚,浮动值对它们没有直接的意义。以是通常必要将浮动型的鼠标坐标转换为整数,才气用于像素访问或图像读取等操纵。
| (int)viewportSize.x
和
(int)viewportSize.y
| viewportSize.x 和 viewportSize.y 是 float 范例的值,但在举行鼠标坐标查抄时,视口的宽度和高度应该是整数,如许才气与已经转换为整数的 mouseX 和 mouseY 举行比力,确保鼠标坐标在有效的范围内。
|
《《《《 Tips: You can use ( ImGui::GetForegroundDrawList()->AddRect(minBound, maxBound, IM_COL32(255, 255, 0, 255)); ) to draw the available region with colored rectangle
--------------------------------Clear texture attachments & Support multiple entity IDs--------------------------------------------
》》》》这一次我要提交两个部门:打扫和多个实体ID(打扫指的是将空缺地区的鼠标输出改为:-1,多实体地区指的是每一个实体都将拥有一个ID,作为鼠标输出)
》》》》一些当下的明白:
当前,我们创建了一个帧缓冲对象,而且为其创建了两个颜色附件(纹理附件):RGBA8、RED_INTEGER,一个深度附件、一个模板附件。
此中颜色附件的RGBA8被用来绘制物体,RED_INTEGER被用来储存或处置惩罚实体ID。
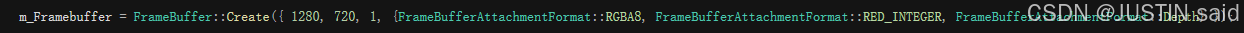
而且由于我们使用了批渲染,以是理论上全部渲染的物体应该是一个团体,以是不消使用多个颜色附件。
在实际的代码操纵中,我们会根据 FrameBuffer::Create 填入的参数次序来分配附件索引,也就是说:

云云一来,我们可以访问差异附件插槽上的数据,如果此时我们在着色器中设置了 color2 ,并将其作为 Attachment1,就可以读取到我们在着色器中对其设定的值。(此处示例为 color2 = 50)


如果我们选择在特定环境下读取该附件的内容,并打印,才会有类似的结果。
但是只有鼠标停顿在窗口中已绘制的物体上时,才可以访问到有效的 Attachment (如果鼠标停顿在窗口内空缺地区,此处没有绘制物体,而附件 Attachment 又恰恰是在绘制一个物体时才创建的,以是此时打印的值是无效数字 : 1036831949)
如果此时想打扫空缺地区的无效数字,则必要在访问全部地区之前,使用 ClearTexImage() 清空全部数据(使用 ClearTexImage() 将 Attachment0 + index 这里的数据临时更改为指定值:-1),如许一来当鼠标位于空缺地区时,就会返回我们设置的值。(如果后续鼠标会位于物体上,我们只必要使用函数 ReadPixel() 重新读取 Attachment0 + index 存放的值即可。)
》》》》关于 glClearTexImage()
glClearTexImage()
作用:
| 是 OpenGL 4.5 引入的一个函数,它答应你直接打扫纹理(texture)对象的内容(颜色、深度、模板或其他范例的数据),而不必要绑定纹理到帧缓冲区。
这个函数提供了一种更高效的方式来打扫纹理的内容,,制止了传统的方式(通过帧缓冲区绑定打扫纹理)所带来的额外开销,这在图形渲染管线中尤其非常有效。
| 函数原型:
| void glClearTexImage(GLuint texture, GLint level, GLenum format, GLenum type, const void *data);
| 参数阐明:
| 要打扫的纹理对象的名称。纹理对象在创建时通过 glGenTextures 获取的 ID。该纹理对象必须是有效的。
指定纹理的级别(level)。对于通例纹理,level 通常是 0,表现根本级别。对于多级渐远纹理(Mipmap textures),level 表现打扫哪个 mipmap 级别的纹理。
指定打扫时所使用的数据格式。常见的格式包罗:
GL_RED, GL_RG, GL_RGB, GL_RGBA 等。
GL_DEPTH_COMPONENT, GL_STENCIL_INDEX, GL_DEPTH_STENCIL 等用于深度和模板缓冲区的格式。
指定打扫时所使用的数据范例。常见的数据范例包罗:
GL_UNSIGNED_BYTE, GL_FLOAT, GL_INT 等。
该范例应该与 format 兼容。
指向一个数据缓冲区的指针,包罗用于打扫纹理的值。这个值的格式和范例必须与 format 和 type 相匹配。
常见用途:data 大概是一个添补了特定打扫值的数组。比方对于 format = GL_RGBA 格式,可以将其设置为一个数组(比方:{0.0f, 0.0f, 0.0f, 1.0f}),以打扫纹理为透明玄色。
在此处我们将 format = GL_RED_INTEGER ,data = -1,表现我们将 GL_ATTACHMENT1(或其他位置)存储的 GL_RED_INTEGER 打扫为-1
- data (const void *):
- type (GLenum):
- format (GLenum):
- level (GLint):
- texture (GLuint):
|
------------------------- Unique Entity ID for mouse picking (Mouse picking) -----------------------------
》》》》这一次提交的紧张思绪为:为顶点再添加一个属性 -> EntityID,这个 EntityID 会被实体默认天生的ID所填入,进而在顶点中标识某一个实体,我们也可以访问到。
具体思绪是:
1. 确定新的顶点属性 layout( location = 5) in int a_EntityID
2. 根据这个新增的顶点属性,我们起首必要更改着色器中的对应语句。其次,还必要更改 VertexArray 的 SetLayout() 函数,以便我们可以大概正确的添加新增的顶点属性 。末了,我们还必要更改实际的绘制函数,以便我们在绘制的过程中生存对应的 entityID
3.调用更新后的绘制函数,为图像添加新的顶点属性
4.也可以通过读取出来的 EntityID 将实体信息放在 ImGui 窗口中实时查察
》》》》我们在 OpenGL 上下文中访问的顶点属性数据(好比访问片断着色器中的输出变量 color2),此时这个变量存放在那里?我们从那里读取到这个数据?
条件:
着色器的使用阶段:
| OpenGL 渲染管线分为多个阶段,此中顶点着色器和片断着色器是关键的两个阶段。
| 着色器的作用:
| 顶点着色器负责处置惩罚每个顶点的数据(如位置、颜色、纹理坐标等),而片断着色器则负责处置惩罚每个片断(即像素)的颜色和别的属性。
|
Eg.假设这里有一段着色器代码(glsl)
Vertex shader
#version 330 core
layout(location = 0) in vec3 a_Position; // 顶点位置
layout(location = 1) in int a_EntityID; // 顶点的 EntityID(来自顶点缓冲区)
out flat int v_EntityID; // 通报给片断着色器的 EntityID
void main()
{
gl_Position = vec4(a_Position, 1.0);
// 将 EntityID 从顶点着色器通报到片断着色器
v_EntityID = a_EntityID; }
Fragment shader
#version 330 core
// 吸收来自顶点着色器的 EntityID
in flat int v_EntityID;
out vec4 FragColor;
void main()
{
FlagColor = v_EntityID;
}
起首让我们明白一下使用逻辑:
第一步,
| 我们在绘制的时间通过函数填入了 EntityID,随后通过代码中的 SetLayout() 明白 EntityID 的属性,并将其写入顶点缓冲区中。
| 第二步,
| 当顶点被写入后,在渲染管线阶段中,顶点着色器中的数据被传输给片断着色器,在片断着色器中我们也可以举行一些处置惩罚操纵。
| 第三步,
| 我们在实际使用时,会使用函数读取片断着色器中的 FlagColor 变量, 而 FlagColor = v_EntityID.
|
》此时我的标题是,在访问过程中,片断着色器中的 FlagColor 变量存储在那里?由于 FlagColor = v_EntityID,我还想知道 v_EntityID 此时存放在那里?
标题一:v_EntityID 存放在那里?
通报过程:
当 OpenGL 上下文实验访问 v_EntityID 时,是从顶点着色器通报来的。这是具体的通报过程:
顶点缓冲区存储:每个顶点有一个对应的 EntityID,通常通过顶点属性传入(好比通过 a_EntityID)。
顶点着色器处置惩罚:顶点着色器将 EntityID 从输入的顶点数据通报给片断着色器(通过 out 变量 v_EntityID)。
片断着色器访问:片断着色器通过 in 变量 v_EntityID 获取这个值,并根据它实验差异的渲染操纵。
以是,v_EntityID 实际上是存储在 GPU 的顶点缓冲区中的,并在顶点着色器和片断着色器之间通报。
标题二: FlagColor(Color2)存放在那里?
在大多数环境下,这些输出值被存储在与当前绑定的帧缓冲关联的颜色附件中,好比片断着色器的输出通常会存储在帧缓冲的一个 颜色附件(Color Attachment)中。
OpenGL 答应你绑定多个附件位置,我们可以通过 OpenGL 提供的宏常量:GL_ATTACHMENT0,GL_ATTACHMENT1 ….. ,通过附件绑定的位置访问附件。
》》》》GLSL 中的 flat 修饰词有什么作用?
EG.
| in flat int v_EntityID;
| 概念:
| flat 是一个修饰符,在 GLSL 中,它用于确保着色器中差异处置惩罚单元(好比差异的片断或像素)在使用此变量时不会举行插值。换句话说,使用 flat 关键字声明的变量在差异的盘算单元中会保持类似的值,不举行插值,即每个盘算单元直接使用传入的值。
| 兼容性:
| 插值操纵与 int 范例不兼容,GLSL 的插值机制默认计划用于浮点范例数据。当使用 int 范例时,插值操纵并不总是得当的,由于 int 是离散的,而且它不能像浮点数那样平滑过渡,以是如果你不加 flat 修饰符,着色器会实验对 int 举行插值,这会导致不可推测的结果。
比方,在两个顶点之间,着色器大概会实验对整数值举行插值,这显然是偶尔义的,由于整数范例值无法像浮动范例那样平滑过渡。
|
实际环境阐明:
在没有 flat 修饰符的环境下,当你从顶点着色器向片断着色器通报数据时,数据会被插值。而插值是为了平滑过渡而计划的(通常应用于浮点数),以是,如果你盼望 v_EntityID 在片断着色器中始终保持稳固(不被插值),你必要使用 flat 修饰符来克制插值。
比方,在光栅化过程中,大概有多个片断(像素)在差异的盘算单元上处置惩罚,如果没有 flat 修饰符,v_EntityID 会举行插值操纵,但由于 int 范例是离散的,插值大概会导致无效的值(比方,v_EntityID 在两个顶点之间的值不会是整数,大概导致错误)。此时使用 flat 可以制止这种插值,确保每个片断得到完全类似的值。
错误注意:
1.未明白使用 flat 关键字:
对于整型的输出变量,如果没有明白使用 flat 修饰符,GLSL 会默认对 v_EntityID 举行插值。这大概会出现报错:
|
| 2. 使用 flat 时,必要对着色器版本号举行更改:
|
更改后大概会出现告诫:(再次运行一次步调便不会出现告诫,我意料是由于着色器的版本号被改变了,必要重新编译一次)
Program/shader state performance warning: Vertex shader in program 1 is being recompiled based on GL state.
| 这表明当前的顶点着色器(在步调 1 中)正在根据 OpenGL 的状态举行重新编译。OpenGL 状态指的是一些全局的设置,好比混淆模式、视口尺寸、纹理绑定等。这些状态的改变大概导致必要重新编译着色器,以确保它们能正确地与当前状态共同。
| Program/shader state performance warning: Vertex shader in program 1 is being recompiled based on GL state, and was not found in the disk cache
| 这个部门表明,重新编译的着色器没有找到预编译的缓存文件,这大概意味着着色器的缓存没有被写入磁盘,大概着色器步调本身没有缓存。每次重新编译会带来肯定的性能开销,尤其是在实时渲染中。
|
|
》》》》glVertexAttribIPointer( ) 有什么意义?怎么使用?
glVertexAttribIPointer() 是 OpenGL 中的一个函数,专用于设置整数范例的顶点属性指针。
这个函数的作用是告诉 OpenGL 如安在顶点缓冲区中读取顶点属性数据,尤其是当这些数据是整数范例时。它类似于 glVertexAttribPointer(),但专门处置惩罚整数范例数据,而不涉及浮点数据。
》》》》运行之后,我注意到一个标题打印出来的 EntityID 为什么不是 0,1,2 而是 0,2,3 ?
这是由于我们在 yaml 文件中存储的实体次序是如许的(我们不但存储了三个物体实体,还存储了一个摄像机实体,而这个摄像机实体由于一些缘故因由被放置在第二个实体的位置上)
》》而我们只必要在文件中调解几个实体的位置即可实现 0,1,2 的结果:
》》》》使用思绪:这句代码是怎样实现对应功能的?
m_HoveredEntity = pixelData == -1 ? Entity() : Entity((entt::entity)pixelData, m_ActiveScene.get());
条件:在使用 Ctrl + O 之后,会调用一个函数 --> OpenScene(); 这个函数将会继续调用 --> serializer.Deserialize(filepath); 在 Deserializer() 中,有这两句代码:
Entity& deserializedEntity = m_Scene->CreateEntity(name); // Create a new entity in m_Scene with all default values
DeserializeEntity(entity, deserializedEntity); // Update values in this entity accroding to yaml file
也就是说, OpenScene() 函数会为我们创建实体,通过调解实体的属性,我们得以在引擎中查察文件的内容。
明白:以是在我们打开某个文件之后,画面中绘制的全部物体,实在就是我们创建的实体(这些实体在 OpenScene() 中被创建,而且调解了组件中的属性:Translate, Color ….)。如果此时我们在特定环境下,使用类似的数据再次创建一个新实体(Entity 范例对象),就可以确保新实体是对应旧实体的副本。
Eg.
Ctrl + O 打开文件,终极会运行此函数。此中高亮的代码部门会确保我们在读取文件之后,创建 YAML 文件中的实体
CreateEntity() 会创建实体,m_Registry.create() 会自动分配 entityID,这个ID是唯一的。
这时,好比在代码中,如果鼠标光标在视口范围内、且悬停在物体上方,我们就创建实体:HoveredEntity
由于我们在 DrawQuad() 这个绘制函数中,将 EntityID( EntityHandle )传入了顶点着色器,以是通过 ReadPixel() 我们可以读取对应的 EntityID。并使用这个 EntityID(pixelData)创建一个实体。
那么这个实体 和 打开YAML文件时创建的实体 有什么接洽呢?为什么我们可以通过 HoveredEntity 使用 GetTagcomponent(),访问到先前实体的数据?
由于 Deserializer() 中创建的实体,是通过 EntityID( m_Registry.Create() ) 和 Scene( this 即 m_ActiveScene )创建的,这两个参数都是唯一的标识,我们可以通过如许的唯一标识访问组件。
如果此时我们又新建了一个实体,好比HoveredEntity, 并使用了类似的参数将其初始化,如许我们就拥有了先前实体的一个副本,这个副本就是 HoveredEntity。由于 HoveredEntiy 中生存着这些唯一标识,我们固然可以使用 GetComponent() 访问到对应的组件,而且组件的内容 等同于 先前实体组件中的内容。
》》》》代码中的 OpenGL 版本号管理代码,在那里?
在代码中并没有明白表现OpenGL版本号( 好比通过 GLFWWindowHint() 设置版本号),以是GLFW 会检测你的图形卡及其驱动步调支持的 OpenGL 版本。如果没有明白指定版本,GLFW 会选择一个符合的默认版本,通常是当前体系支持的最新版本。
本机为:
》》》》我对Cherno的代码做了一点更改
在这里,我以为满足条件判定之后,会不绝调用构造函数,大概比力淹灭性能。
更改之后:
不外从数据分析上看起来,固然优化了一部门性能,但是原来似乎就没有很大的性能负担。:-)
--------------------------------- Left click to select entities -----------------------------------------
》》》》ImGuizmo::IsOver( )
作用:
| ImGuizmo::IsOver() 的紧张作用是查抄当前鼠标是否悬停在 Gizmo 上,大概说当前操纵是否影响了 Gizmo。如果鼠标在某个 Gizmo 上,返回 true,否则返回 false。
通常,这个函数与其他 Gizmo 操纵函数(如 ImGuizmo::Manipulate())团结使用,以便判定用户是否在举行某些变动操纵。
| 原型:
| bool ImGuizmo::IsOver( ImGuizmo::OPERATION operation = ImGuizmo::ALL );
| 参数:
| ImGuizmo::IsOver() 必要一个 操纵模式 作为参数,该参数用于指定查抄的 Gizmo 范例。
ImGuizmo::OPERATION operation: 这是一个罗列范例,指定了 Gizmo 的操纵范例。
包罗:
- ImGuizmo::TRANSLATE:平移操纵。
- ImGuizmo::ROTATE:旋转操纵。
- ImGuizmo::SCALE:缩放操纵。
- ImGuizmo::ALL:查抄全部的 Gizmo 操纵。
| 返回值:
| true:如果当前鼠标悬停在 Gizmo 上,大概用户正在对 Gizmo 举行某种操纵。
false:如果鼠标不在 Gizmo 上,大概没有举行任何操纵。
|
》》》》我所做的改进:
我新添了一个实体,这个实体只在 鼠标单击具体物体 / 单击某一实体的 Guizmoa 时更新实体,如许一来,只管 HoveredEntity 会由于鼠标的位置实时发生改变,但是 UsingEntity(Entity in use) 不会轻易改变,只有鼠标操纵某一物体时才会发生更改。
m_UsingEntity 逻辑更新代码:
ImGui::Text() 打印代码:
----------------------------------- Maintenace ---------------------------------------------------
》》》》后续会整合 Jul/22 2020 之后的维护
------------------------------ SPIR-V & New shader system --------------------------------------------------------
》》》》这次 Cherno 做了很多提交,以是我的条记大概篇幅较长,但我会细致记载。
我做了一些条记,请认真欣赏。
实际操纵步调请转到: 》》》》我将逐次的提交这些代码,并记载本身的疑虑
》》》》先容与引入
》》》》 basic architecture layout of this episode(本集根本构架)
(截图仅供个人参考,并无陵犯版权的想法。若违背版权条款,并非本人意愿)
个人在学习过程中以为最值得查阅的几个文档:
游戏开发者大会文档
(关于 SPRI-V 与 渲染接口 OpenGL/Vulkan 、GLSL/HLSL 之间的关系,SPIR-V 的工具及实在验流程
| https://www.neilhenning.dev/wp-content/uploads/2015/03/AnIntroductionToSPIR-V.pdf
| 俄勒冈州立大学演示文档
( SPIR-V 与 GLSL 之间的关系, SPIR-V 的实际使用方法:Win10 )
| https://web.engr.oregonstate.edu/~mjb/cs557/Handouts/VulkanGLSL.1pp.pdf
| Vulkan 官方 Github Readme 文档
( GLSL 与 SPIR-V 之间的映射关系,以及可以在线使用的编辑器,非常好用)
| https://github.com/KhronosGroup/Vulkan-Guide/blob/main/chapters/mapping_data_to_shaders.adoc
在线文档示例( Compiler Explorer )
| 大阪Khronos开发者大会(SPIR-V 语言的规范,及其意义)
| https://www.lunarg.com/wp-content/uploads/2023/05/SPIRV-Osaka-MAY2023.pdf
|
前 33 分钟,根本上报告以下几点:
1.着色器将会支持 OpenGL 和 Vulkan ,故着色器中做了更改(涉及到 OpenGL 和 Vulkan 在着色器语法上的差异:好比 Uniform 的使用)
|
| 2.为了制止性能浪费,并高效的使用数据/同一变量,将接纳 UniformBuffer 这种高级 GLSL。
(参考文献1-来自 LearnOpenGL 教程: 高级GLSL - LearnOpenGL CN )
(参考文献2-来自 Vulkan 教程: Descriptor layout and buffer - Vulkan Tutorial )
发起阅读全文,如许明白更加深刻。
|
- Uniform buffer:
- Uniform buffer
| 3.OpenGL 和 Vulkan 在着色器语言上的使用规范,尚有差异之处。
参考文献:OpenGL教程( 材质 - LearnOpenGL CN )
参考文献:俄勒冈州立大学演示文件《 GLSL For Vulkan 》( https://eecs.oregonstate.edu/~mjb/cs557/Handouts/VulkanGLSL.1pp.pdf )
附录:
参考文献:Github 中文 Readme( https://github.com/zenny-chen/GLSL-for-Vulkan )
参考文献: Vulkan 教程官网( Introduction - Vulkan Tutorial )
|
大概在 Vulkan 教程官网中征采( Introduction - Vulkan Tutorial )
- 差异之处:
- 如果想查察 Vulkan API 在编写着色器时使用 GLSL 的语法规范,可以查察 Github 堆栈(中文: https://github.com/zenny-chen/GLSL-for-Vulkan )
- GLSG 中的结构体示例:
| 4.SPIR-V 的使用思绪,使用逻辑。
参考文献:SPIR-V 官网( https://www.khronos.org/api/index_2017/spir )
参考文献:Vulkan 教程( Shader modules - Vulkan Tutorial )
参考文献: Vulkan 指南( What is SPIR-V :: Vulkan Documentation Project )
参考文献:俄勒冈州立大学演示文件( https://web.engr.oregonstate.edu/~mjb/cs557/Handouts/VulkanGLSL.1pp.pdf )
参考文献:2016 年 3 月 - 游戏开发者大会 ( https://www.neilhenning.dev/wp-content/uploads/2015/03/AnIntroductionToSPIR-V.pdf )
附件:关于 SPIR-V 也可以参考 SPIR-V 的 github 堆栈:
( https://github.com/KhronosGroup/SPIRV-Guide )
|
参考接下来的条记:( 实际使用流程: )
大概参考( https://www.neilhenning.dev/wp-content/uploads/2015/03/AnIntroductionToSPIR-V.pdf )
- SPIR-V 的使用流程:
- SPIR-V 管线:
- SPIR-V 的概念:
- SPIR-V 的生态体系:
|
》》》》 SPIR-V SPIR-V ?什么是 SPIR-V ? SPIR-V SPIR-V
SPIR-V 简介
SPIR-V (Standard Portable Intermediate Representation for Vulkan) 是一种低级中心表现语言(Intermediate Representation, IR),通常是由高层语言(如 GLSL 或 HLSL)编译而成,紧张用于图形和盘算步调的编译。( 开发者写的 GLSL 或 HLSL 代码会被编译成 SPIR-V,然后交给 Vulkan 或 OpenCL 、OpenGL等图形盘算 API 来实验。)
SPIR-V 答应开发者编写更加底层的图形或盘算代码,并通过它来与图形硬件交互。
实际使用流程:
OpenGL
| 通常使用 GLSL(OpenGL Shading Language)来编写着色器代码
| Vulkan
| 使用 SPIR-V(Standard Portable Intermediate Representation for Vulkan)作为着色器的中心语言。
|
为什么说 SPIR-V 是中心语言?
