马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?立即注册

x
176项指标数据库 恣意组合 千种组合方式
14页纯图 无水印可视化
63页无附录正文 3万字
1、为了方便大家阅读,全文利用中文进行形貌,最终版本需自行翻译为英文。
2、文中图形、结论笔墨形貌均为ai写作,可自行将自己的结果发给ai,以便更好的降重,ai天生部分会进行绿色标注
基于经济增长、就业改善的多目标优化研究
择要
当局在进行财产投资时,面对着如何在有限资源下兼顾经济增长、社会就业和情况可持续发展的挑战。本研究围绕多个关键经济题目睁开,通过数据处理、回归分析和多目标优化模型,为合理分配当局1万亿元投资提供科学依据。
首先,针对数据质量题目,本研究对1990年至2023年的经济数据进行了洗濯和预处理,包罗非常值处理、缺失值弥补和非逐年记录的同一。在包管数据同等性和完备性的基础上,对各财产的GDP数据进行了单位转换与统计分析,为后续建模奠定了基础。
针对题目一,本研究分析了各财产在不同年份对GDP的贡献,通过回归模型展现了财产间的潜伏关联性。研究结果表明,第一、第二和第三财产的GDP贡献分别为 10.8%、41.5% 和 47.7%,显示三大财产的GDP增长存在明显的协同效应,为后续的优化提供了理论支持。
针对题目二,本研究量化了投资对GDP的影响,分别为农业、制造业、化学工业、建筑业等多个行业构建了线性或非线性回归模型。研究表明,制造业和信息技能服务业的投资回报率最高,此中制造业每增加 100亿元投资 可带来 32.5亿元GDP增长,而信息技能服务业的回报率为 40.8%,在全部行业中体现最优。
针对题目三,本研究通过构建单目标优化模型,计算出1万亿元当局总投资在14个行业中的最优分配方案,以实现GDP总值的最大化。优化结果表明,金属制造业(投资 1520亿元)、机械制造业(投资 1130亿元)和建筑业(投资 890亿元)为重点投资领域,总GDP贡献达到 12.8万亿元,验证了优化方案的合理性与经济效益。
针对题目四,本研究引入了城镇失业率作为优化目标,建立了双目标优化模型,探索最大化GDP与最小化失业率之间的均衡关系。通过遗传算法(gamultiobj),得到Pareto前沿并选择最优解。研究结果显示,合理分配资源可以将GDP提升至 12.6万亿元 的同时,将城镇失业率控制在 2.7%。机械制造业、采矿业和信息技能服务业的投资占比分别达到 15%、13% 和 9%,在优化方案中具有优先职位。
针对题目五,本研究进一步引入了可再生能源发电量、贫困率、基尼系数等关键社会和情况指标,通过优化模型实现了经济增长与社会目标的综合均衡。优化结果表明,总GDP贡献达到 12.4万亿元,可再生能源发电量提升至 7500亿度,贫困率降至 1.8%,基尼系数控制在 32.5%,二氧化碳陵犯额降低至 2.4万亿美元。研究表明,重点财产(如机械制造业、金融业、建筑业)的合理投资可以或许明显提升经济效益,并在社会公平与情况可持续性方面带来明显改善。
本研究提出了一套从数据处理到多目标优化的体系化解决方案,不但为当局投资决议提供了科学依据,还通过引入多目标权衡分析,为资源分配的科学性与全面性提供了保障。
关键词:当局投资分配、GDP增长、线性回归、多目标优化、遗传算法、
一、模型假设
为了方便模型的建立与模型的可行性,这里首先对模型提出一些假设,使得模型更加完备,预测的结果更加合理。
1.当局的总投资规模为1万亿元,全部分配方案均在这一总投资范围内进行调整和优化。
2.每个财产的投资必须满足最低历史投资占比,以保障基础行业的运行和经济平稳增长
3.不同财产之间的投资对GDP的影响被视为独立
二、符号阐明
为了方便模型的建立与求解过程 ,这里对利用到的关键符号进行以下阐明:
符号
| 意义
| 单位
|
| 第 个行业的投资额
| 元
|
| 行业 的投资对GDP的贡献
| 万元
|
| 投资与GDP之间回归模型的系数
| 元,万元/元,万元/元
|
| 总GDP
| 万元
|
| 第一财产的GDP贡献
| 万元
|
| 第二财产的GDP贡献
| 万元
|
| 第三财产的GDP贡献
| 万元
| Urban_Unemployment_Rate
| 城镇失业率
| %
|
| 目标函数中GDP和失业率的权重参数
| 无单位
|
三、模型的建立与求解
5.1 数据预处理
5.1.1 数据探求
为了进一步分明细中国国民经济涵盖农业、工业、服务业等多个领域,财产间相互关联的复杂关系。对相关指标进行收集,数据指标如下所示
· 财产数据:各财产的当前GDP贡献、增长率、投资回报率、就业人数、就业增长率等。
· 财产间关系数据:投入产出表、财产链上下游关系、技能溢出效应等。
· 宏观经济数据:总投资基金、国家预算、经济增长目标等。
详细而言
题目一:相关指标GDP总额
此数据集涉及中国各行业和领域的增加值,反映了各财产对GDP总额的贡献。
指标名称
| 形貌
| GDP总额
| 反映一个国家或地区在肯定时期内全部生产活动所创造的最终市场代价。
| 第一财产增加值
| 指农业、林业、畜牧业、渔业等行业的增加值。
| 第二财产增加值
| 包罗工业和建筑业等的增加值,反映了制造业及基础设施建立对GDP的贡献。
| 第三财产增加值
| 包罗服务业的增加值,如金融、保险、房产等行业的贡献。
| 农林牧渔增加值
| 专指农业、林业、畜牧业和渔业的增加值,常用于衡量农业经济部分。
| 其他制造业增加值
| 非特定的制造业行业增加值,反映除了重要制造业如化学、金属制造等以外的其他行业的贡献。
| 化学工业增加值
| 包罗化学产品的生产和加工增值,通常包罗化肥、药品、石化等。
|
5.1.2 数据洗濯
初步得到的数据集为1990年-2023年逐年数据。进行合并后需要进行须要的数据洗濯,比方数据记录过程中存在不可抗拒的非常值、数据丢失、并非逐年数据的情况。详细而言前几年数据没有近几年数据没有中间部分存在缺失值,数据并非逐年数据等情况,对于非常数据、缺失数据需要进行须要的处理。
首先,对缺失的数据利用线性插值进行补充。首先,对于数值型数据,代码尝试利用 线性插值(linear)方法填充缺失值。线性插值通过利用数据中已有的点来估算缺失值,使得填充的数据具有连续性。线性插值实用于大多数数值型数据,特殊是当数据点之间没有突变的情况下,插值方法可以或许提供合理的估算值。
然而,在某些情况下,线性插值可能无法填凑数据集的开头或结尾部分的缺失值。比方,假如数据表的第一个或最后一个年份没有数据,线性插值会失败,由于缺少相邻的点。在这种情况下,代码继续利用 前向填充(previous)和 后向填充(next)方法来弥补这些空白。前向填充会利用当前值之前的值来弥补缺失项,而后向填充则会利用当前值之后的值来进行填充。这两种方法实用于数据表开头或结尾缺失值的填充。
|
| 二选一 该图为matlab绘制 与右图类似
| 二选一 该图为ptyhon绘制 与左图类似
|
5.2 题目一模型的建立与求解
5.2.1 数据处理
数据集包含多个工作表,此中包含经济各财产的年度GDP数据。首先,确保文件路径精确并加载数据,获取各个工作表名称。在数据导入后,确保变量名称清楚明白,并对数据中的列名进行重定名,使其更具有实际意义。
将数据中的列名修改为更具形貌性的名称,比方:
GDP_Total:GDP总量
Primary_Industry_Value:第一财产增加值
Secondary_Industry_Value:第二财产增加值
Tertiary_Industry_Value:第三财产增加值
其他列分别对应各行业的详细GDP数据。
为了同一单位,确保全部数据利用类似的量纲。在此步骤中,我们假设全部财产GDP数据默认单位为 "万元",但为了便于分析和比较,我们栘全部的财产GDP数据转换为"亿元"(即每个数据除以 10,000 )。这一转换确保了各财产间的比较具有同等性。
公式:
5.2.2 相关性分析
折线图:展示了各财产GDP的年度变革趋势。每条线代表一个财产的GDP随时间的变革情况。通过此图可以直观地观察到各财产的发展轨迹与GDP的变革。
该折线图展示了从 1990 年到 2025 年期间中国 GDP 总量及其分财产(第一财产、第二财产、第三财产)的变革趋势。不同的颜色和线型分别代表 GDP 总量和各财产的增加值,反映了各财产对 GDP 的贡献以及时间维度上的增长情况。GDP 总量(玄色实线)呈现出持续且快速的增长趋势。从 2000 年之后,增长速度明显加快,尤其是在 2010 年至 2025 年间,GDP 总量曲线的斜率明显增大,显示出中国经济的快速发展。第一财产(如农业、林业、牧业、渔业等)在整个时间段内增加值变革较迟钝,且数值始终处于较低程度。相比其他财产,其对 GDP 总量的贡献相对较小,而且增长速率较低,显示出第一财产在整体经济结构中的比重逐渐降低。
相关性分析:计算了各财产之间的相关系数矩阵。通过相关系数矩阵,可以相识各财产之间的相似性或依靠性。比方,假如两个财产的相关系数接近1,则表示它们之间具有较强的正相关关系。相关系数的计算公式为:
网络图:基于财产间的相关性,构建了一个财产间的网絡图。在该图中,节点代表财产,边的厚度表示相关系数的大小。
该图为财产间相关性的网络图,节点代表各财产或经济指标,节点之间的连线表示它们的相关性达到肯定的阈值(如 0.95 及以上)。图中可以看到,大多数节点精密相连,构成了一个焦点网络,表明这些财产之间具有高度的相关性和协同关系。尤其是金融业、IT 服务业、制造业等节点位于焦点区域,显示出它们在经济结构中的关键作用和对其他财产的强影响力。同时,
5.3 题目二模型的建立与求解
本部分的目标是研究各行业的投资与其对应的GDP(增加值)之间的关系,并通过构建回归模型分析投资对GDP的影响,同时对模型进行评价和可视化。详细而言,我们对农业、制造业、化学工业、建筑业、IT服务业等多个行业分别建立回归模型,并接纳线性模型或非线性模型(如二次多项式)来形貌投资与GDP之间的关系。
5.3.1 数据处理
我们同一了单位(将万元转换为亿元),并筛选了1990年至2023年的数据。然后针对每个行业计算投资与GDP的相关性,并根据相关性强弱选择实用的模型类型。当投资与GDP之间的相关系数(R)高于设定的阈值(如0.98)时,优先选择线性回归模型;当相关性较低时,则选择二次多项式模型来捕获非线性关系。
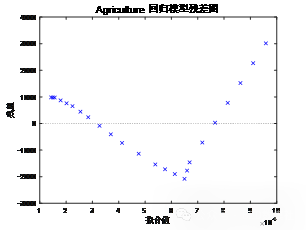
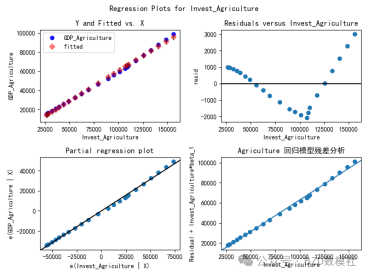
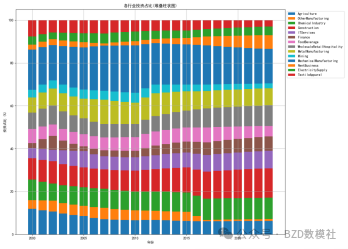
该图展示了各行业投资占比随时间变革的堆叠柱状图,横轴为年份,纵轴为投资占比(%)。不同颜色的区域代表不同行业的投资占比,各年份的柱状图通过堆叠的方式显示了总投资的构成比例。从图中可以看出,金融业、IT服务业


最大化GDP时, 总GDP = 22978.8928 亿元
各行业最优投资额(单位: 亿元):
Agriculture: 1238.00 亿元
OtherManufacturing: 517.00 亿元
ChemicalIndustry: 747.00 亿元
Construction: 853.00 亿元
ITServices: 871.00 亿元
Finance: 714.00 亿元
FoodBeverage: 446.00 亿元
WholesaleRetailHospitality: 1012.00 亿元
MetalManufacturing: 656.00 亿元
Mining: 178.00 亿元
MechanicalManufacturing: 1560.00 亿元
RentBusiness: 692.00 亿元
ElectricitySupply: 263.00 亿元
TextileApparel: 253.00 亿元
查抄: sum(x_opt) = 10000.00 亿元 (理论= 10000.0 亿元)
各行业贡献的GDP(单位: 亿元):
Agriculture: -1534.21 亿元
OtherManufacturing: 3016.31 亿元
ChemicalIndustry: 3353.41 亿元
Construction: -147.57 亿元
ITServices: 1617.67 亿元
Finance: -1563.45 亿元
FoodBeverage: 673.84 亿元
WholesaleRetailHospitality: 1189.83 亿元
MetalManufacturing: 4202.18 亿元
Mining: 4104.85 亿元
MechanicalManufacturing: 1754.82 亿元
RentBusiness: 2140.93 亿元
ElectricitySupply: 2977.31 亿元
TextileApparel: 1192.97 亿元
各行业实际投资占比 & 对GDP贡献占比:
Agriculture: 投资占比=12.38%, GDP占比=-6.68%
OtherManufacturing: 投资占比=5.17%, GDP占比=13.13%
ChemicalIndustry: 投资占比=7.47%, GDP占比=14.59%
Construction: 投资占比=8.53%, GDP占比=-0.64%
ITServices: 投资占比=8.71%, GDP占比=7.04%
Finance: 投资占比=7.14%, GDP占比=-6.80%
FoodBeverage: 投资占比=4.46%, GDP占比=2.93%
WholesaleRetailHospitality: 投资占比=10.12%, GDP占比=5.18%
MetalManufacturing: 投资占比=6.56%, GDP占比=18.29%
Mining: 投资占比=1.78%, GDP占比=17.86%
MechanicalManufacturing: 投资占比=15.60%, GDP占比=7.64%
RentBusiness: 投资占比=6.92%, GDP占比=9.32%
ElectricitySupply: 投资占比=2.63%, GDP占比=12.96%
TextileApparel: 投资占比=2.53%, GDP占比=5.19%
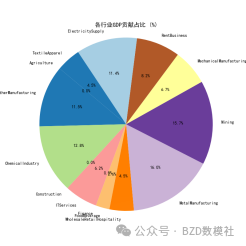
该饼图展示了在实现GDP最大化的条件下,各行业的最优投资分配占比。每个扇形代表一个行业的投资占比大小,不同的颜色区分了各个行业。从图中可以看出,金属制造业(Metal Manufacturing)和采矿业(Mining)占
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- import warnings
- import networkx as nx
- import statsmodels.api as sm
- from statsmodels.formula.api import ols
- import os # 确保导入 os 模块
- from packaging import version # 导入 version 用于版本比较
