mapreduce.jobhistory.address hadoop102:10020 mapreduce.jobhistory.webapp.address hadoop102:19888- 7. 配置workers,hadoop2.X版本是slaves文件,添加以下内容
hadoop103
hadoop104
- 12. 分发配置xsync ./
- #### 基本测试(格式化、启动、停止),hadoop-3.3.1目录下:
- 13.1 格式化NameNode:hdfs namenode -format;如果不是第一次格式化需要停止NameNode和DataNode,删除所有机器上的data和logs目录,否则因为格式化后NameNode中保存了集群id,启动集群后DataNode也会保存与NameNode一样的集群id,如果再次格式化NameNode会新生成一个集群id,这个集群id与为删除的DataNode中的集群id不一致。
- 13.2 启动hdfs:sbin/start-dfs.sh
- 13.3 启动yarn:sbin/start-yarn.sh
- 13.4 查看hdfs和yarn的web页面:http://hadoop102:9870,http://hadoop103:8088
- 13.5 创建一个文件夹,hadoop fs -mkdir /input
- 13.6 上传一个文件,hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
- 13.7 在目录下有test文件,执行wordcount程序 :hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /test;观察http://hadoop102:19888/jobhistory历史服务器历史任务。
- 14. 集群启动/停止方式:
- 14.1 整体停止/启动HDFS:start-dfs.sh/stop-dfs.sh
- 14.1 整体停止/启动YARN:start-yarn.sh/stop-yarn.sh
- 14.3 分别启动/停止hdfs组件:hadoop-daemon.sh start/stop 【namenode/datanode…】
- 14.4 别启动/停止YARN:yarn --daemon start/stop resourcemanager/nodemanager
- 15. [集群时间同步]( )
- #### 集群脚本编写/home/xrl/bin目录下:
- 1. 集群分发脚本xsync,创建xsync文件写入以下内容:
#1. 判定参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
- for file in $@
- do
- #4. 判断文件是否存在
- if [ -e $file ]
- then
- #5. 获取父目录
- pdir=$(cd -P $(dirname $file); pwd)
- #6. 获取当前文件的名称
- fname=$(basename $file)
- ssh $host "mkdir -p $pdir"
- rsync -av $pdir/$fname $host:$pdir
- else
- echo $file does not exists!
- fi
- done
- 1.1 修改xsync的执行权限:chmod +x xsync
- 1.1 将脚本复制到bin中,以便全局调用:sudo cp xsync /bin/
- 1.1同步环境变量配置 sudo ./bin/xsync /etc/profile.d/my\_env.sh
- 1.1 让环境变量生效:source /etc/profile
- 1.1 测试分发:xsync /home/xrl/bin;观察hadoop103 104上是否有这个文件了。
- 2. Hadoop集群启停脚本myhadoop.sh:
if [ $# -lt 1 ]
then
echo “No Args Input…”
exit ;
fi
case $1 in
“start”)
echo " =================== 启动 hadoop集群 ==================="
- echo " --------------- 启动 hdfs ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.3.1/sbin/start-dfs.sh"
- echo " --------------- 启动 yarn ---------------"
- ssh hadoop103 "/opt/module/hadoop-3.3.1/sbin/start-yarn.sh"
- echo " --------------- 启动 historyserver ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.3.1/bin/mapred --daemon start historyserver"
“stop”)
echo " =================== 关闭 hadoop集群 ==================="