在 Vulkan 中,着色器代码(如顶点着色器、片断着色器等)起首用高级语言(如 GLSL 或 HLSL)编写,然后通过工具(如 glslang)编译成 SPIR-V 字节码,末了通过 Vulkan API 加载并使用这些字节码。
OpenGL 与 SPIR-V的工作模式:
| 在 Vulkan 出现之前,OpenGL 是紧张的图形 API,GLSL 是 OpenGL 使用的着色器语言。随着 Vulkan 的推出,SPIR-V 成为了 Vulkan 着色器的中心表现,SPIR-V也被引入到 OpenGL 中。
只管 OpenGL 不绝使用 GLSL 作为着色器语言,但 OpenGL 4.5 及更高版本已经支持通过 SPIR-V 加载编译好的着色器二进制文件。
这意味着OpenGL 固然仍旧使用 GLSL 来编写着色器,但编译过程可以将 GLSL 代码转化为 SPIR-V,之后在 OpenGL 中加载 SPIR-V 二进制代码举行实验。这一过程通过 glslang(Khronos 提供的 GLSL 编译器)实现。
| Vulkan 与 SPIR-V 的工作模式:
参考文献:游戏开发者大会2016
( https://www.neilhenning.dev/wp-content/uploads/2015/03/AnIntroductionToSPIR-V.pdf)
| Vulkan 作为低级 API,要求全部着色器都以 SPIR-V 格式存在。由于着色器源代码通常使用高级着色器语言(如 GLSL 或 HLSL)编写,以是必要先编译成 SPIR-V 二进制格式,然后将该 SPIR-V 二进制代码上传到 GPU 举行实验。
作用:SPIR-V 使 Vulkan 可以实现跨平台的着色器支持,依赖 SPIR-V 这种中心语言,着色器可以大概在差异平台和硬件上正常运行。SPIR-V 规范的语言比纯文本的着色器语言(如 GLSL)更靠近底层硬件,便于优化和硬件加速。
示例:
|
实际使用实例:
1. GLSL 源代码编写
| 起首,编写 GLSL 源代码。这些 GLSL 代码通常包罗顶点着色器、片断着色器、盘算着色器等。
示例:GLSL 着色器
#version 450
out vec4 FragColor;
void main() {
FragColor = vec4(1.0, 0.0, 0.0, 1.0); // 输出赤色
}
| 2. GLSL 编译为 SPIR-V
| 将 GLSL 源代码转换为 SPIR-V 二进制格式,得到一个平台无关的二进制文件,这意味着 SPIR-V 代码可以在差异的硬件和操纵体系上运行。
工具1:
glslang(Khronos 提供的编译器,广泛用于将 GLSL 转换为 SPIR-V)。
编译过程:
GLSL 代码通过 glslang 编译器举行语法查抄和优化,并得到一个二进制文件。
工具2:
你也可以使用下令行工具 glslangValidator 来编译 GLSL 代码。
编译过程:
使用下令:glslangValidator -V shader.glsl -o shader.spv
这将会把 shader.glsl 编译成 shader.spv,即 SPIR-V 二进制文件。
| 3. 加载 SPIR-V 到 Vulkan 或 OpenGL 中
| 3.1 在 OpenGL 中使用 SPIR-V
前情提要:
从 OpenGL 4.5 开始,OpenGL 也支持通过 SPIR-V 加载编译好的着色器二进制文件。流程与 Vulkan 类似,只不外 OpenGL 在内部做了更多的高层封装。
加载过程:
示例:
GLuint program = glCreateProgram();
// 加载 SPIR-V 二进制文件
GLuint shader = glCreateShader(GL_VERTEX_SHADER);
glShaderBinary(1, &shader, GL_SHADER_BINARY_FORMAT_SPIR_V, spirvData, spirvDataSize);
glSpecializeShader(shader, "main", 0, nullptr, nullptr);
// 绑定和链接步调
glAttachShader(program, shader);
glLinkProgram(program);
-----------------------------------------------------------------------------------------------------
3.2 在 Vulkan 中使用 SPIR-V
加载过程:
创建一个 VkShaderModule 对象,该对象包罗 SPIR-V 二进制代码。
使用 SPIR-V 二进制代码来创建 Vulkan 着色器管线(比方,创建顶点着色器和片断着色器的管线)。
示例:Vulkan 使用 SPIR-V
// 加载 SPIR-V 文件(假设你已经将 shader.spv 文件加载为二进制数据)
VkShaderModuleCreateInfo createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.codeSize = shaderData.size();
createInfo.pCode = reinterpret_cast<const uint32_t*>(shaderData.data());
// 创建着色器模块
VkShaderModule shaderModule;
VkResult result = vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule);
// 使用这个 shaderModule 来创建图形管线
| 4. 实验着色器步调
| 在 OpenGL 中,SPIR-V 着色器步调被链接到步调对象中,并通过调用 glUseProgram 来激该死步调,之后通过绘制调用来实验。
在 Vulkan 中, 着色器被绑定到渲染管线或盘算管线中,随后可以通过绘制下令(比方 vkCmdDraw)或盘算下令(比方 vkCmdDispatch)来实验。
|
》》》》上述涉及语言的纵向对比图
GLSL
|
| SPIR-V
SPIR-V 本身的核心是一个二进制格式,然而为了便于开发和调试,SPIR-V 也可以以类似汇编语言的文本情势表达,这种情势通常称为 SPIR-V Assembly。
它是 SPIR-V 的一种可读性较好的文本表现方式,开发者可以通过这种情势来编写、调试和优化 SPIR-V 代码,然后再将其转换为二进制格式以供图形 API 使用。
实际上,SPIR-V Assembly 代码终极照旧会通过工具(如 spirv-as)转化为二进制格式,供 Vulkan 或 OpenGL 使用。
| SPIR-V
SPIR-V Assembly
| OpenGL
|
| Vulkan
|
|
》》》》具体代码更改细则

以下是更新详情(图示):
1 premake脚本更改
(and better premake scripts)
|
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
| 2 py脚本
(Python scripts for retrieving dependencies)
|
1. 确保在实验过程中 requests 和 fake-useragent 这两个模块已经安装。如果没有安装,它会自动使用 pip 安装它们。
1.确保所需的 Python 包已经安装。
2.查抄 Vulkan SDK 是否安装,并确保 Vulkan SDK 的调试库存在。
3.改变当前工作目次到项目根目次。
4.使用 premake 工具天生 Visual Studio 2019 项目标构建文件。
DownloadFile(url, filepath) 函数的作用是从指定 URL 下载文件,并表实际时的下载进度(包罗下载进度条和速率)。
YesOrNo() 函数用于与用户举行交互,获取用户简直认输入,返回布尔值表现“是”或“否”。
用于查抄和安装 Vulkan SDK
InstallVulkanSDK(): 下载并运行 Vulkan SDK 安装步调。
InstallVulkanPrompt(): 提示用户是否安装 Vulkan SDK。
CheckVulkanSDK(): 查抄 Vulkan SDK 是否安装而且版本是否正确。
CheckVulkanSDKDebugLibs(): 查抄 Vulkan SDK 的调试库是否存在,如果缺失则下载并解压。
| 3 Application 中的 ApplicationCommandLineArgs
( added command line args)
|
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
| 4 Uniform Buffer 的界说以及使用,包罗着色器更新
(added uniform buffers)
|
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
------ ------ ------ ------ ------ ------ -------
| 5 着色器体系更新:
(New shader system)
| Timer 的界说
------ ------ ------ ------ ------ ------ -------
着色器更新
| 6 平台工具的更新(打开或生存文件)
|
| 7 视口与摄像机更新:
|
|
》》》》我将逐次的提交这些代码,并记载本身的疑虑
》》》一:我起首使用更新并使用 py 文件下载 Vulkan SDK
起首第一步:运行 bat 脚本,通过该文件下载 Vulkan SDK。
(Vulkan.py 文件使用了 Utils.py 中的函数,当你在 Hazel\scripts 的路径下通过 Setup.py 使用 Vulkan.py 时,Vulkan.py 会将 Vulkan 默认下载到 Nut/vendor/VulkanSDK。)
》》标题零
运行脚本时,请关闭署理。
》》标题一
如果将文件放在 Scripts 文件夹下,并直接通过 Setup.bat 运行 Setup.py 的话,会出现报错,表现文件路径已经不存在。--->
|
| 这必要提前在 vendor 创建 VulkanSDK 文件夹。
(记得修改 .py 中的下载路径,这取决于你的项目名称,尚有你想下载到本机的路径)
|
|
》》标题二
创建好 VulkanSDK 文件夹之后,重新运行 Setup.py,脚本运行之后开始实验运行 Vulkan installer:
|
| 但是随后的弹窗中提示:
|
| 这大概是 Vulkan.py 中存放的 VulkanSDK 下载地点不得当 64 位体系,我将其更新为 2023 年的某一版本。
