一,监督学习和无监督学习聚类的数据集比力:
监督学习: 数据集包罗输入的数据和与之对应的标签
无监督学习: 数据集仅含有输入的数据,要求算法自己通过所给的数据集来确定决定界限
二,聚类(Clustering):
聚类,即通过给定的数据集,模子自己实行看看是否可以将其分组为集群
聚类的实现:
K-means(K均值算法):
一种无监督学习,将未标记的数据集分别为K个差别的聚集,其焦点目的是最小化簇内平方偏差和(即实现数据集到集群中央的隔断的最小化)
焦点步调:
将群会合心中央随机分配给簇,然后再重复将点分配给群会合心并移动群会合心,直到到达克制条件
实现步调:
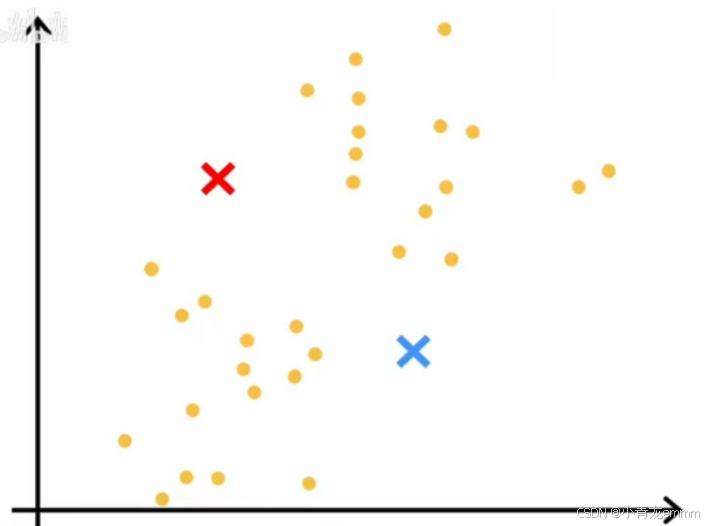
①给群会合心赋点: 起首举行随机推测,确定集群的中央(如下图中的红蓝叉)
②移动群会合心: 通过所给数据集盘算,每个数据更靠近红叉照旧蓝叉,通过比力来把数据分配给更近的群会合心(把数据分给群会合心)
③重复上述①②使用,根据已有的数据到群会合心的隔断,分别算出均匀值,再根据均匀值来继承移动群会合心,重复使用知道找到最优的群会合心
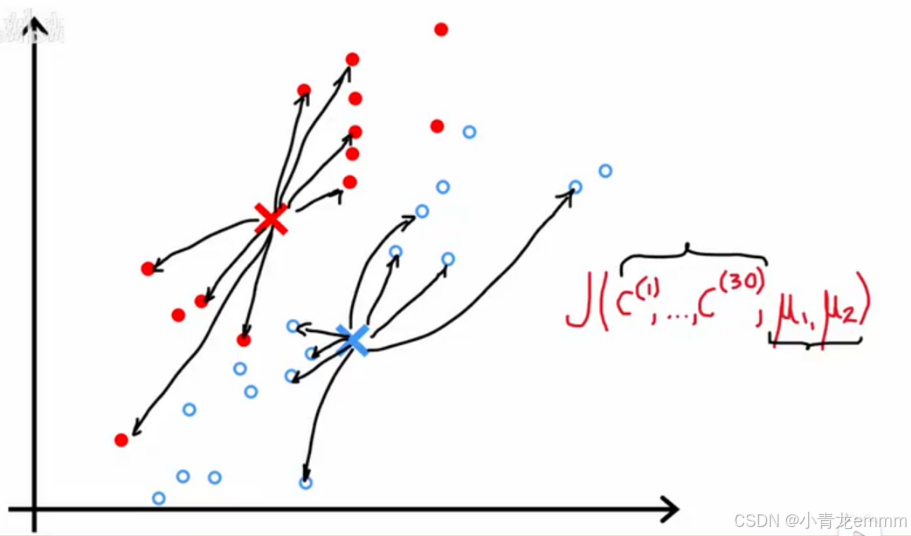
K-means的本钱函数:

丧失函数表现图:
K-means详细实现:
随机天生集群中央,并分别盘算其丧失函数,不停循环(通常在50-1000次)来找到最小丧失函数,实现最优
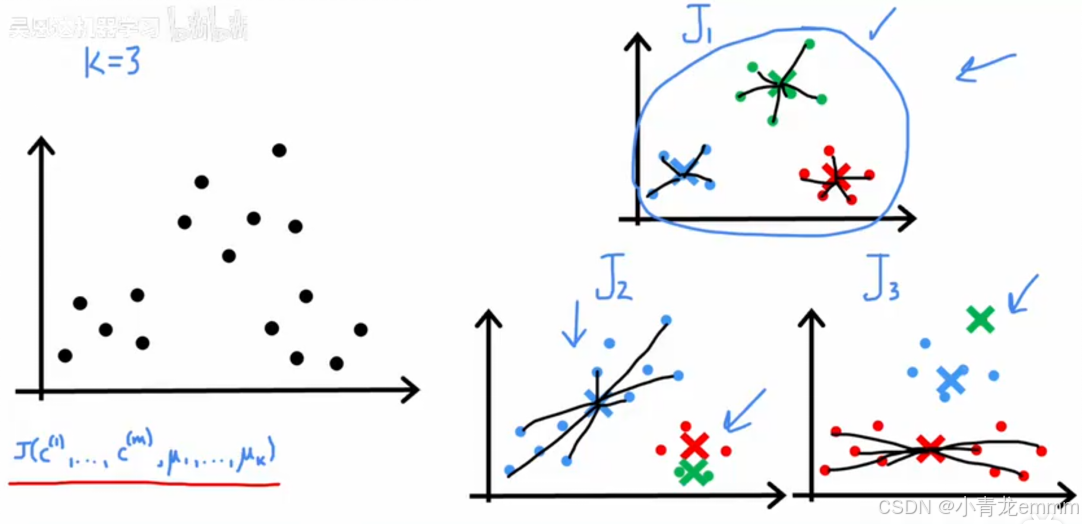
集群数量的选取:

①Elbow method:(图像法选择K)
通过绘制以集群数量K为X轴,丧失函数J为Y轴的函数图像,来找到图像的”Elbow”,即函数图像降落最显着的点,负梯度最小的部分,即为最符合的集群数量。
②盘算法:(根据实际情况而选择K)
实践中对集群数量的选择大多都是模棱两可的,可以根据实际情况以及自己盼望模子后期的体现来选择集群数量- # -*- coding: gbk -*- # 改为GBK编码声明(临时解决方案)
- # 导入必要的库
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_blobs # 用于生成演示数据集
- # 生成模拟数据
- X, y = make_blobs(
- n_samples=300, # 样本数量
- centers=4, # 聚类中心数量
- cluster_std=0.6, # 簇的标准差(控制离散程度)
- random_state=0 # 随机种子(确保结果可复现)
- )
- class KMeans:
- """K-means聚类算法实现"""
-
- def __init__(self, k=4, max_iter=1000):
- """初始化参数
- Args:
- k: 要形成的簇数(聚类中心数)
- max_iter: 最大迭代次数
- """
- self.k = k
- self.max_iter = max_iter
-
- def fit(self, X):
- """训练方法:寻找数据的最佳聚类中心
-
- Args:
- X: 输入数据矩阵,形状为(n_samples, n_features)
- """
- # 随机选择k个数据点作为初始聚类中心
- self.centers = X[np.random.choice(len(X), self.k, replace=False)]
-
- # 开始迭代优化
- for _ in range(self.max_iter):
- # 步骤1:将每个样本分配到最近的聚类中心(E步)
- labels = self._assign_clusters(X)
-
- # 步骤2:根据分配结果重新计算聚类中心(M步)
- new_centers = self._compute_centers(X, labels)
-
- # 如果聚类中心不再变化,提前终止迭代
- if np.allclose(self.centers, new_centers):
- break
-
- self.centers = new_centers # 更新聚类中心
-
- return self
-
- def _assign_clusters(self, X):
- """计算每个样本所属的最近聚类中心"""
- # 计算每个样本到所有聚类中心的欧氏距离(未开平方以提升性能)
- distances = np.sum((X[:, np.newaxis] - self.centers) ** 2, axis=2)
- # 返回最近中心的索引(即所属簇的标签)
- return np.argmin(distances, axis=1)
-
- def _compute_centers(self, X, labels):
- """根据当前分配结果重新计算聚类中心"""
- new_centers = np.zeros((self.k, X.shape[1]))
- for i in range(self.k):
- # 获取属于当前簇的所有样本
- cluster_samples = X[labels == i]
- # 计算新的聚类中心(样本均值)
- if len(cluster_samples) > 0:
- new_centers[i] = cluster_samples.mean(axis=0)
- else:
- # 如果出现空簇,保持原中心(避免除零错误)
- new_centers[i] = self.centers[i]
- return new_centers
-
- def predict(self, X):
- """预测新样本的所属簇"""
- return self._assign_clusters(X)
- # 实例化并训练模型
- model = KMeans(k=4)
- model.fit(X)
- # 获取预测结果
- labels = model.predict(X)
- # 可视化结果
- plt.figure(figsize=(8,6))
- # 绘制所有样本点,按聚类结果着色
- plt.scatter(
- X[:, 0], X[:, 1], # 使用前两个特征作为坐标
- c=labels, # 按预测标签着色
- cmap='viridis', # 颜色映射方案
- s=50, # 点的大小
- edgecolor='k' # 点边缘颜色
- )
- # 标注聚类中心
- plt.scatter(
- model.centers[:, 0], model.centers[:, 1],
- c='red', # 中心点颜色
- s=200, # 点的大小
- alpha=0.7, # 透明度
- marker='X', # 标记形状
- edgecolor='k', # 边缘颜色
- linewidth=2 # 边缘线宽
- )
- # 添加图表元素
- plt.title('K-means Clustering Result')
- plt.xlabel('Feature 1')
- plt.ylabel('Feature 2')
- plt.grid(True, linestyle='--', alpha=0.6)
- plt.show()

三,非常检测(Anomaly Detection):
非常检测,一种无需标签数据的非常检测方法。所输入的大多数数据都是正常的,若再输入非常的数据,则模子会根据非常数据和正常数据在特性空间中的分布差别来判断。
实现:
1.Density:
为特性X的概率创建模子,试图找出最佳特性值(如下图,最内里的椭圆内数据分布最为会合,概率最大,更恰当选做为特性;越往外特性X的概率越小,越不恰当成为特性)。创建模子后,加以验证集验证,设定阈值,若所猜测概率小于阈值,则判断为非常;反之则正常。
2.正态分布:
焦点头脑与Density划一。基于正态分布的假设,通过所给数据集来盘算每个特性的均值和方差,绘制正态分布曲线。设定阈值,使用3σ原则,盘算新的数据的方差和均值,来判断其是否非常。比力快速,但是无法处置惩罚复杂分布。
3.孤立丛林:
基于决定树布局的无监督非常检测。非常数据点通过决定树模子二分类后,非常数据由于在特性空间中分布希罕,可以通过更少的分割次数被孤立;还可以随机分别特性空间,通过随机选择特性和分别值构建二叉搜索树,非常值的路径长度更短。
算法的创建:
Density Estimation(密度估计):
参数方法:假设数据服从正态分布,通过估计参数的均值,方差来构建概率密度函数。
非参数方法:无需预设分布,直接从数据自己推断分布大概模式。
非常点每每位于数据分布的低概率地域。在训练阶段,使用正常数据来构建概率密度函数;盘算新样本的密度值,其值越低非常大概性越高;决定阶段设定阈值,低于阈值的样本则判断为非常。(下图是通过构建多个正态分布,使用多个正态分布的加权和拟合数据来盘算样本的加权概率密度)
但是该方法所得模子不敷稳固,易受极度值的影响而导致毛病。
非常检测体系的评估:
通过交织验证的方法来实现参数的调解。
通过正常数据(可以少量非常)举行训练模子,验证集举行调解阈值,测试集评估。如果非常数据太少,可以思量去掉测试集,只要验证集。但如许无法评估。
非常检测 VS 监督学习:
数据量巨细: 非常检测恰当只有少量数据集(如0-20正面例子),但反面例子相对较多的情况;监督学习恰当数据集量富足大,正面例子和反面例子都富足。
种类多少: 非常检测恰当数据集种类多的,未知的非常情况;而监督学习恰当已知非常的种类,种类较少的。(即非常检测是通过正常的训练集来判断非常,不正常的数据就算非常;而监督学习则是让模子知道非常数据长什么样,才气判断非常,以是监督学习非常的数据要多些)
举个例子:
非常检测 VS 监督学习在诈骗检测体系中的应用:
非常检测是信托天上掉馅饼是小概率变乱,以是判断为诈骗;而监督学习则是见过诈骗的案例,来判断其为诈骗,若没见过,则难以判断。
非常检测特性的选取:
通过特性工程,并实时天生特性的正态分布曲线,通过其是否为尺度正太分布来实时调解特性。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。 |







 发表于 2025-10-15 00:54:34
发表于 2025-10-15 00:54:34