一:在hadoop3.3中安装配置sqoop1.4.7
前言:
sqoop功能已经非常完善了,没有什么可以更新的了,官方停止更新维护了。因此官方集成的hadoop包停留在了2.6.0版本,在hadoop3.3.0版本会提示类版本过低错误,但纯净版sqoop有缺少必须的第三方库,所以将这两个包下载下来,提取部分sqoop_hadoop2.6.0版本的jar包放到纯净版sqoop的lib目录下,在sqoop配置文件中加入获取当前环境中的hive及hadoop的lib库来使用.
配置sqoop1.4.7 支持hadoop3.3
1:下载sqoop1.4.7的两个版本
http://archive.apache.org/dist/sqoop/1.4.7
sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz # 只用到里面的jar包
sqoop-1.4.7.tar.gz # 上传到服务器
2:提取sqoop-1.4.7.bin__hadoop-2.6.0根目录下的sqoop-1.4.7.jar放到sqoop-1.4.7根目录,正常纯净版sqoop是没有这个jar包的
3:提取lib目录下的这三个必须的jar包放到sqoop-1.4.7/lib/目录下,正常纯净版sqoop的lib目录下是没有文件的。
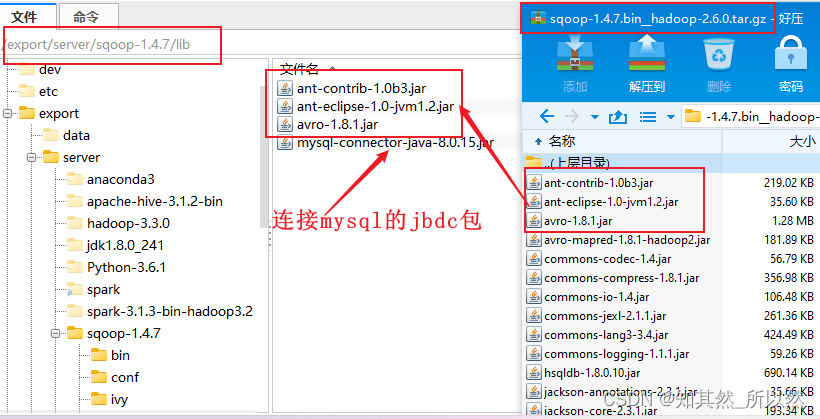
4:提取出sqoop-1.4.6.jar放在hadoop的lib下
添加sqoop配置信息,引用hadoop,hive的lib库
sqoop-1.4.7/conf 目录下的sqoop-env.sh文件追加如下信息- export HADOOP_COMMON_HOME=/export/server/hadoop-3.3.0
- export HADOOP_MAPRED_HOME=/export/server/hadoop-3.3.0
- export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
- export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
- export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
在/etc/profile 中添加- export SQOOP_HOME=/export/server/sqoop/
- export PATH=$PATH:$SQOOP_HOME/bin:$SQOOP_HOME/bin
sqoop的数据导入操作
1:sqoop help 查看帮助文档命令
2:查看数据库中的所有表- sqoop list-tables \
- --connect jdbc:mysql://192.168.52.150:3306/hue \
- --username root \
- --password 123456
  - 命令1:
- sqoop import \
- --connect jdbc:mysql://192.168.50.150:3306/test \
- --username root \
- --password root \
- --table emp
- 说明:
- 默认情况下, 会将数据导入到操作sqoop用户的HDFS的家目录下,在此目录下会创建一个以导入表的表名为名称文件夹, 在此文件夹下莫每一条数据会运行一个mapTask, 数据的默认分隔符号为 逗号
-
- 思考: 是否更改其默认的位置呢?
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp \
- --delete-target-dir \
- --target-dir '/sqoop_works/emp_1'
- 思考: 是否调整map的数量呢?