附录:如果你想进入官网查察得当你体系的SDK,以下是网址 ->
( LunarXchange )
|
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
| 当前我只更新了 SDK Installer 的安装地点,但是我还没有更新随后的 debug lib.zip,这是下一个标题会出现的地方,如今先不讨论。
我们先重新运行一遍,使用更新之后的 SDK install。
于是运行后出现如许的窗口:
|
| 安装 vulkan SDK
| 我现在没有选择任何拓展,但在安装过程中,我不是很确定这个拓展和 DebugLibs 有没有什么直接关系。就先标注一下。
(毕竟这将会占用我1G空间 bushi)
随后便得到如许的文件构架:
|
》》标题三
我们发现 Cherno 别的下载了一个 Debuglib.zip,并对其举行了一些处置惩罚。
但是在1.2.198.1版本之后,lunarg 公司不再支持 debuglibs 的单独下载。如今 SDK 中的调试库通常随着 Vulkan 库一起分发,不再单独打包成一个 zip 文件。
以是如今,这些文件通常直接包罗在 Vulkan SDK 的核心目次下,特别是在 lib 目次中
我们也可以从品评中窥见这一更改。(@SionGRG)
|
| 如今我们必要更改这个函数( CheckVulkanSDKDebugLibs )的逻辑
起首,我对这个 shaderc_sharedd.lib 的路径有点疑惑:由于我简直查找到了 shaderc_shared.lib 这个库,而不是shaderc_sharedd.lib。
如今我开始更改,不外我发现原先的逻辑是:如果没有找到调试库,就在线去下载。
但如今这些文件将会在安装 Vulkan SDK 时,同步安装在文件夹中,以是如果没有找到的话,肯定是安装是出了什么标题。
我便做了以下更改:( 仅仅是口头提示一下 :-) )
随后我重新运行 Setup.bat,并拒绝再次安装 installer,便得到如许的结果:
|
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
--- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
|
我想应该是对了。
》》》》二:如今我们已经乐成安装了 Vulkan,如今则必要更新 premake 文件内容。
这是将要实现的 premake 文件构架图(以及细则)
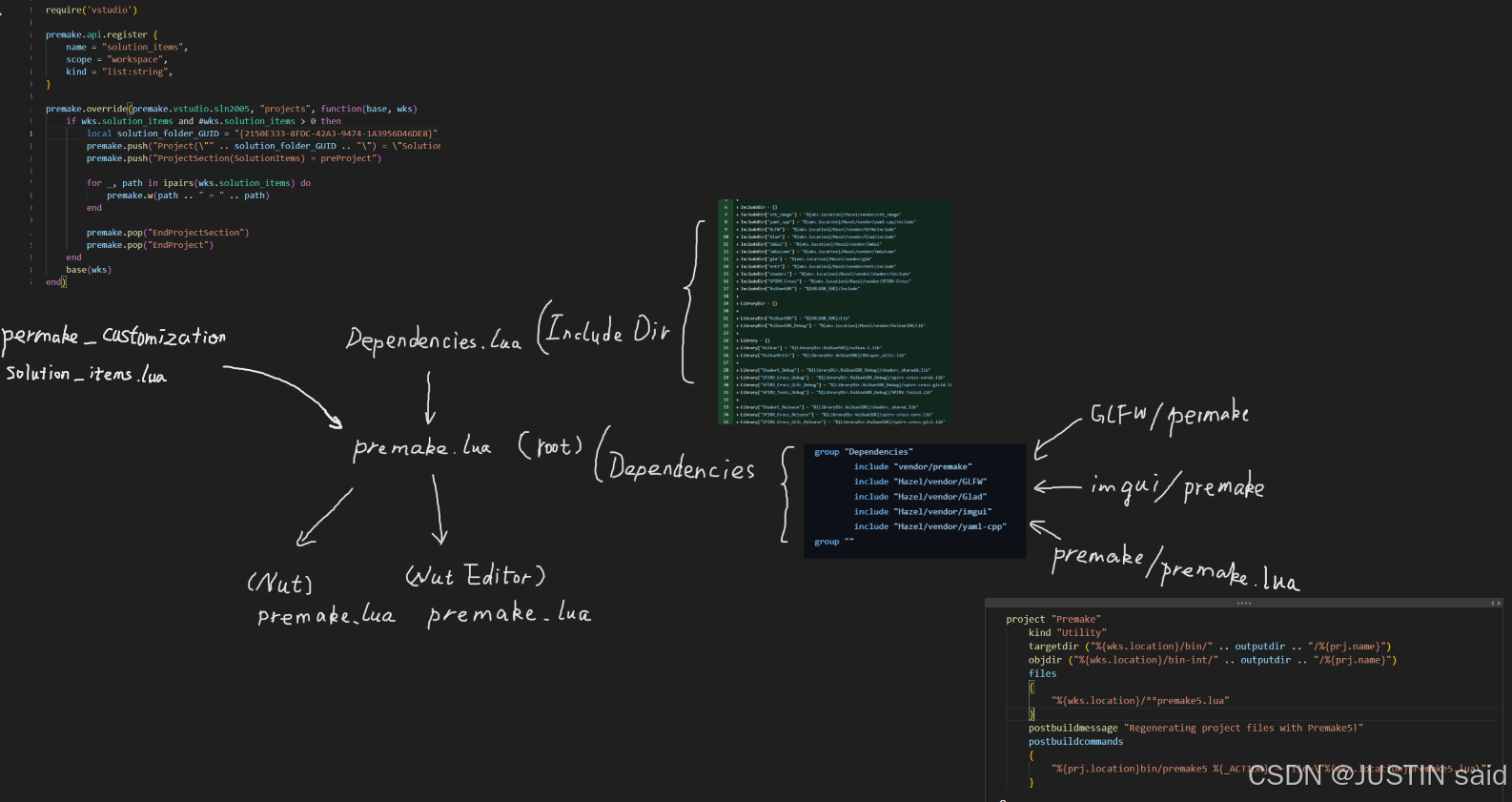
》》》》接下来我先更新 Premake Dependencies.lua 文件(这里为预处置惩罚,实际操纵步调在背面)。
第一步,我们在项目标根目次下重新编写一个 premake 文件,这个文件紧张用来索引 vendor 中的外部库(API)
|
| 但我发现有些标题,好比 shaderc 和 spriv_cross 的路径已经发生改变,参考 1.3.250.1 版本:这两个文件夹位于 VulkanSDK/Include 下
而且由于我没有下载某些组件,这使很多文件并不存在。(我将其标注出来)
于是我决定下载拓展(shader toolchain debug symbols),这一步通过运行 maintenancetool.exe 文件实现:
固然下载了一个组件可以办理但部门标题,但是只管在之后我下载了别的的全部组件, VulkanSDK/Include/Lib 这个路径都不存在(但是Vulkan/Lib 这个路径存在),且 VKLayer_utils.lib 这个文件也不存在。
|
体系变量示例:
这个组件将会办理这部门标题:
一个标题:VKLayer_utils.lib 似乎在1.3.216.0 版本中被移除了。
|
以是这是 premake 文件最新的样子:
》》》》操纵步调:
》》111 如今我们将 Nut/premake.lua 中的表单独存放在另一个文件中( Dependencies.lua)
此中包罗:
》》222 在 Nut/vendor/premake 下(注意不是 Nut/Nut/vendor/ 这个路径)创建如下文件。(内容等会阐明)
(链接 : 》》》》接下来谈谈 vendor/premake 文件中我们新添的两个文件:premake5.lua 和 premake_customization/solution_items )
》》333 修改 Nut/premake.lua 内容,使其包罗上述三个文件
》》444 修改 Nut/Nut/premake5.lua 和 Nut/Nut-Editor/premake5.lua 文件内容
具体内容是 :
| Nut-premake 文件必要包罗 Vulkan 的库目次,并在对应设置下添加相干链接。
|
》》标题:
在此处我碰到一个标题,就是 Cherno 对这两个文件关闭了 staticruntime 设置。
这表现禁用静态链接运行时库,使用动态链接的运行时库。意味着步调在运行时将依赖外部的动态链接库(DLL),而不是将运行时库直接嵌入到可实验文件中。
示例:
而我印象里 Cherno 没有阐明要转回使用动态库的方式,以是如今我没有将其打开。
(在之后的提交中,我修改掉了这里的代码,可以查察:》》》》对着色器体系举行修改后,必要将 Premake 中的运行时静态链接关掉:)
(趁便一提,如果必要打开的话,还必要额外举举措态链接的设置操纵,具体可以回看Cherno的视频: Static Libraries and ZERO Warnings | Game Engine series )
》》》》接下来谈谈 vendor/premake 文件中我们新添的两个文件:premake5.lua 和 premake_customization/solution_items.lua
具体的 Pull&requests 纪录于 #301( https://github.com/TheCherno/Hazel/pull/301 )
Premake5.lua
| 界说一个工具范例的项目 Premake,而且在构建后通过 premake5 工具来重新天生或更新项目文件。
这个脚本的目标是 天生或重新天生构建项目文件(如 Visual Studio 工程文件、Makefile 等),使用的是 premake5 工具。它是一个自动化构建的过程,通常用于天生构建体系(如 Makefile 或 Visual Studio 工程文件)等。
| solution_items.lua
| 这段代码的作用是为 Visual Studio 办理方案 文件(.sln)添加一个新的部门,称为 Solution Items,并将工作区中指定的文件(通过 solution_items 下令)添加到这个部门中。
办理方案项是指那些不是属于任何特定项目标文件,比方文档、设置文件等,通常用于存储一些和整个办理方案相干但不属于某个单独项目标文件。
这添加了对 Visual Studio 办理方案项(solution items)的支持。文档、设置文件、README 或其他相干文件将可以被作为办理方案项添加到办理方案中。
|
》》》》三:Application 中的 ApplicationCommandLineArgs
( added command line args)下令行参数
》》流程与界说的概述
起首,我们位于入口点的主函数中使用了(argc, argv) 来获取下令行信息。而且将参数传入到 CreateApplication() 中,以便后续使用这些信息:
|
在入口点使用的 Nut::CreateApplication({ argc, argv }),实际上是在构造一个 ApplicationCommandLineArgs 范例的对象,并将 argc 和 argv 通报给它。
|
管线流程:
| 这里是 CreateApplication() 的界说。
CreateApplication() 中使用了NutEditor()
|
| 这里是 NutEditor() 的界说。
NutEditor() 是 Application() 的子类,故 NutEditor() 的构造函数会自动先使用父类 Application() 的构造函数,我们可以通过这个特性将 args 参数传给 Application() 的构造函数,并实现一些目标。
|
| 这是父类 Application() 构造函数的新界说。
同时我们新添了一个 GetCommandLineArgs() 的函数,用于获取私有变量 m_CommandLineArgs 中存放的数据。
|
我们可以在运行时查察argv获取到的信息是什么。
|
|
》》》》知识点
》》》》关于 Argc, Argv
1. argc 和 argv 的寄义
界说:
在 C 和 C++ 步调中,argc 和 argv 是由编译器(如 GCC、Clang 或 Visual Studio)在步调启动时自动通报给步调的 main 函数的两个参数。用于通报下令行的输入参数。
- argc:是 argument count 的缩写,表现下令行参数的数量。它是一个整数,包罗步调名和任何附加的下令行参数。
- argv:是 argument vector 的缩写,表现下令行参数的数组。它是一个字符指针数组,每个元素是一个指向下令行参数的字符串。
比方,当你使用指令运行一个步调( ./myapp input.txt --verbose )时,argc 和 argv 的内容如下:
argc = 3,由于有三个参数(步调名、input.txt 和
--verbose)
| argv[0] = "./myapp",表现步调的路径。
argv[1] = "input.txt",表现第一个参数(输入文件)。
argv[2] = "--verbose",表现第二个参数(开启调试模式)。
|
运行机制:
(什么时间通报?通报什么内容?)
| argc 和 argv 是由操纵体系在启动步调时根据下令行输入自动通报的,不必要手动获取。
步调中 argc 和 argv 的值取决于你启动步调时背景输入到下令行中的下令或参数内容。在差异的操纵体系上,下令行参数的格式和表明规则大概会有所差异。
好比:
- 在 Windows 上,下令行参数是由 下令提示符(cmd.exe)或 PowerShell 等工具通报给步调的。
- 在 Unix/Linux 上,下令行参数是由 shell(如 Bash)通报给步调的。
| (内容什么时间被确定?是否可以被随时改变?)
| argc 和 argv 是实时的,但它们是步调启动时由操纵体系从下令行提取的参数,而且在步调实验过程中保持稳固。
以是一旦步调开始实验,argc 和 argv 的值就固定了,不能在步调运行过程中改变。
|
2.有没有类似 argc 和 argv 的参数?
C++ 尺度库没有其他内建的类似 argc 和 argv 的机制。argc 和 argv 是 main 函数的参数,是 C++ 尺度界说的,通常用于处置惩罚下令行参数。
不外,你可以使用其他自界说的数据结构来封装下令行参数,为它们提供更机动的操纵方式,
比方,在当前环境下,我们可以在 EditorLayer.cpp 中实时的获取到下令行参数信息并将其打印在控制台上:
|
| 大概在 EntryPoint.h 中实验打印全部捕获的下令行参数:
|
|
得到如许如许的结果:
|
|
3. 在怎样的影响下,获取的下令行参数或发生变革?
在通常环境下,一旦项目标构架被明白(好比依赖性、文件路径等等),仅对步调举行代码上的“软”处置惩罚无法修改从下令行中获取的指令内容,由于这个内容一样平常是在步调启动时cmd中的内容。此处我们可以看到下令为:“ E:\VS\Nut\bin\Debug-windows-x86_64\Nut-Editor\Nut-Editor.exe”
如果想要对其举行修改,大概必要在VS的项目属性页面,举行相干修改:
4.Cherno 为什么举行如许的处置惩罚?这个新功能的意图是什么?
分析指令内容:
让我们分析获取的指令:“ E:\VS\Nut\bin\Debug-windows-x86_64\Nut-Editor\Nut-Editor.exe”,这个指令的 argc 为 1,表现只有一段一连的指令。以是 argv 是一个只有一个元素的数组 argv,argv[0] 的内容便是“ ”,而 argv[1] 自然为 null。
先决条件:
起主要明白一点,在 x64 、 Debug 的模式下,如果我们运行这个步调 (Nut-Editor) ,我们会从下令行中固定的获取到诸如:“ E:\VS\Nut\bin\Debug-windows-x86_64\Nut-Editor\Nut-Editor.exe”如许的下令如上文所说,在项目标构架被明白之后,获取到的内容一样平常就固定下来了。
实际使用时发生的环境:
如今 Cherno 设置了下令行参数的新功能,但实在并不是想通过在某处修改下令内容,大概实时根据下令的变革举行一些操纵。而是为了在下令行中运行指令时,开启引擎并进入页面的时间,可以大概自动预先加载一个场景,让我们查察结果以相识详情:
这里是 Cherno 的使用场景:
(旧)
一个黄褐色头发的夫君,他打开了 cmd ,想要运行 Nut-Editor 应用,于是他输入了一句指令:
argc
| 1
| argv[0]
| "E:\VS\Nut\bin\Debug-windows-x86_64\Nut-Editor\Nut-Editor.exe"
|
通常环境下,这一段指令将直接打开引擎,但并不会在开启时加载一个场景。由于如今只有一段完备的指令,也就是说,这个条件判定不满足:
| (新)
但是在新功能的加持下,如果我们在该指令之后添加了一个来自场景的目次:
argc
| 2
| argv[0]
| "E:\VS\Nut\bin\Debug-windows-x86_64\Nut-Editor\Nut-Editor.exe"
| argv[1]
| " E:\VS\Nut\Nut-Editor\assets\scenes\3DExample.yaml "
|
此时运行指令,你将会在启动时看到一个预先加载的场景。
|
》》》》碰到标题:
在理想状态下,运行指令后,步调应该能正常打开,但实际上我碰到了一些错误。
更新了着色器体系之后,我发现标题似乎出自文件路径。我推测是绝对路径和相对路径导致的错误。
|
| 第一个错误:"Could not open file from:…."
| 如今我将 Renderer2d.cpp 中的代码举行修改:(将此前的相对路径改为绝对路径)
| 第二个错误:我发现报错还来自这个函数: AddFontFromFileTTF ,于是我在使用这个函数的时间,将路径改为绝对路径(固然这会导致该应用的可移植性低落),但着实是无奈之举。
|
ImGuiLayer.cpp 中:
更改前:
更改后:
| 标题三:纹理加载中的路径修复
| 关于纹理的加载:
(ContentBrowserPanel.cpp)
(EditorLayer.cpp)
| 如今,便可以大概通过在终端输入:“E:\VS\Nut\bin\Debug-windows-x86_64\Nut-Editor\Nut-Editor.exe E:\VS\Nut\Nut-Editor\assets\scenes\3DExample.yaml”,来启动游戏引擎,并包管启动时预先加载了一个场景。
|
|
值得注意的是,由于缓存的存在,我们必要在单次文件之后,革新项目使得 bin/Nur-Editor/Nut-Editor.exe 文件运行的结果革新。
大概必要手动删除一些缓存文件(比方着色器缓存文件,OpenGLShader的更新中会涉及到),如许才气包管我们在终端使用指令运行游戏引擎的时间,得到最新的报错日志 等信息。 等信息。
TODO:
这里的调试本事就是将 相对路径 改为了 绝对路径 ,以此制止制止。但这非常影响项目标可移植性,我临时没有想到好的办理办法,如果有人可以增补,大概以后我有了想法,我会将其归并于项目代码中。
》》》》四:添加Uniform Buffer
》》关于 Uniform Buffer 的界说:具体可以查察( 高级GLSL - LearnOpenGL CN )
发起欣赏该页面之后,再查察更新的代码。
etc….
》》操纵步调
如今我们相识了 Uniform Buffer 的原理及其使用方式,如今开始更新代码:
起首
| 是设置与界说 UniformBuffer (UniformBuffer.h, UniformBuffer.cpp, OpenGLUniformBuffer.h, OpenGLUniformBuffer.cpp)
| 接着
| 是修改着色器中的同一变量,将其改为同一变量块( Uniform 块)
| 末了
| 必要更新实际绘制是,绑定同一变量的代码(之前是一个一个绑定,如今可以直接绑定 Uniform 块),使用时方便快捷。
|
示例:
|
| 运行机制:
具体可以参考
( 高级GLSL - LearnOpenGL CN )
|
|
以是在设置了 Uniform Buffer 之后,可以取消绑定着色器并绑定同一变量的操纵:
在更新代码以使用 Uniform Buffer 的时间,我发现一个标题:
条件:
我们在着色器中将两个同一变量更改为同一变量块,他们分别是:"u_ViewProjection"和"u_Textures"。
这都是为了UBO的使用而做的更改,由于Uniform buffer的使用必要在着色器同一变量块与UBO之间创建一种接洽:”Binding Points“ -> 绑定点。
必要做的修改:
固然,我们也必要在着色器做完更改之后,再去更新相应的代码,好比:
修改前(未使用 Uniform Buffer)
s_Data.TextureShader->SetMat4("u_ViewProjection", camera.GetViewProjectionMatrix());
| 在这里,我们直接将 u_ViewProjection 作为一个 mat4 变量通报给着色器,实现同一变量的直接绑定。
| 修改后(已使用 Uniform Buffer)
s_Data.CameraUniformBuffer = UniformBuffer::Create(sizeof(Renderer2DData::CameraData), 0);
…..
…..
s_Data.CameraUniformBuffer->SetData(&s_Data.CameraBuffer, sizeof(Renderer2DData::CameraData));
Eg: u_ViewProjection 的更新结果:
| 如今我们先创建了UBO,然后将着色器中的同一变量块(Uniform block)通过封装好的函数 "SetData()" ,绑定 UBO 到正确的绑定点 ( Binding Point).
|
疑问:
我发现 Cherno 固然为 u_Viewprojection 举行了更新,但是在将 u_Textures 由同一变量设置为同一变量块之后,他不但删除了之前体现绑定同一变量的代码,还没有对 u_Textures 举行类似的更新,这让我有点疑惑。
思考:
这个标题的缘故因由这是为何呢?
实在这和 Uniform buffer obj 没有很大的关系,这仅仅与 u_Textures 的一些特性有关。具体来讲,这和 OpenGL 纹理的特性相干。
答案:
纹理是 OpenGL 中的一种特别资源,在着色器中使用 layout(binding = 0) 声明绑定点后,你只需对纹理举行绑定操纵即可(将纹理绑定到对应的纹理单元),OpenGL 会自动处置惩罚纹理与着色器变量的映射。因此,在提前声明白 layout(binding = 0) 的环境下,纹理数组不必要像 UBO 那样通过 SetIntArray 或 SetData 来更新。
分析:
1. layout(binding = 0) 的原理
layout(binding = 0) 语法在 GLSL 中告诉 OpenGL,某个 uniform 变量(比方纹理或 UBO)会与一个 绑定点(binding point)关联。这种方式是 OpenGL 中的一种尺度机制,答应你将资源(如纹理、UBO)直接绑定到特定的资源绑定点,从而制止了逐个设置 uniform 值的贫困。
具体来说:
- 对于纹理(sampler2D、samplerCube 等):当你使用 layout(binding = N) 时,着色器的该纹理变量会与 OpenGL 中的绑定点 N 关联。
- 对于 Uniform Buffer Objects (UBO):UBO 的工作方式类似,也必要通过绑定点(binding = N)来绑定到 OpenGL 中某个绑定点
2. 但为什么纹理可以直接通过 layout(binding = 0) 来绑定,而不必要额外的操纵?
