日常分析数据时,只有单一数据文件的情况其实很少见,更多的情况是,
我们从同一个数据来源定期或不定期的采集了很多数据文件;或者从不同的数据源采集多种不同格式的数据文件。
在这样的情况下,分析数据之前,需要将不同的数据集合并起来。
合并数据一般有两个维度,一是同构的数据集合并后行数增加;一是异构的数据集合并后列数增加。
1. 同构数据集
比如我们采集了3个不同年份的人口统计文件,分别为:- import pandas as pd
- fp1 = "population1.csv"
- df = pd.read_csv(fp1)
- df
 - import pandas as pd
- fp2 = "population2.csv"
- df = pd.read_csv(fp2)
- df
 - import pandas as pd
- fp3 = "population3.csv"
- df = pd.read_csv(fp3)
- df
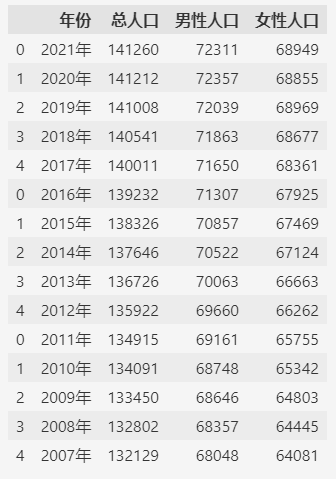
合并所有的数据集可以用 pd.concat 方法,不过一个一个文件读取之后再合并比较麻烦。
如果文件名称有规律的话(一般定期采集的数据集文件,文件名都有一定的规律),可以通过 glob 库(支持通配符匹配)来匹配所有数据文件。
然后利用python代码的灵活性一次合并所有的数据。- from glob import glob
- files = sorted(glob("./population[1-3].csv"))
- df = pd.concat((pd.read_csv(f) for f in files))
- df
这样合并之后,发现索引是有重复的,如果要保持索引的唯一性,可以在合并时指定 ignore_index=True。- df = pd.concat((pd.read_csv(f) for f in files), ignore_index=True)
- df
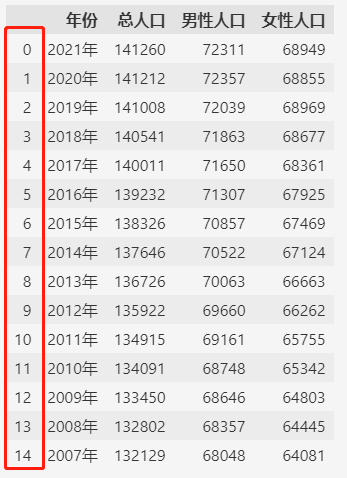
2. 异构数据集
异构的数据集指数据结构不一样的数据,一般来自于不同的数据源。
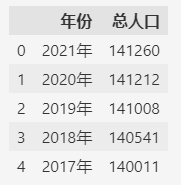
比如:- import pandas as pd
- fp1 = "population-total.csv"
- df = pd.read_csv(fp1)
- df
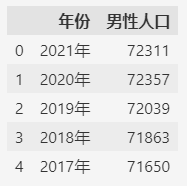
 - import pandas as pd
- fp2 = "population-man.csv"
- df = pd.read_csv(fp2)
- df
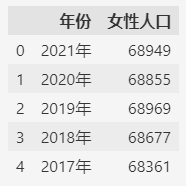
 - import pandas as pd
- fp3 = "population-woman.csv"
- df = pd.read_csv(fp3)
- df
合并的方式和前面按行合并类似,区别在于指定 axis=1。- from glob import glob
- files = sorted(glob("./population-*.csv"))
- df = pd.concat((pd.read_csv(f) for f in files), axis=1)
- df
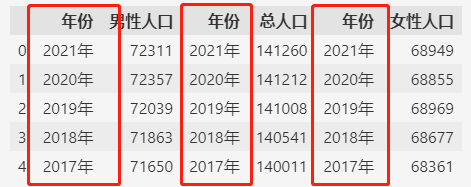
合并之后发现有重复的列,对于重复的行,可以简单的通过 drop_duplicates()方法来去重,
去除重复的列则需要一些技巧。- df = df.loc[:, ~df.columns.duplicated()]
- df
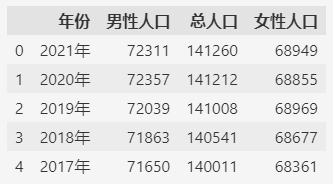
这样就去除了重复的列,完成了异构数据集的合并。
3. 附录
本篇使用的示例数据可以通过下面的url下载:
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |