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp \
- --delete-target-dir \
- --target-dir '/sqoop_works/emp_2' \
- --split-by id \
- -m 2
- 思考: 是否调整默认分隔符号呢? 比如调整为 \001
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp \
- --fields-terminated-by '\001' \
- --delete-target-dir \
- --target-dir '/sqoop_works/emp_3' \
- -m 1
- 以emp_add 表为例
- 第一步: 在HIVE中创建一个目标表
- create database hivesqoop;
- use hivesqoop;
- create table hivesqoop.emp_add_hive(
- id int,
- hno string,
- street string,
- city string
- )
- row format delimited fields terminated by '\t'
- stored as orc ;
- 第二步: 通过sqoop完成数据导入操作
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp_add \
- --hcatalog-database hivesqoop \
- --hcatalog-table emp_add_hive \
- -m 1
- 方式一: 通过 where的方式
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp \
- --where 'id > 1205' \
- --delete-target-dir \
- --target-dir '/sqoop_works/emp_2' \
- --split-by id \
- -m 2
- 方式二: 通过SQL的方式
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --query 'select deg from emp where 1=1 AND \$CONDITIONS' \
- --delete-target-dir \
- --target-dir '/sqoop_works/emp_4' \
- --split-by id \
- -m 1
- 注意:
- 如果SQL语句使用 双引号包裹, $CONDITIONS前面需要将一个\进行转义, 单引号是不需要的
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp_add \
- --where 'id > 1205' \
- --hcatalog-database hivesqoop \
- --hcatalog-table emp_add_hive \
- -m 1
- 或者:
- sqoop import \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --query 'select * from emp_add where id>1205 and $CONDITIONS'
- --hcatalog-database hivesqoop \
- --hcatalog-table emp_add_hive \
- -m 1
需求: 将hive中 emp_add_hive 表数据导出到MySQL中- # 第一步: 在mysql中创建目标表 (必须创建)
- create table test.emp_add_mysql(
- id INT ,
- hno VARCHAR(32) NULL,
- street VARCHAR(32) NULL,
- city VARCHAR(32) NULL
- );
- # 第二步: 执行sqoop命令导出数据
- sqoop export \
- --connect jdbc:mysql://192.168.52.150:3306/test \
- --username root \
- --password 123456 \
- --table emp_add_mysql \
- --hcatalog-database hivesqoop \
- --hcatalog-table emp_add_hive \
- -m 1
参数说明--connect连接关系型数据库的URL--username连接数据库的用户名--password连接数据库的密码--driverJDBC的driver class--query或--e 将查询结果的数据导入,使用时必须伴随参--target-dir,--hcatalog-table,如果查询中有where条件,则条件后必须加上关键字。如果使用双引号包含,则CONDITIONS前要加上\以完成转义:$CONDITIONS--hcatalog-database指定HCatalog表的数据库名称。如果未指定,default则使用默认数据库名称。提供 --hcatalog-database不带选项--hcatalog-table是错误的。--hcatalog-table此选项的参数值为HCatalog表名。该--hcatalog-table选项的存在表示导入或导出作业是使用HCatalog表完成的,并且是HCatalog作业的必需选项。--create-hcatalog-table此选项指定在导入数据时是否应自动创建HCatalog表。表名将与转换为小写的数据库表名相同。--hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \建表时追加存储格式到建表语句中,tblproperties修改表的属性,这里设置orc的压缩格式为SNAPPY-m指定并行处理的MapReduce任务数量。 -m不为1时,需要用split-by指定分片字段进行并行导入,尽量指定int型。--split-by id如果指定-split by, 必须使用$CONDITIONS关键字, 双引号的查询语句还要加\--hcatalog-partition-keys --hcatalog-partition-valueskeys和values必须同时存在,相当于指定静态分区。允许将多个键和值提供为静态分区键。多个选项值之间用,(逗号)分隔。比如: --hcatalog-partition-keys year,month,day --hcatalog-partition-values 1999,12,31--null-string '\N' --null-non-string '\N'指定mysql数据为空值时用什么符号存储,null-string针对string类型的NULL值处理,--null-non-string针对非string类型的NULL值处理--hive-drop-import-delims设置无视字符串中的分割符(hcatalog默认开启)--fields-terminated-by '\t'
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |







 发表于 2023-4-4 14:35:03
发表于 2023-4-4 14:35:03