对于纹理数组(sampler2D u_Textures[32]),实在你并不必要像 UBO 那样来通报数据。由于纹理绑定在 OpenGL 中已经是一个非常内建的机制,你只必要使用 layout(binding = N) 来声明绑定点,而不必要手动通报纹理单元索引。就能直接将这些纹理单元与着色器中的纹理数组自动对应。
》》》》五:OpenGL Shader 更新
》》》》接下来我将对着色器体系举行相干更新。(此中包罗了: Vulkan 植入,日志错误提示的更新,着色器缓存文件的天生)
》》》关于 Timer 的使用
示例:
|
{
// 创建一个 Timer 对象
Hazel::Timer timer;
// 第一个操纵:模仿一个短时间的操纵
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // 模仿 500 毫秒的延伸
std::cout << "Time after first operation: " << timer.ElapsedMillis() << " ms\n";
// 重置计时器
timer.Reset();
// 第二个操纵:模仿一个稍长的操纵
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模仿 1 秒的延伸
std::cout << "Time after second operation: " << timer.ElapsedMillis() << " ms\n";
}
|
》》》》对着色器体系举行修改后,必要将 Premake 中的运行时静态链接关掉:
包罗 Nut/premake5.lua 、 Nut-Editor/premake5.lua、Nut/vendor/yaml-cpp/premake5.lua 这三个文件中的相干代码。
》》》》着色器中的 Location 要求
SPIR-V 作为 Vulkan 的中心表现语言,必要为每个输入/输出变量分配一个 location 值(为输入和输出变量明白指定 location 属性),以便于着色器编译器正确地将这些变量与 GPU 的管线绑定。
在 OpenGL 中,某些输入/输出变量(如顶点属性、uniforms等)可以通过其他方式来绑定。而在 Vulkan 中,SPIR-V 显式要求在着色器中为全部的输入和输出变量指定唯一的 location。
好比:
》》》》我差不多是直接复制了 OpenGLShader 更新的代码,以是没有细致查察,大概会增补关于更新的明白条记,我也不知道。
TODO:
(着色器更新中包罗了: Vulkan 植入,日志错误提示的更新,着色器缓存文件的天生 这几点)
在我做出更改之前,如果有人增补着色器中代码更新的细则与用意,我可以将其归并进来。
》》》》六:平台工具的更新(打开或生存文件)
》》》》这里我不消做更改,由于我的代码似乎是正确的。
》》》》七:视口与摄像机更新
》》》》 这里只是新增一些判定条件,非常简朴。
Anyway , 这一集的提交应该到此竣事了。这期间过了好久,并不是由于这一集很难,而是由于期末事变比力多,时间比力赶紧。
如今终于提交完毕了,无论怎样,请享受接下来的学习。
--------------------------------------- Content browser panel -----------------------------------
》》》》std::filesystem::relative( )
如果 s_AssetPath 是 C:\Projects\MyGame\Assets,path 是 C:\Projects\MyGame\Assets\Models\Character.obj。
那么 std::filesystem::relative(path, s_AssetPath) 会返回 Models\Character.obj,这是 path 相对于 s_AssetPath 的相对路径。
》》操纵图示:
第一次循环:
---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ----
第二次循环:
》》》》 "/=" 运算符重载
Eg.
"m_CurrentDirectory /= path.filename();"
/= 运算符的重载
概念:
在 C++17 的 std::filesystem::path 中,/= 运算符是被重载的,用于拼接路径。其功能是将路径对象 path 中的部门与左侧的路径举行归并。
使用要求:
m_CurrentDirectory 是一个表现当前目次的路径,通常是一个 std::filesystem::path 范例的对象。path.filename() 返回的是 path 对象中的文件名部门,且其范例也是 std::filesystem::path。
示例阐明:
假设
m_CurrentDirectory
| C:\Projects\MyGame\Assets。
| path
| C:\Projects\MyGame\Assets\Models\Character.obj。
| path.filename()
| Character.obj。
|
那么,m_CurrentDirectory /= path.filename(); 的结果会是 m_CurrentDirectory 便是 C:\Projects\MyGame\Assets\Character.obj
》》》》ImGui::Columns(columnCount, 0, false);
ImGui::Columns()
原型:
void ImGui::Columns(int columns_count = 1, const char* id = NULL, bool border = true);
参数表明:
columns_count
(范例:int,默认值:1)
| 功能:指定列的数量。默认值是 1,表现只有一列。如果你想创建多个列,可以设置为大于 1 的数字。
| id
(范例:const char*,默认值:NULL)
| 功能:这是一个可选的字符串,用来指定一个唯一的 ID。
如果多个列使用类似的 ID,ImGui 会为它们创建一个同一的状态。这个 ID 在 ImGui 的内部用于区分差异的列结构,但如果不必要区分,可以传入 NULL 或忽略它。
| border
(范例:bool,默认值:true)
| 功能:指定是否体现列之间的边框。如果为 true,列之间会有一个分隔线。如果为 false,则没有边框,列之间没有分隔线。
|
示例:
| 示例:ImGui::Columns(3) 表现创建 3 列结构。
|
| 示例:ImGui::Columns(3, "MyColumns"),通过指定 ID,可以在后续的操纵中区分差异的列结构。
|
| 示例:ImGui::Columns(3, NULL, false) 表现创建 3 列,而且不体现列间的边框。
|
》》》》一段错误代码诱发的思考:
错误的:
如果将 ImGui::ImageButton() 放在条件判定中,会导致优先判定按钮是否被单击,随后才会判定使用者是否在指定地区双击图标,这会导致鼠标双击的逻辑不能正常触发。
正确的
》》》》ImGui::TextWrapped()
概念:
ImGui::TextWrapped() 是一个用于在 ImGui 中体现文本的函数,紧张特点是当文本内容超出当前窗口或控件的宽度时,会自动换行体现。
这个特性实用于体现多行文本,由于文本宽度是动态的,可以顺应父容器的巨细。这制止了手动盘算的贫困。
函数原型:
void ImGui::TextWrapped(const char* fmt, ...);
void ImGui::TextWrapped(const std::string& str);
参数:
fmt:一个格式化字符串,答应你使用 ImGui 的格式化语法来插入变量。比方,可以传入一个字符串,大概传入多个参数,通过 fmt 来格式化它们。
str:传入一个 std::string 对象。它会自动转化为 C 字符串并体现在界面上。
用法:
1. 根本用法:
| ImGui::TextWrapped("This is a very long line of text that will automatically wrap when it reaches the edge of the window.");
| 2. 与格式化字符串一起使用:
你可以通过格式化字符串来体现动态内容。比方体现文件名、错误信息等。
| const char* filename = "example.txt";
ImGui::TextWrapped("The file %s has been loaded successfully.", filename);
| 3. 使用 std::string:
如果你有一个 std::string 对象,也可以直接传给 TextWrapped。
| std::string filename = "example.txt";
ImGui::TextWrapped(filename); // 直接体现 std::string 的内容
|
》》》》DragFloat 和 SliderFloat 的区别。
ImGui: ragFloat 和 ImGui::SliderFloat 的区别 ragFloat 和 ImGui::SliderFloat 的区别
DragFloat:
既可以通过鼠标在输入框中直接滑动,也可以输入值。
|
| SliderFloat :
只能操纵滑块来改变巨细。
|
|
--------------------- Content browser panel (Drag & drop) ----------------------------------
》》》》PushID 和 PopID 的作用是什么?PopID 是否可以放在 if 条件判定之前?
一:PushID 和 PopID 的作用
在 ImGui 中,当你渲染多个相似的控件(比方多个互动式按钮)时,它们通常会基于 ID 来管理本身的状态(如是否被点击、是否被悬停)。如果没有使用 PushID,这些控件大概会由于共享类似的 ID 而相互干扰(比方,全部的按钮都会共享同一个按下状态,大概鼠标悬停状态)。
通过 PushID 和 PopID,你确保每次循环渲染时,都为每个控件天生一个独特的 ID,如许每个文件的按钮、拖放等举动都能独立工作。
二:PopID 是否可以放在 If 判定之前?:不可以
如果在创建完控件之后就竣事 ID 的作用范畴,接下来的条件判定 if(ImGui::IsItemHovered() && ImGui::IsMouseDoubleClicked()) 将不再依赖于正确的 ID,而是随机的对某些按钮举行相应,这大概导致举动差异等或 UI 控件无法正常工作。
》》》》BeginDragDropTarget() 使用细则
如果手动跟进了 Cherno 的代码,我们会发现,使用 DragDrop 功能只必要两步操纵:设置拖动源、设置拖动目标。
拖动源的设置
(ContentBrowserPanel.cpp)
|
| 拖动目标的设置
(EditorLayer.cpp)
|
|
》》盘算const char* 范例字符串
如果有如许一个变量: const char* path = "abc/def/g"。盘算其长度时,如下两种方式,一个错一个对:
Sizeof(path)
| 错误:这行代码只盘算了指针的巨细,而不是整个字符串的巨细。(指针->指的是 "abc/def/g"中首字符的内存位置,也就是 'a' 在内存中的存储位置。
| (Strlen(path) + 1) * size(char)
| 正确: strlen() 盘算字符串的长度,但不包罗 '\0',故加一。然后对其乘以 char 范例的巨细,得到正确结果。
|
》》关于拖拽预览的绘制,还必要注意一点:
注意:在使用 BeginDragDropTarget( ) 之前,必要绘制一个有效的交互地区。
好比在视口的设置之后,我们使用了BeginDragDropTarget( ) ,你会发如今拖动文件到视口地区时,视口的可用地区会高亮,而且可以大概处置惩罚后续文件拖入操纵。
但是如果表明掉 ImGui::Image() 这一行代码,你会发现拖动文件的功能会无相应。
这是由于 ImGui::Image 不但体现了图像,还会自动处置惩罚它的交互地区,因此它是一个“有效”的拖放目标。
|
| 如果你只绘制了一个窗口,大概在窗口中放置了Text,Child等“不可交互”的空间,可用地区高亮便不会出现。同样的,文件拖动也会不起作用。
Eg.