- echo " --------------- 关闭 historyserver ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.3.1/bin/mapred --daemon stop historyserver"
- echo " --------------- 关闭 yarn ---------------"
- ssh hadoop103 "/opt/module/hadoop-3.3.1/sbin/stop-yarn.sh"
- echo " --------------- 关闭 hdfs ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.3.1/sbin/stop-dfs.sh"
*)
echo “Input Args Error…”
;;
esac
- 2.1 chmod +x myhadoop.sh
- 2.2 分发这个脚本 xsync ./
- 3. jpsall查看节点类型
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
- 3.1 chmod +x jpsall
- 3.2 分发这个脚本 xsync ./
- ## Hdoop-HDFS
- ### 定义
- HDFS的是基于流数据模式访问(来了一点数据,就立马处理掉,立马分发到各个存储节点来响应分析、查询等,重点关注数据的吞吐量而不是访问速率)和处理超大文件的需求而开辟的一个主从架构的分布式文件系统(分布式文件系统:一种允许文件透过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间);
- 流式数据: 将数据序列化为字节流来存储;
- 序列化:对文件进行切片就需要该文件支持序列化;
- 存储文件,通过目录树定位文件;
- 适合一次写入,多次读出的场景。一个文件只能有一个写者,只能进行append追加内容,不能修改。
优点
- 高容错性:数据保存了多个副本,一个副本丢失或者破坏,可以主动规复,默认保存三个副本。
- 适合处理大数据,可以处理的数据规模和文件规模巨大。
- 可以构建在廉价机器上,数据保存多副本的机制提高了可靠性
- 适合处理离线数据,不适合处理及时数据。
- 可以处理:布局化(关系型)、半布局化(word,ppt)、非布局化(视频,音频)数据;
缺点
- 不适合低延时的数据访问;(hadoop针对高数据吞吐量做了优化,牺牲了获取数据延迟)
- 无法高效的对小文件进行存储。由于,大量的小文件会大量占用NameNode的内存来存储文件目录和块信息。而且会影响文件存储地址的寻址时间。解决办法:通过SequenceFile 将小文件合并。
- 不支持并发写入和文件随机修改,只支持数据的追加,不能修改。
dfs.balance.bandwidthPerSec 104857600 22 * * 5 hdfs balancer -Threshold 5 >>/home/logs/balancer_date +"\%Y\%m\%d".log
- ### 安全模式
- 1. 安全模式指在不加载第三方设备驱动情况下启动机器,便于检测与修复
- 2. 应用场景:①启动或者重新启动hdfs时;②HDFS维护升级时
- 3. 操作:
- 退出安全模式:hdfs dfsadmin -safemode leave
- 进入安全模式 :hdfs dfsadmin -safemode enter
- 查看安全模式状态:hdfs dfsadmin -safemode get
- 等待,直到安全模式结束:hdfs dfsadmin -safemode wait
- #### 文件系统检查
-move: 移动破坏的文件到/lost+found目录下
-delete: 删除破坏的文件
-files: 输出正在被检测的文件
-openforwrite: 输出检测中的正在被写的文件
-includeSnapshots: 检测的文件包括系统snapShot快照目录下的
-list-corruptfileblocks: 输出破坏的块及其所属的文件
-blocks: 输出block的详细陈诉
-locations: 输出block的位置信息
-racks: 输出block的网络拓扑布局信息
-storagepolicies: 输出block的存储策略信息
-blockId: 输出指定blockId所属块的状态,位置等信息
- ##### API实现步骤和源码([参考]( ))
- ### 部分配置设置
- 1. Secondary NameNode和NameNode,CheckPoint条件设置(hdfs-site.xml):
- 1.1 时间:< name > dfs.namenode.checkpoint.period< /name >
- 1.2 操作次数:< name > dfs.namenode.checkpoint.txns < /name >
- 1.3 检查一次操作次数间隔时长:< name > dfs.namenode.checkpoint.check.period< /name>
- 2. DataNode向NameNode汇报节点信息周期时间和扫描自己节点块信息列表的时间设置:
- 2.1汇报节点信息周期时间:< name> dfs.blockreport.intervalMsec < /name>
- 2.2扫描自己节点块信息列表的周期时间:< name>dfs.datanode.directoryscan.interval< /name>
- 3. DataNode掉线时限参数设置:
- 3.1超时时长(毫秒): < name>dfs.namenode.heartbeat.recheck-interval< /name>
- 3.2心跳时长(秒)< name>dfs.heartbeat.interval</ name>
- ### 基本Shell命令和API操作
- #### 基本文件系统Shell命令([官方文档]( )):
- hadoop fs == hdfs dfs
- 1. 上传
- 1.1 从本地剪切:hadoop fs -moveFromLocal 【本地文件路径】 【HDFS路径】
- 1.2 从本地拷贝:hadoop fs -copyFromLocal 【本地文件路径】 【HDFS路径】
- 1.3 从本地拷贝:hadoop fs put 【本地文件路径】 【HDFS路径】
- 1.4 追加一个文件到另一个文件末尾:hadoop fs -appendToFile 【追加文件路径】 【待追加文件路径】
- 2. 下载
- 2.1:hadoop fs -copuToLocal 【HDFS文件路径】 【本地路径】
- 2.2:hadoop fs -get 【HDFS文件路径】 【本地路径】
- 3. 显示目录信息:hadoop fs -ls 【查看目录路径】
- 4. 查看文件内容:hadoop fs -cat 【文件路径】
- 5. 显示文件末尾1kb数据:hadoop fs -tail 【文件路径】
- 6. 创建路径:hadoop fs -mkdir 【目录路径】
- 7. 拷贝文件:hadoop fs -cp 【原文件路径】【文件路径】
- 8. 移动文件:hadoop fs -mv 【文件路径】 【移动到(路径)】
- 9. 删除文件或文件夹:hadoop fs -rm 【文件路径】
- 9.1 hadoop fs -rm -r【文件路径】(递归删除)
- 10. 统计文件大小:hadoop fs -du 【文件目录路径】
- 11. 查询某一个文件所占用块数及相关的数据信息:hdfs fsck 【文件路径】 -files -locations -includeSnapshots -blocks -racks -storagepolicies
- 12. 设置HDFS中的文件副本数量: hadoop fs -setrep 【副本数量】 【修改文件的路径】
- 13. 文件权限操作:
- 12.1 权限设置:hadoop fs -chmod 666 【文件路径】
- 12.2 文件所属者设置:hadoop fs -chown xrl:xrl 【文件路径】
- 14. 查看Fsimage和Edits,hadoop-3.3.1/data/tmp/dfs/name/current目录下:
- 13.1 hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
- 13.1.1 hdfs oiv -p XML -i fsimage\_0000000000000000025 -o /opt/module/hadoop-3.3.1/fsimage.xml
- 13.1.2 cat /opt/module/hadoop-3.3.1/fsimage.xml
- 13.2 hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
- 13.2.1 hdfs oev -p XML -i edits\_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.3.1/edits.xml
- 13.2.2 cat /opt/module/hadoop-3.3.1/edits.xml
- 15. version查看版本:hadoop version
- 16. classpath查看类路径: hadoop classpath
- #### HDFS命令 ([参考]( ))([官方文档]( ))
- 1. 格式化、启动、停止参考上文中VM集群配置的基本步骤中的基本测试;
- 2. hdfs dfsadmin 命令集
- 3. hdfs fsck 运行HDFS文件系统检查工具
- 4. hdfs getconf 命令集
- 5. hdfs jar 运行jar文件。用户可以把他们的Map Reduce代码捆绑到jar文件中,使用这个命令执行。
- 6. hdfs job 用于和Map Reduce作业交互和命令。
- 7. hdfs balancer
- API操作:
- ### HA(High Available)机制
- #### 解决问题
NameNode的内存有限(内存受限)
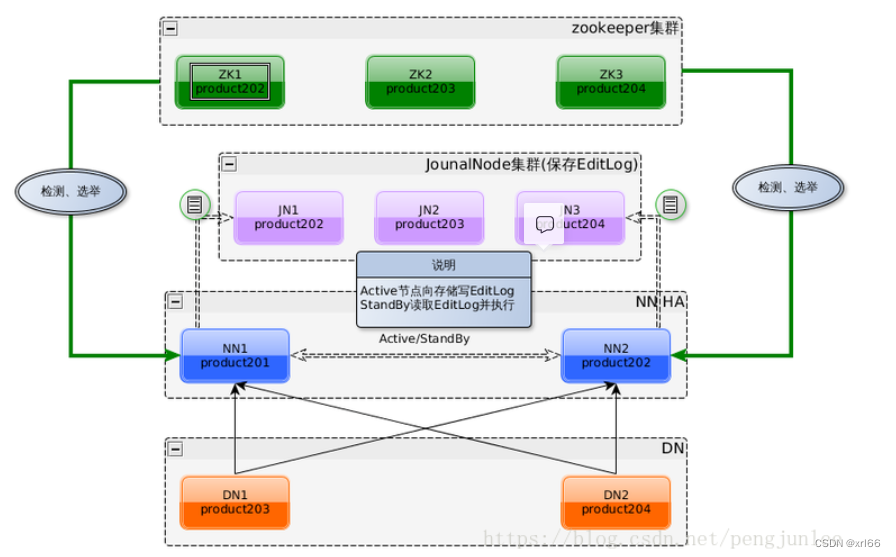
- #### NameNode高可用(HA)
- ##### 架构图
- 1. 使用了两个NameNode架构,解决了单点故障问题;