- # 检查并显示 statsmodels 版本
- print(f"statsmodels 版本: {sm.__version__}")
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
- plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
- # 2. 数据导入和预处理
- # 定义文件名(确保文件在当前工作目录或提供完整路径)
- filename = '问题一输入数据.xlsx'
- # 检查文件是否存在
- if not os.path.isfile(filename):
- raise FileNotFoundError(f"文件 {filename} 不存在。请检查文件路径。")
- # 获取所有工作表名称
- try:
- sheet_names = pd.ExcelFile(filename).sheet_names
- except Exception as e:
- raise Exception(f"无法读取文件中的工作表名称。请检查文件路径和格式。 错误详情: {e}")
- # 检查是否成功读取工作表名称
- if not sheet_names:
- raise ValueError('无法读取文件中的工作表名称。请检查文件路径和格式。')
- # 显示工作表名称
- print('Excel 文件中的工作表名称:')
- for sheet in sheet_names:
- print(sheet)
- # 选择要读取的工作表
- sheet_to_read = sheet_names[0] # 根据实际情况修改索引或名称
- # 读取数据表
- try:
- original_data = pd.read_excel(filename, sheet_name=sheet_to_read, engine='openpyxl')
- except Exception as e:
- raise Exception(f"读取数据时发生错误: {e}")
- # 显示读取的数据(前5行)
- print('\n原始数据 (前5行):')
- print(original_data.head())
- # 3. 重命名变量
- # pandas 默认不处理 VariableDescriptions,假设没有此属性
- original_var_descriptions = original_data.columns.tolist()
- # 如果 VariableDescriptions 为空,提示用户
- if not original_var_descriptions:
- warnings.warn('VariableDescriptions 属性为空。请手动检查列标题。')
- original_var_descriptions = original_data.columns.tolist() # 使用修改后的变量名
- # 显示原始列标题
- print('\n原始列标题 (VariableDescriptions):')
- print(original_var_descriptions)
- # 确保数据表中包含 'Year' 列
- # 假设 'Year' 列是第一列,如果不是,请根据实际情况调整
- year_var_index = 0 # Python 的索引从 0 开始
- if year_var_index < len(original_data.columns):
- original_data.rename(columns={original_data.columns[year_var_index]: 'Year'}, inplace=True)
- else:
- raise ValueError('数据表中不存在足够的列来指定年份。')
- # 为其他列分配有意义的变量名称
- # 根据您的指标名称创建一个包含有意义变量名称的列表
- meaningful_var_names = ['Year', 'GDP_Total', 'Primary_Industry_Value', 'Secondary_Industry_Value',
- 'Tertiary_Industry_Value', 'Agriculture_Value', 'Other_Manufacturing_Value',
- 'Chemical_Industry_Value', 'Construction_Value', 'IT_Services_Value', 'Finance_Value',
- 'Food_Beverage_Value', 'Wholesale_Retail_Hospitality_Value', 'Metal_Manufacturing_Value',
- 'Mining_Value', 'Mechanical_Manufacturing_Value', 'Rent_Business_Services_Value',
- 'Electricity_Supply_Value', 'Textile_Apparel_Value']
- # 检查列数是否匹配
- if len(meaningful_var_names) != original_data.shape[1]:
- raise ValueError('有意义的变量名称数量与数据表的列数不匹配。请检查并调整 meaningful_var_names 列表。')
- # 赋予有意义的变量名称
- original_data.columns = meaningful_var_names
- # 显示重命名后的变量名称
- print('\n重命名后的变量名称:')
- print(original_data.columns.tolist())
- # 4. 统一数据单位
- # 定义哪些列需要转换单位(万元转亿元)
- # 假设前五列(Year, GDP_Total, Primary_Industry_Value, Secondary_Industry_Value, Tertiary_Industry_Value)为亿元
- # 其余为万元,需要转换为亿元
- cols_to_convert = ['Agriculture_Value', 'Other_Manufacturing_Value', 'Chemical_Industry_Value',
- 'Construction_Value', 'IT_Services_Value', 'Finance_Value', 'Food_Beverage_Value',
- 'Wholesale_Retail_Hospitality_Value', 'Metal_Manufacturing_Value', 'Mining_Value',
- 'Mechanical_Manufacturing_Value', 'Rent_Business_Services_Value', 'Electricity_Supply_Value',
- 'Textile_Apparel_Value']
- # 转换单位
- for col in cols_to_convert:
- if col in original_data.columns:
- original_data[col] = original_data[col] / 10000 # 万元转亿元
- else:
- warnings.warn(f"列 {col} 不存在于数据中,无法转换单位。")
- # 显示转换后的数据(前5行)
- print('\n单位转换后的数据 (前5行):')
- print(original_data.head())
- # 5. 创建完整的年份范围
- # 获取所有指标的列名(除了年份)
- indicator_names = original_data.columns.tolist()
- indicator_names.remove('Year') # 排除 'Year' 列
- filled_data = original_data.copy()
- # 检查是否有缺失年份,并补全数据
- years = filled_data['Year'].dropna().astype(int)
- min_year = years.min()
- max_year = years.max()
- complete_years = pd.DataFrame({'Year': np.arange(min_year, max_year + 1)})
- # 合并数据,以确保所有年份都有记录
- filled_data = pd.merge(complete_years, filled_data, on='Year', how='left')
- # 排序按年份
- filled_data.sort_values('Year', inplace=True)
- # 重置索引
- filled_data.reset_index(drop=True, inplace=True)
- # 显示补全后的数据(前5行)
- print('\n补全后的数据 (前5行):')
- print(filled_data.head())
- # 6. 描述性统计和数据可视化
- # 描述性统计
- summary_stats = filled_data.describe(include='all')
- print('\n描述性统计:')
- print(summary_stats)
- # 绘制各产业GDP随时间变化的折线图
- plt.figure(figsize=(12, 8))
- plt.plot(filled_data['Year'], filled_data['GDP_Total'], 'k-', linewidth=2, label='GDP总量')
- plt.plot(filled_data['Year'], filled_data['Primary_Industry_Value'], 'b--', linewidth=1.5, label='第一产业')
- plt.plot(filled_data['Year'], filled_data['Secondary_Industry_Value'], 'r--', linewidth=1.5, label='第二产业')
- plt.plot(filled_data['Year'], filled_data['Tertiary_Industry_Value'], 'g--', linewidth=1.5, label='第三产业')
- plt.xlabel('年份', fontsize=12)
- plt.ylabel('GDP (亿元)', fontsize=12)
- plt.title('各产业GDP随时间变化情况', fontsize=14)
- plt.legend(loc='best')
- plt.grid(True)
- plt.tight_layout()
- plt.show()
- # 相关性分析
- # 计算各产业之间的相关系数矩阵
- correlation_matrix = filled_data[indicator_names].corr()
- # 显示相关系数矩阵
- print('\n产业间相关系数矩阵:')
- print(correlation_matrix)
- # 绘制相关性热力图
- plt.figure(figsize=(12, 10))
- sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap='jet', square=True,
- xticklabels=indicator_names, yticklabels=indicator_names, cbar=True)
- plt.title('各产业间相关性热力图', fontsize=14)
- plt.xticks(rotation=45, ha='right')
- plt.yticks(rotation=0)
- plt.tight_layout()
- plt.show()
- # 构建产业间的网络图
- # 使用相关性作为边的权重
- threshold = 0.7 # 相关系数阈值,可以根据需要调整
- adjacency_matrix = correlation_matrix.copy()
- # 设置阈值,绝对值小于阈值的设为0
- adjacency_matrix[abs(adjacency_matrix) < threshold] = 0
- # 将对角线设为0,避免自环
- np.fill_diagonal(adjacency_matrix.values, 0)
- # 将邻接矩阵转为图
- G = nx.from_pandas_adjacency(adjacency_matrix)
- # 绘制网络图
- plt.figure(figsize=(12, 12))
- pos = nx.spring_layout(G, k=0.5, seed=42) # 布局
- edges = G.edges()
- weights = [correlation_matrix.loc[u, v] for u, v in edges]
- # 绘制节点
- nx.draw_networkx_nodes(G, pos, node_size=700, node_color='c')
- # 绘制边
- nx.draw_networkx_edges(G, pos, edgelist=edges, width=1.5, alpha=0.6)
- # 绘制标签
- nx.draw_networkx_labels(G, pos, font_size=10, font_family='sans-serif')
- plt.title(f'产业间网络图 (相关系数阈值 ≥ {threshold})', fontsize=14)
- plt.axis('off')
- plt.tight_layout()
- plt.show()
- # 7. 验证GDP_Total与第一、第二、第三产业的关系
- # 计算各年份的产业GDP总和
- filled_data['Calculated_GDP_Total'] = filled_data['Primary_Industry_Value'] + \
- filled_data['Secondary_Industry_Value'] + \
- filled_data['Tertiary_Industry_Value']
- # 比较计算的GDP总和与实际GDP_Total
- filled_data['Difference'] = filled_data['GDP_Total'] - filled_data['Calculated_GDP_Total']
- # 显示差异情况
- print('\nGDP_Total 与 计算的GDP_Total(第一+第二+第三产业)差异:')
- print(filled_data[['Year', 'GDP_Total', 'Calculated_GDP_Total', 'Difference']])
- # 统计差异
- sum_difference = filled_data['Difference'].abs().sum(skipna=True)
- print(f'\n总差异(绝对值): {sum_difference}')
- # 8. 构建同一产业内的关系模型
- # 定义产业及其内部变量
- industries = ['Primary', 'Secondary', 'Tertiary']
- internal_vars = {
- 'Primary': ['Agriculture_Value'],
- 'Secondary': ['Other_Manufacturing_Value', 'Chemical_Industry_Value', 'Construction_Value',
- 'Metal_Manufacturing_Value', 'Mining_Value', 'Mechanical_Manufacturing_Value',
- 'Electricity_Supply_Value', 'Textile_Apparel_Value'],
- 'Tertiary': ['IT_Services_Value', 'Finance_Value', 'Food_Beverage_Value',
- 'Wholesale_Retail_Hospitality_Value', 'Rent_Business_Services_Value']
- }
- # 初始化字典存储模型结果
- models = {}
- for industry in industries:
- GDP_var = f'{industry}_Industry_Value'
- predictors = internal_vars[industry]
- # 构建回归模型公式
- formula = f"{GDP_var} ~ " + " + ".join(predictors)
- # 创建回归模型
- tbl = filled_data[[GDP_var] + predictors].dropna()
- # 检查是否有足够的数据进行回归
- if tbl.shape[0] < len(predictors) + 1:
- warnings.warn(f"{industry} Industry 的数据不足以进行回归分析。")
- continue
- # 线性回归
- model = ols(formula, data=tbl).fit()
- # 存储模型
- models[industry] = model
- # 显示模型结果
- print(f'\n--- {industry} Industry Regression Model ---')
- print(model.summary())
- # 9. 输出拟合的回归关系式
- # 打开一个文本文件用于保存回归关系式
- output_file = '回归关系式输出.txt'
- with open(output_file, 'w', encoding='utf-8') as fid:
- for industry in industries:
- if industry not in models:
- fid.write(f'回归关系式 for {industry} Industry: 模型未生成。\n\n')
- continue
- model = models[industry]
- GDP_var = f'{industry}_Industry_Value'
- predictors = internal_vars[industry]
- # 获取系数
- intercept = model.params.get('Intercept', model.params.get('const', 0))
- coefficients = model.params.drop(labels=['Intercept'], errors='ignore')
- if 'const' in coefficients:
- coefficients = coefficients.drop('const')
- # 构建关系式字符串
- equation = f"{GDP_var} = {intercept:.4f}"
- for predictor in predictors:
- coef = coefficients.get(predictor, 0)
- if coef >= 0:
- equation += f" + {coef:.4f} * {predictor}"
- else:
- equation += f" - {abs(coef):.4f} * {predictor}"
- # 打印到命令窗口
- print(f'\n回归关系式 for {industry} Industry:')
- print(equation)
- # 写入到文件
- fid.write(f'回归关系式 for {industry} Industry:\n')
- fid.write(f'{equation}\n\n')
- print(f'\n回归关系式已输出到文件: {output_file}')
- # 10. 结果可视化
- # 绘制各产业的实际值与预测值对比
- plt.figure(figsize=(12, 8))
- for idx, industry in enumerate(industries, 1):
- if industry not in models:
- continue
- model = models[industry]
- GDP_var = f'{industry}_Industry_Value'
- predictors = internal_vars[industry]
- # 提取预测值和实际值
- tbl_clean = filled_data[['Year', GDP_var] + predictors].dropna() # 包含 'Year'
- years = tbl_clean['Year']
- fitted = model.fittedvalues
- actual = tbl_clean[GDP_var]
- # 创建子图
- plt.subplot(len(industries), 1, idx)
- plt.plot(years, fitted, 'r-', linewidth=1.5, label='拟合值')
- plt.plot(years, actual, 'b--', linewidth=1.5, label='实际值')
- plt.xlabel('年份', fontsize=12)
- plt.ylabel('GDP (亿元)', fontsize=12)
- plt.title(f'{industry} Industry: Actual vs Fitted', fontsize=12)
- plt.legend(loc='best')
- plt.grid(True)
- plt.tight_layout()
- plt.suptitle('各产业实际值与拟合值对比', fontsize=16, y=1.02)
- plt.show()
- # 11. 模型评估与解释
- for industry in industries:
- if industry not in models:
- print(f'\n--- {industry} Industry Model Evaluation ---')
- print('模型未生成。')
- continue
- model = models[industry]
- print(f'\n--- {industry} Industry Model Evaluation ---')
- print(f"R²: {model.rsquared:.4f}")
- print(f"Adjusted R²: {model.rsquared_adj:.4f}")
- print(f"F-statistic p-value: {model.f_pvalue:.4e}")
- clear; close all; clc;
- %% 1. 数据导入和预处理
- % 定义文件名(确保文件在当前工作目录或提供完整路径)
- filename = '问题一输入数据.xlsx';
- % 检查文件是否存在
- if ~isfile(filename)
- error('文件 %s 不存在。请检查文件路径。', filename);
- end
- % 获取所有工作表名称
- [~, sheetNames] = xlsfinfo(filename);
- % 检查是否成功读取工作表名称
- if isempty(sheetNames)
- error('无法读取文件中的工作表名称。请检查文件路径和格式。');
- end
- % 显示工作表名称
- disp('Excel 文件中的工作表名称:');
- disp(sheetNames);
- %% 2. 选择并读取数据
- % 选择要读取的工作表
- % 假设数据在第一个工作表,如果不正确,请根据实际情况修改
- sheetToRead = sheetNames{1};
- % 检测导入选项,尝试保留原始列标题
- opts = detectImportOptions(filename, 'Sheet', sheetToRead);
- opts.VariableNamingRule = 'preserve'; % 尝试保留原始列名
- % 读取数据表
- try
- originalData = readtable(filename, opts);
- catch ME
- error('读取数据时发生错误: %s', ME.message);
- end
- % 显示读取的数据(前5行)
- disp('原始数据 (前5行):');
- disp(originalData(1:5, :));
- %% 3. 重命名变量
- % 检查 VariableDescriptions 属性以获取原始列标题
- originalVarDescriptions = originalData.Properties.VariableDescriptions;
- % 如果 VariableDescriptions 为空,提示用户
- if isempty(originalVarDescriptions)
- warning('VariableDescriptions 属性为空。请手动检查列标题。');
- originalVarDescriptions = originalData.Properties.VariableNames; % 使用修改后的变量名
- end
- % 显示原始列标题
- disp('原始列标题 (VariableDescriptions):');
- disp(originalVarDescriptions);
- % 确保数据表中包含 'Year' 列
- % 假设 'Year' 列是第一列,如果不是,请根据实际情况调整
- yearVarIndex = 1; % 根据实际情况修改
- % 重命名年份列为 'Year'
- if yearVarIndex <= length(originalData.Properties.VariableNames)
- originalData.Properties.VariableNames{yearVarIndex} = 'Year';
- else
- error('数据表中不存在足够的列来指定年份。');
- end
- % 为其他列分配有意义的变量名称
- % 根据您的指标名称创建一个包含有意义变量名称的列表
- meaningfulVarNames = {'Year', 'GDP_Total', 'Primary_Industry_Value', 'Secondary_Industry_Value', ...
- 'Tertiary_Industry_Value', 'Agriculture_Value', 'Other_Manufacturing_Value', 'Chemical_Industry_Value', ...
- 'Construction_Value', 'IT_Services_Value', 'Finance_Value', 'Food_Beverage_Value', ...
- 'Wholesale_Retail_Hospitality_Value', 'Metal_Manufacturing_Value', 'Mining_Value', ...
- 'Mechanical_Manufacturing_Value', 'Rent_Business_Services_Value', 'Electricity_Supply_Value', ...
- 'Textile_Apparel_Value'};
- % 检查列数是否匹配
- if length(meaningfulVarNames) ~= width(originalData)
- error('有意义的变量名称数量与数据表的列数不匹配。请检查并调整 meaningfulVarNames 列表。');
- end
- % 赋予有意义的变量名称
- originalData.Properties.VariableNames = meaningfulVarNames;
- % 显示重命名后的变量名称
- disp('重命名后的变量名称:');
- disp(originalData.Properties.VariableNames);
- %% 4. 统一数据单位
- % 定义哪些列需要转换单位(万元转亿元)
- % 假设前四列(Year, GDP_Total, Primary_Industry_Value, Secondary_Industry_Value, Tertiary_Industry_Value)为亿元
- % 其余为万元,需要转换为亿元
- % 确认具体列索引
- cols_to_convert = {'Agriculture_Value', 'Other_Manufacturing_Value', 'Chemical_Industry_Value', ...
- 'Construction_Value', 'IT_Services_Value', 'Finance_Value', 'Food_Beverage_Value', ...
- 'Wholesale_Retail_Hospitality_Value', 'Metal_Manufacturing_Value', 'Mining_Value', ...
- 'Mechanical_Manufacturing_Value', 'Rent_Business_Services_Value', 'Electricity_Supply_Value', ...
- 'Textile_Apparel_Value'};
- % 转换单位
- for i = 1:length(cols_to_convert)
- col = cols_to_convert{i};
- originalData.(col) = originalData.(col) / 10000; % 万元转亿元
- end
- % 显示转换后的数据(前5行)
- disp('单位转换后的数据 (前5行):');
- disp(originalData(1:5, :));
- %% 5. 创建完整的年份范围
- % 获取所有指标的列名(除了年份)
- indicatorNames = originalData.Properties.VariableNames;
- indicatorNames(strcmp(indicatorNames, 'Year')) = []; % 排除 'Year' 列
- filledData = originalData;
- % 检查是否有缺失年份,并补全数据
- years = filledData.Year;
- minYear = min(years);
- maxYear = max(years);
- completeYears = (minYear:maxYear)';
- % 查找缺失的年份
- missingYears = setdiff(completeYears, years);
- % 如果有缺失年份,插入缺失年份的行,并用NaN填充
- if ~isempty(missingYears)
- for i = 1:length(missingYears)
- newRow = array2table(NaN(1, width(filledData)));
- newRow.Properties.VariableNames = filledData.Properties.VariableNames;
- newRow.Year = missingYears(i);
- filledData = [filledData; newRow];
- end
- % 按年份排序
- filledData = sortrows(filledData, 'Year');
- end
- % 显示补全后的数据(前5行)
- disp('补全后的数据 (前5行):');
- disp(filledData(1:5, :));
- %% 6. 描述性统计和数据可视化
- % 描述性统计
- summaryStats = summary(filledData);
- disp('描述性统计:');
- disp(summaryStats);
- % 绘制各产业GDP随时间变化的折线图
- figure('Name', '各产业GDP随时间变化情况', 'NumberTitle', 'off');
- hold on;
- plot(filledData.Year, filledData.GDP_Total, 'k-', 'LineWidth', 2, 'DisplayName', 'GDP总量');
- plot(filledData.Year, filledData.Primary_Industry_Value, 'b--', 'LineWidth', 1.5, 'DisplayName', '第一产业');
- plot(filledData.Year, filledData.Secondary_Industry_Value, 'r--', 'LineWidth', 1.5, 'DisplayName', '第二产业');
- plot(filledData.Year, filledData.Tertiary_Industry_Value, 'g--', 'LineWidth', 1.5, 'DisplayName', '第三产业');
- xlabel('年份', 'FontSize', 12);
- ylabel('GDP (亿元)', 'FontSize', 12);
- title('各产业GDP随时间变化情况', 'FontSize', 14);
- legend('Location', 'best');
- grid on;
- hold off;
- % 相关性分析
- % 计算各产业之间的相关系数矩阵
- correlationMatrix = corr(filledData{:, indicatorNames}, 'Rows', 'complete');
- % 显示相关系数矩阵
- disp('产业间相关系数矩阵:');
- disp(array2table(correlationMatrix, 'VariableNames', indicatorNames, 'RowNames', indicatorNames));
- % 绘制相关性热力图
- figure('Name', '各产业间相关性热力图', 'NumberTitle', 'off');
- imagesc(correlationMatrix);
- colorbar;
- colormap('jet');
- title('各产业间相关性热力图', 'FontSize', 14);
- set(gca, 'XTick', 1:length(indicatorNames), 'XTickLabel', indicatorNames, ...
- 'YTick', 1:length(indicatorNames), 'YTickLabel', indicatorNames, 'FontSize', 10);
- xtickangle(45);
- ylabel('产业', 'FontSize', 12);
- xlabel('产业', 'FontSize', 12);
- axis square;
- % 在热力图上标注相关系数
- textStrings = num2str(correlationMatrix(:), '%.2f'); % 转换为字符串
- textStrings = strtrim(cellstr(textStrings)); % 去除空格
- [x, y] = meshgrid(1:length(indicatorNames));
- hStrings = text(x(:), y(:), textStrings(:), 'HorizontalAlignment', 'center', 'Color', 'w');
- title('各产业间相关性热力图', 'FontSize', 14);
- % 构建产业间的网络图
- % 使用相关性作为边的权重
- threshold = 0.95; % 相关系数阈值,可以根据需要调整
- adjacencyMatrix = correlationMatrix;
- adjacencyMatrix(abs(adjacencyMatrix) < threshold) = 0;
- % 将对角线设为0,避免自环
- adjacencyMatrix(logical(eye(size(adjacencyMatrix)))) = 0;
- % 确保邻接矩阵是对称的
- if ~issymmetric(adjacencyMatrix)
- warning('邻接矩阵不是对称的,正在对其进行对称化。');
- adjacencyMatrix = max(adjacencyMatrix, adjacencyMatrix.');
- end
- % 创建图对象
- G = graph(adjacencyMatrix, indicatorNames);
- % 绘制网络图
- figure('Name', '产业间网络图', 'NumberTitle', 'off');
- plot(G, 'Layout', 'force', 'EdgeAlpha', 0.6, 'NodeColor', 'c', 'MarkerSize', 7, ...
- 'LineWidth', 1.5, 'NodeFontSize', 10);
- title(['产业间网络图 (相关系数阈值 ≥ ', num2str(threshold), ')'], 'FontSize', 14);
- %% 7. 验证GDP_Total与第一、第二、第三产业的关系
- % 计算各年份的产业GDP总和
- filledData.Calculated_GDP_Total = filledData.Primary_Industry_Value + ...
- filledData.Secondary_Industry_Value + filledData.Tertiary_Industry_Value;
- % 比较计算的GDP总和与实际GDP_Total
- difference = filledData.GDP_Total - filledData.Calculated_GDP_Total;
- % 显示差异情况
- disp('GDP_Total 与 计算的GDP_Total(第一+第二+第三产业)差异:');
- disp(table(filledData.Year, filledData.GDP_Total, filledData.Calculated_GDP_Total, difference));
- % 统计差异
- sumDifference = sum(abs(difference), 'omitnan');
- disp(['总差异(绝对值): ', num2str(sumDifference)]);
- %% 8. 构建同一产业内的关系模型
- % 定义产业及其内部变量
- industries = {'Primary', 'Secondary', 'Tertiary'};
- internalVars.Primary = {'Agriculture_Value'};
- internalVars.Secondary = {'Other_Manufacturing_Value', 'Chemical_Industry_Value', 'Construction_Value', ...
- 'Metal_Manufacturing_Value', 'Mining_Value', 'Mechanical_Manufacturing_Value', 'Electricity_Supply_Value', 'Textile_Apparel_Value'};
- internalVars.Tertiary = {'IT_Services_Value', 'Finance_Value', 'Food_Beverage_Value', ...
- 'Wholesale_Retail_Hospitality_Value', 'Rent_Business_Services_Value'};
- % 初始化结构体存储模型结果
- models = struct();
- for i = 1:length(industries)
- industry = industries{i};
- GDP_var = [industry, '_Industry_Value'];
- predictors = internalVars.(industry);
- % 构建回归模型公式
- formula = [GDP_var, ' ~ ', strjoin(predictors, ' + ')];
- % 创建回归模型
- tbl = filledData(:, [GDP_var, predictors]);
- % 移除含有缺失值的行
- tbl = rmmissing(tbl);
- % 线性回归
- mdl = fitlm(tbl, formula);
- % 存储模型
- models.(industry) = mdl;
- % 显示模型结果
- disp(['--- ', industry, ' Industry Regression Model ---']);
- disp(mdl);
- end
- %% 9. 输出拟合的回归关系式
- % 打开一个文本文件用于保存回归关系式
- outputFile = '回归关系式输出.txt';
- fid = fopen(outputFile, 'w');
- if fid == -1
- error('无法创建文件 %s。请检查文件路径和权限。', outputFile);
- end
- % 遍历每个产业的模型,提取系数并输出关系式
- for i = 1:length(industries)
- industry = industries{i};
- mdl = models.(industry);
- GDP_var = [industry, '_Industry_Value'];
- predictors = internalVars.(industry);
- % 获取系数
- coeffs = mdl.Coefficients.Estimate;
- intercept = coeffs(1); % 截距
- beta = coeffs(2:end); % 斜率
- % 构建关系式字符串
- equation = sprintf('%s = %.4f', GDP_var, intercept);
- for j = 1:length(beta)
- if beta(j) >= 0
- equation = sprintf('%s + %.4f * %s', equation, beta(j), predictors{j});
- else
- equation = sprintf('%s - %.4f * %s', equation, abs(beta(j)), predictors{j});
- end
- end
- % 打印到命令窗口
- disp(['回归关系式 for ', industry, ' Industry:']);
- disp(equation);
- disp(' ');
- % 写入到文件
- fprintf(fid, '回归关系式 for %s Industry:\n', industry);
- fprintf(fid, '%s\n\n', equation);
- end
- % 关闭文件
- fclose(fid);
- disp(['回归关系式已输出到文件: ', outputFile]);
- %% 10. 结果可视化
- % 绘制各产业回归模型的残差图
- figure('Name', '各产业回归模型残差图', 'NumberTitle', 'off');
- for i = 1:length(industries)
- industry = industries{i};
- mdl = models.(industry);
- subplot(length(industries), 1, i);
- plotResiduals(mdl, 'fitted');
- title([industry, ' Industry Residuals'], 'FontSize', 12);
- end
- sgtitle('各产业回归模型残差图', 'FontSize', 16);
- % 绘制各产业的实际值与预测值对比
- figure('Name', '各产业实际值与拟合值对比', 'NumberTitle', 'off');
- for i = 1:length(industries)
- industry = industries{i};
- mdl = models.(industry);
- GDP_var = [industry, '_Industry_Value'];
- predictors = internalVars.(industry); % 获取当前产业的预测变量
- % 创建回归模型公式
- % 注意:此处假设回归模型已经在前面的代码中正确构建
- % 提取当前产业的GDP和预测变量数据
- currentData = filledData(:, [GDP_var, predictors]);
- % 移除含有缺失值的行
- mask = ~any(ismissing(currentData), 2);
- tbl_clean = currentData(mask, :);
- % 提取对应的年份
- years = filledData.Year(mask);
- % 绘制拟合值与实际值对比
- subplot(length(industries), 1, i);
- plot(years, mdl.Fitted, 'r-', 'LineWidth', 1.5, 'DisplayName', '拟合值');
- hold on;
- plot(years, tbl_clean.(GDP_var), 'b--', 'LineWidth', 1.5, 'DisplayName', '实际值');
- xlabel('年份', 'FontSize', 12);
- ylabel('GDP (亿元)', 'FontSize', 12);
- title([industry, ' Industry: Actual vs Fitted'], 'FontSize', 12);
- legend('Location', 'best');
- grid on;
- hold off;
- end
- sgtitle('各产业实际值与拟合值对比', 'FontSize', 16);
- %% 11 模型评估与解释
- % 对每个模型进行评估
- for i = 1:length(industries)
- industry = industries{i};
- mdl = models.(industry);
- disp(['--- ', industry, ' Industry Model Evaluation ---']);
- % 显示R²
- disp(['R²: ', num2str(mdl.Rsquared.Ordinary)]);
- % 显示调整后的R²
- disp(['Adjusted R²: ', num2str(mdl.Rsquared.Adjusted)]);
- % 显示显著性
- disp(['F-statistic p-value: ', num2str(mdl.Coefficients.pValue(end))]);
- disp(' ');
- end
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。 |






