|
| 此时便必要我们创建一个可交互的地区:ImGui::Button、ImGui:ummy 等等控件,以此来美满文件拖动的功能。
|
|
》》什么是 ImGui:ummy
概念:
ImGui:ummy 是 ImGui 提供的一个函数,用于创建一个“占位符”或“捏造”元素,它不会渲染任何实际的内容,但可以用来占据空间或提供一个交互地区。
紧张用途:
| 占位符:ImGui:ummy 可以作为一个占位符,资助你设置一些占用空间但不渲染任何实际内容的地区。这对于必要控制结构、调解空间或创建拖放目标地区非常有效。
控制结构:通过 ImGui:ummy,你可以创建正确的结构地区,而不会干扰其他控件的体现。比方,当你必要创建一个特定巨细的地区来吸收拖放操纵时,可以使用 Dummy 来占据空间。
| 语法:
| void ImGui:ummy(const ImVec2& size);
| 参数:
| size:指定占位符的巨细,通常是一个 ImVec2(x 和 y 坐标)。这界说了 Dummy 占据的地区的巨细。
| 示例:
| 假设你想在 ImGui 窗口中创建一个地区,它不会体现任何内容,但你盼望它占据一个特定的空间:
ImGui::Begin("Example Window");
// 创建一个巨细为 200x200 的占位符地区
ImGui:ummy(ImVec2(200, 200));
ImGui::End();
|
--------------------------------------- Texture Drag&Drop -------------------------------------------------------
》》》》好久没返来更新了,懒人一个。
之前把游戏引擎的视频看完了,但不绝疏于更新,接下来我好好更新。(真的)
》》》》没什么要记的
-------------------------------Something you need to know in GAME ENGINE ---------------------------------
》》》》看了一会看不动了,应该也没什么代码提交,So I skip that
-------------------------------------- Play Button ----------------------------------------
》》》》5:28 ~ 15:05 修复纹理扯破的Bug
》》》》 背面似乎也没什么好记的
ImGui::GetWindowContentRegionMax()
|
| 函数署名:
| ImVec2 ImGui::GetWindowContentRegionMax();
| 返回值:
| ImVec2 范例,表现当前窗口内容地区的最大坐标(右下角的坐标)。
| 通常与ImGui::GetWindowContentRegionMin()一起使用。
|
|
》》》》一些 ImGuiWindowFlags_ 的界说:
》》》》GL_LINER 和 GL_NEAREST 的概念及区别:
-------------------------------------- 2D Physics ----------------------------------------
》》》》概述
2:51 ~ 9:40 修复一个无法编译的错误
9:50 ~ 13:30 将 Box2D 设置为子模块
13:50 ~16:25 修改 Premake 文件
18:30~ 25:18 Box2D 使用表明
25:20~25:58 引擎的一些小改变
26:00~56:32 计划组件和实际使用 Box2D
56:32~ 1:08:00 UI 界面的设置以及结果运行展示
1:08:20~ 1:19:45 序列化与反序列化以及结果演示
》》》》网址 Box2D(3.1.0)
官网:
| Box2D
| 文档:
| Box2D: Overview
| Github:
| https://github.com/erincatto/box2d
|
非常发起在开始写代码前阅读(3.1.0):
简朴演示参考->
| Box2D: Hello Box2D
| 模仿时的代码参考 ->
| Box2D: Simulation (包罗了 ID, World, Body,Shapes,Contacts, Joints 的界说、初始化、概念等等)
|
》》》》网址(2.4.1)
官网:
| Box2D: Overview
| Github
| https://github.com/erincatto/box2d/tree/9ebbbcd960ad424e03e5de6e66a40764c16f51bc
|
》》》》开始之前
条件:
我发现有人曾经提示过版本更改的标题,Cherno 使用的是2.4.1,当前已经更新到 3.1.0。但我选择先使用 3.1.0 试试看,毕竟新的库更前卫一些,我也想尝尝鲜。
如果你想按照 Cherno 的想法来,就照他的方法做,使用 2.4.1。
如果你想保持 2.4.1 版本中的 C++ 特性,且对性能要求不敏感, 那就使用 2.4.1 。
更改和操纵:
3.0.1 相较于 2.4.1 有了较大变革,文件结构发生变革。别的,由 C++ 转换为了 C。(迁徙指南: Box2D: Migration Guide )
》》碰到的第一个错误:来自 Nut-Editor 的 LINK 错误,办理方式:
》》碰到的第二个错误:很多语法错误
而且全部的错误都指向一个函数:_Static_assert( )
我想这是由于没有将C语言的编译器设置为 /std:c11,由于_Static_assert( ) 是 c11 中的特性,在 C++11 中,这个函数被界说为 Static_assert( ) 。
我手动在 Box2D 的属性页中设置了 C 编译器,将其从默认(旧MSVC)修改为 ISO C11尺度(/std:c11)
》》但是尚有一个标题,就是我们无法将这个操纵写在 premake 文件中,即无法将其脚本化。
我搜集了很多论坛和答案,但是 premake 似乎无法为 msvc 提供符合的指令,也就是说没有可用的指令对 C 编译器的版本举行修改。
类似的指令有:buildoptions { "/std:c11" } 大概 buildoptions { "-std=c11"},但是这两个指令似乎只能针对 GCC/Clang 的 C 编译器,对其举行自动化更改。
这会导致一个结果,如果我选用了 Box2D 的 3.1.0 版本,为了在项目中正常使用 Box2D,则必须修改 MSVC 中的 C 编译器(以修正报错。但是我无法在 premake 中脚本化这个操纵,就只能手动设置。这时,如果在外部重新使用 bat 脚本(Win-GenProjects.bat)运行或更新项目,则会导致 Box2D API 受它本身的 Premake 脚本影响,从手动设置的 /std:c11 状态退回到默认(由于 premake 中的指令无法对 msvc 举行 C 编辑器的修改,纵然写下类似的代码,也相当于空缺,以是只要重新调用 Box2D 的 premake5.lua,就总是会撤回 VS 中手动设置 C 编辑器的版本)
这里我提供3个办理方案:
第一(我选择的)
| 退回至 Box2D 2.4.1 版本的使用,由于这个版本由C++开发而成,没有上述标题。固然性能不如 3.1.0 好,但现在引擎还没有碰到性能瓶颈,而且在项目中植入 C++ 很轻易。
| 第二
| 将 Box2D 在 MSVC 中 C 编辑器的修改,调解到独立于 premake 之外的脚本中,以实现自动化操纵。
| 第三
| 对 Box2D.vcsproj 直接举行修改,在该文件中直接标明 Box2d C 编辑器的版本为 /std:c11, 这个操纵大概会受到 premake 脚本重新运行的影响。(我是说大概,我也没有细致思考)
|
》》》》没想到颠末一番查证和思考,到头来照旧使用 Box2D 老版本。
https://github.com/JJJJJJJustin/box2d 这是我 fork 之后创建的库,此中有两个分支: main 代表最新的 Box2d, V2.4.1 代表 2.4.1 版本,你们可以使用。
》》》》我先提交序列化-反序列化部门的代码,然后再提交逻辑更新,以及UI设置。
》》》》return {}; 和 return; 的区别
return;
| 用于 void 函数,表现竣事函数。
| return {};
| 用于 有返回值的函数,它返回一个 默认初始化的对象,通常会将返回值设为范例的默认值(比方,0、nullptr、空字符串等)。
|
》》》》关于前向声明的位置标题(定名空间之内与定名空间之外)
定名空间的影响:
- 处于定名空间内部:Entity 的前向声明位于 Nut 定名空间内,这意味着编译器会以为这个 Entity 类是属于 Nut 定名空间的 Entity 类。
全部在 Nut::Scene 类中使用 Entity 范例的地方,编译器都会以 Nut 定名空间下界说的 Entity 类举行条件判定。
- 移到定名空间外部:如果你将前向声明移到 Nut 定名空间外,那么 Entity 类将不再被视为 Nut 定名空间的一部门。此时,编译器将 Entity 视为全局作用域中的一个类。
任安在 Nut 定名空间内使用 Entity 的地方,将无法正确辨认它是属于 Nut 定名空间的类,编译器将会在全局作用域中探求 Entity 类的界说。
结果:
- 如果 Scene 中的 Entity 使用的是定名空间内的 Entity(即 Nut::Entity),而前向声明被移到定名空间外部,就会导致编译错误,提示找不到 Nut::Entity。
- 编译器会试图查找一个全局作用域中的 Entity 类,而实际上你大概必要的是 Nut::Entity,因此会出现定名辩论或找不到类界说的标题。
》》》》关于初始化( OnRuntimeStart() )
》》》》关于内存走漏标题
如果 Delete 之后,不实验 m_PhysicsWorld = nullptr; 这句代码,会出现什么环境?
悬挂指针 (Dangling Pointer)
- 实验 delete m_PhysicsWorld; 会开释 m_PhysicsWorld 指向的内存,但 m_PhysicsWorld 本身仍旧持有之前指向已开释内存的地点。
- 如果后续实验使用 m_PhysicsWorld(比方访问它或再次删除它),会导致未界说的举动(通常是瓦解),由于 m_PhysicsWorld 如今是一个悬挂指针,指向已经无效的内存。
》》》》OnUpdateRuntime() 中的更新
》》》》OnRuntimeStart() 和 OnUpdateRuntime () 中代码的作用:
初始化 Box2d 天下, 并预先将全部物理属性附加到对象上
|
| 答应物理模仿,并每帧都更新物体的 Transform 以举行渲染
|
|
》》》》我发现 yaml 的序列化体系似乎没有将 Texture 的结果举行生存,每次进入引擎的场景之后,纹理都会被革新掉。
------------------------------------------ UUID ------------------------------------------------------
》》》》 xhash ?
》》》》代码明白:
》表明代码:
- std::random_device s_RandomDevice;
- std::random_device 是用于天生随机数的装备(通常依赖硬件或操纵体系提供的随机源),用来初始化 std::mt19937_64 引擎。
- std::mt19937_64 s_Engine(s_RandomDevice());
- s_Engine 是一个基于 std::mt19937_64 的随机数天生器。它的种子是从 s_RandomDevice 获取的一个值。
- std::uniform_int_distribution<uint64_t> s_UniformDistribution;
- s_UniformDistribution 是一个匀称分布对象,用于天生在某个范围内的随机整数。
- 当前这行代码并没有指定范围,默认环境下它天生的随机数范围是 [std::numeric_limits<uint64_t>::min(), std::numeric_limits<uint64_t>::max()],即 uint64_t 范例的最小值到最大值。
》范围设置 与 实际使用
默认环境下,s_UniformDistribution 可以天生的随机数范围是:std::numeric_limits<uint64_t>::min() ~ std::numeric_limits<uint64_t>::max()
即 0 ~ 2^64 - 1 -> (0, 18446744073709551615)
如果必要设置范围,可以如许操纵:
》》》》运算符重载的界说方式:
》》》》
operator uint64_t() const { return m_UUID; }
uint64_t operator() const { return m_UUID; }
这两个有什么区别?哪一个是运算符重载?