- 2. 借助了共享存储系统(JournalNode集群)来保证元数据的同步,共享存储系统类型一般有几类,如:Shared NAS+NFS、BookKeeper、BackupNode 和 Quorum Journal Manager(QJM)
- 3. 使用了zookeeper来进行选举active节点;
- 
- ##### QJM(Quorum Journal Manager)共享存储机制和主备切换机制([参考]( ))
- ##### 配置修改
- ###### 配置zookeeper集群
- 1. 进入conf目录,修改zoo\_sample.cfg并重命名zoo.cfg:mv zoo\_sample.cfg zoo.cfg;
- 2. 修改zoo.cfg
initLimit=10
syncLimit=5
数据存储地址,提前创建这个目录(注意目录权限)
dataDir=/opt/module/zookeeper-3.7.0/zkData
配置zookeeper集群的服务器编号以及对应的主机名、通信端标语(心跳端标语)和选举端标语
server.1=hadoop102:2888:3888
server.2=hadoop103:2888:3888
server.3=hadoop104:2888:3888
clientPort=2181
- 4. 在dataDir=/opt/module/zookeeper-3.7.0/zkData这个目录下创建myir文件,haoop102设置1,103设置2,以此类推;
- 5. 修改环境变量/etc/profile.d/my\_env.sh
export PATH= P A T H : PATH: PATH:ZK_HOME/bin
#!/bin/bash
case $1 in
“start”){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i “/opt/module/zookeeper-3.7.0/bin/zkServer.sh start”
done
};;
“stop”){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i “/opt/module/zookeeper-3.7.0/bin/zkServer.sh stop”
done
};;
“status”){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i “/opt/module/zookeeper-3.7.0/bin/zkServer.sh status”
done
};;
esac
- 7. 运行
- ###### 配置文件修改
- 1. core-site.xml
- ###### 启动步骤
- 1. Hadoop处于关闭状态;
- 2. 安装系统插件:yum -y install psmisc;
- 3. 启动zookeeper;
- 4. 删除所有节点的$HADOOP\_HOME下的:rm -rf data/ logs/ ;
- 5. 启动JN:hadoop-daemon.sh start journalnode
- 6. 格式化NameNode:在一台namenode( namenode1或namenode2)中执行格式化命令:hdfs namenode -format
- 7. 在另一台namenode同步数据前先要启动 第10步中格式化的 namenode:hadoop-daemon.sh start namenode
- 8. 在其它没有格式化的namenode上执行:hdfs namenode -bootstrapStandby
- 9. 在一台namenode上执行格式化zookeeper:hdfs zkfc -formatZK
- 10. 测试zk是否成功格式,且启动 :zkCli.sh -server hadoop102:2181
- 11. 脚本启动zk集群和Hadoop集群:zk.sh start / myhadoop.sh start
- 12. 用jpsall脚本查看各个服务启动情况:DFSZKFailoverController
- (故障恢复,它与namenode在一个节点上,当一个节点失败时,自动恢复)
- 13. 查看:http://hadoop102:50070,http://hadoop104:50070 一个为Active一个为Standby
- 14. 关闭为Active的NameNode节点:hadoop-daemon.sh stop namenode,观察Standby是否转为Active;
- #### YARN高可用(HA)
- ##### 修改配置文件yarn-site.xml
- [解决hadoop执行MapReduce程序时Ha和yarn的冲突 YarnRuntimeException: java.lang.NullPointerException]( )
- ##### 启动步骤
- 1. 关闭集群
- 2. 删除删除所有节点的$HADOOP\_HOME下的:rm -rf data/ logs/ ;
- 3. 删除journalnode的数据:/opt/journal/node/local/data/下的xrlhadoop;
- 4. 启动所有节点上的JND;
- 5. 格式化一个NameNode:hadoop namenode -format
|