operator uint64_t() const { return m_UUID; }
- 目标:这是一个运算符重载,旨在将 UUID 范例的对象转换为 uint64_t 范例。
- 用途:当你想隐式或显式地将 UUID 范例转换为 uint64_t 范例时,会调用这个运算符。
- 示例:
Nut::UUID uuid(123456);
uint64_t val = uuid; // 隐式调用 operator uint64_t()
| uint64_t operator() const { return m_UUID; }
- 目标:这是一个函数调用运算符(operator()),它答应对象像函数一样被调用。这并不是范例转换运算符,而是界说了一个函数调用举动。
- 用途:你可以通过 () 操纵符调用一个 UUID 对象。比方,如果你实例化了 UUID 对象,可以像调用函数一样调用它,operator() 会返回 m_UUID 的值。
- 示例:
Nut::UUID uuid(123456);
uint64_t val = uuid(); // 调用 operator(),返回 m_UUID
- 结论:语法正确,可以大概使得 UUID 对象像函数一样被调用。
|
结论:
- 如果你的目标是将 UUID 对象转换为 uint64_t 范例,那么 第一个(operator uint64_t())更为符合。由于它是运算符重载,可以大概让 UUID 对象与 uint64_t 范例之间举行无缝转换。
- 如果你的目标是让 UUID 对象像函数一样被调用并返回 m_UUID,那么 第二个(uint64_t operator() const)是正确的。它实现了函数调用操纵符。
》》同样的,这里也可以看到 函数调用操纵符 的踪迹:
s_RD 只是对象本身,它本身并没有直接天生随机数。
| s_RD() 是对 std::random_device 对象的调用,它会天生一个随机数(通常是 unsigned int 范例),并返回。
s_RD() 实际上是调用 std::random_device 的 operator(),它返回一个随机数,并将这个数作为种子通报给 std::mt19937_64 引擎。
|
》》》》一些思考:
| Cherno的提交中,并没有为 IDComponent 提供这个自界说的构造函数。我以为这是一个会出现争议的地方。
|
| 在这个函数中,我们为 AddComponent<>() 传入了参数:uuid。
就我的明白来看,这里传入的 uuid ,将会被用来初始化 IDComponent 中的 ID,以是 IDComponent 中必要上述的构造函数。
在这里,我为 AddComponent() 填入的参数是 UUID(uuid),意为我使用了 UUID 中的构造函数:
而不是默认的构造函数,而默认的构造函数会天生随机的一段数字。
|
|
这里是 AddComponent() 的界说。
|
但从运行结果看来, Cherno 似乎并没有什么错误。不外我还没完成这一集的提交,稍后再来证实我是否正确。
》》毕竟证实没什么影响。
》》》》随机 ID 分发以及使用流程:
创建实体(创建时使用 CreateEntity() 函数,而不是 CreateEntityWithUUID() , 这会为新创建的实体分配一个随机 ID)
序列化文件:(我们会将默认随机分配的 ID 生存进设置文件)
反序列化文件:(读取文件中的文本数据,并将其重新用于实体组件的初始化。同时,ID 将会不绝保持在文本设置文件中,实体只有在最初创建时通过 CreateEntity() 函数得到其 UUID,之后便不绝存储在设置文件中,除非手动更改)
》》值得注意的是
如果你想像 Cherno 那样,先通过 Ctrl + Shift + S ,在生存文件的时间,更改全部实体的 ID 。(将实体的 ID 从之前设置的固定 ID 改为 随机的 UUID,则必要做以下更改)
先使用 UUID 的默认构造函数举行随机数分发:
|
| 当分发的 ID 被存储在 yaml 设置文件中之后,我们将其更改为图示。之后便可以不再更改这里的代码。
接下来只会有实体在创建之初,才会拥有一个新的 UUID(具体参考上述:》》》》随机 ID 分发以及使用流程:)
否则场景在被加载时,只会通过设置文件中的 ID 数据举行初始化,只要文件中的数据稳固,实体的 ID 将不绝保持。
|
|
》》》》一个疑惑:这两个代码结果应该是一样的。
-------------------------- Playing and stopping Scene ----------------------------------------------
》》》》这一集一共做了三件事:区别编辑器场景和运行时场景、制作复制实体的快捷键、重新设置生存&另存为这两个功能。
》》》》Unordered_map 中,通过下标访问对应值的方式 和 通过成员函数:at() 访问有什么差异?
|
- 如果 uuid 不存在,std::map 或 std::unordered_map 会自动插入一个新的元素,并将其值初始化为默认值(对于 std::map,键对应的值范例会调用默认构造函数)。
- 这种方式不抛出非常,且大概会导致不渴望的元素插入。
|
|
- 如果你不渴望检索并插入哈希表中未存在的值,at() 更加安全,由于它能防止这种环境发生,并抛出非常。
- at() 是一个成员函数,用于访问指定键 uuid 对应的值。如果找不到该键,它会抛出一个 std:ut_of_range 非常。
|
》》》》entt::registry 的成员函数 : replace 和 emplace_or_replace 有什么区别?
emplace_or_replace
|
- 功能: 实验在指定的实体上添加一个组件。如果该组件已存在,则会更换它。
- 举动:
- 如果实体没有该组件,emplace_or_replace 会创建并添加该组件。
- 如果实体已有该组件,emplace_or_replace 会更换(更新)现有的组件。
- 用途: 当你不确定组件是否已经存在,而且盼望确保该组件存在且始终是最新的时,使用 emplace_or_replace。
| replace
|
- 功能: replace 仅在实体已经拥有指定的组件时,才会举行更换操纵。
- 举动:
- 如果实体已经存在该组件,replace 会更换原有组件的值。
- 如果实体没有该组件,replace 什么都不做,并不会添加新组件。
- 用途: 如果你确定组件已经存在,而且只想更新它,使用 replace。
| emplace
|
- 功能: emplace 实验在指定的实体上添加一个组件。如果该组件不存在,则会根据参数构造新元素。
- 举动:
- 如果实体已经存在该组件,emplace 不会做任何修改,直接返回原来的组件。
- 如果实体没有该组件,emplace 会创建并添加该组件。
- 用途: 如果你确定组件不存在,使用 emplace。
|
》》》》void 范例的函数可以有返回值吗?
void 表现该函数不返回任何值。然而,void 范例的函数 可以有一个 return 语句,但是这个 return 语句 不能带有返回值。
你可以在 void 函数中使用 return; 来提前竣事函数的实验,但不能像返回值范例的函数那样使用 return some_value;。
》》》》有一个标题:不能通过简朴的单击“Hierarchy Panel”中的选项来选择实体,并举行复制。反而必要在单击选项之后,保持鼠标停顿在视口中,才气实现从“Hierarchy Panel”直接举行复制的操纵。
缘故因由在这里:只需将 !m_ViewportHovered 改为 m_ViewportHovered,但同时,视口中的图像也会受影响(无论鼠标是否在窗口中,图像都会受鼠标的操纵相应)
》》》》一些维护:
(EditorLayer.cpp)
1.防止运行时对场景举行滚轮调解,固然运行场景(运行时摄像机)没有变革,但编辑区(编辑时摄像机)会受影响的标题:
(ToolbarPanel.cpp)
2.修复未加载场景时,单击运行按钮导致的制止(现增长了提示小窗口)
(EditorLayer.cpp)
3.办理了“运行某一场景之后单击选择实体,此时单击停息按钮退出会导致步调瓦解” 的标题。
标题出现缘故因由:之前更新 m_UsingEntity 是根据鼠标单击更新的,这意味着 m_UsingEntity 并不是实时革新的。
以是每一次,如果在运行时选择了实体,此时实体属于运行时场景(ActiveScene)。而且这个场景在运行时被设置为 m_EditorScene 的副本(通过 Scene::Copy() ) 函数。此时 ActiveScene 指向 Scene::Copy(m_EditorScene) 的内存。
当我们通过按钮停息运行时,ActiveScene 会退出”m_EditorScene 的副本“这个身份,并被设置为”m_EditorScene 的引用“,此时 ActiveScene 指向 m_EditorScene 的内存。
但是,固然 ActiveScene 如今指向了差异的内存位置,我们用鼠标选择的实体却仍旧指向”m_EditorScene 的副本“的内存位置,由于实体是在运行场景中选择的(场景开始运行时,会使用 OnScenePlay(), 此中包罗:activeScene = Scene::Copy(editorScene); )。
此时的实体仍旧指向”m_EditorScene 的副本“这里的内存位置,也就是 Scene::Copy() 的返回值,但是这个函数的返回值已经被烧毁了,以是会造成内存走漏。
-------------------------------------- Rendering Circles ----------------------------------------
》》》》概述
0:00 ~ 8:41 Hazel3D 中对于圆形渲染和多边形碰撞的演示
8:42 ~ 13:18 一些赘述
13:18~19:36 CircleComponent 的设置、CircleComponent UI 绘制、CircleComponent 的添加途径
19:45~35:42 渲染代码的编写
35:45~42:42 着色器的编写
42:44 ~ 44:43 渲染函数的更新
44:44~54:22 调试与演示
54:43~1:00:00 边沿检测和选中物体
1:00:04~1:01:55 圆形渲染调试
1:02:00 ~ 1:04:27 序列化文件
》》》》这一集内容虽多,但没有什么条记可以做。
》》》》记载一个标题:(未办理)
在好久从前,我不知出于什么缘故因由,在 DrawIndexed() 函数中,通过传入的参数 indexCount 直接运行了 glDrawElements() 这个函数,不绝以来没有导致什么标题。
这个缘故因由大概是:如果 s_QuadIndexCount 可以大概进入该条件判定,则表明 QuadIndexCount 是有数据的,以是不必要在 RendererCommand:rawIndexed() 函数中额外添加一个条件判定:(判定indexCount 是否为空)
按理来说,无论我在 RendererCommand:rawIndexed() 中使用/不使用 三元表达式来举行判定,函数渲染的结果都应该正常,但当决定重新启用这个三元表达式时,我的渲染却出现了标题。
如下:(如果鼠标位移至右上角错误地区,会导致步调瓦解:
瓦解位置:
》》》》实验:将 Local Position 改为 vec2
length 函数:
用于盘算一个向量的欧几里得范数(即向量的长度或模)
它的界说:
|
float length(vec2 v);
float length(vec3 v);
float length(vec4 v);
|
》》》》TODO:明白 Circle Shader 中渲染圆形代码的运行机制。
---------------------------------- Rendering Lines -------------------------------------------------
》》》》也没啥要记的。记得不要把 GL_LINES 写成 GL_LINE, 而且不要把线条的 alpha 通道误设为 0 ,否则你看不见线条。
---------------------------------------------- Circle collider ------------------------------------------------
》》》》m_P 指的是?
m_P 指的是 m_Position,用来存储圆的位置,依此来模仿碰撞时的数据。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
|







 发表于
发表于 



























































































































































































































































































